Clear Sky Science · he
PS-SNN: למידת הפרדת דפוסים לרשתות נוירונים דוקרות ניתנות להרחבה בלמידה סדרתית לפי מחלקות
מדוע חשוב ללמד מכונות "לזכור"
מערכות בינה מלאכותית מודרניות מרשימות, אך יש להן נקודת עיוורון משמעותית: כשמלמדים אותן דבר חדש הן נוטות לשכוח מה שלמדו קודם. "אמנזיה" זו מהווה מכשול מרכזי לרובוטים, טלפונים ומכשירים אחרים שצריכים להמשיך ללמוד מעולם שמשתנה מבלי לאמן אותם מחדש מאפס. המאמר על PS-SNN מציג דרך בהשראת המוח לסייע לרשתות נוירונים דוקרות חסכוניות באנרגיה ללמוד קטגוריות חדשות לאורך זמן תוך שמירה על הידע הקודם, וכך מצביע על בינה חכמה ואמינה יותר שניתנת להרצה על חומרה צריכת-אנרגיה נמוכה.
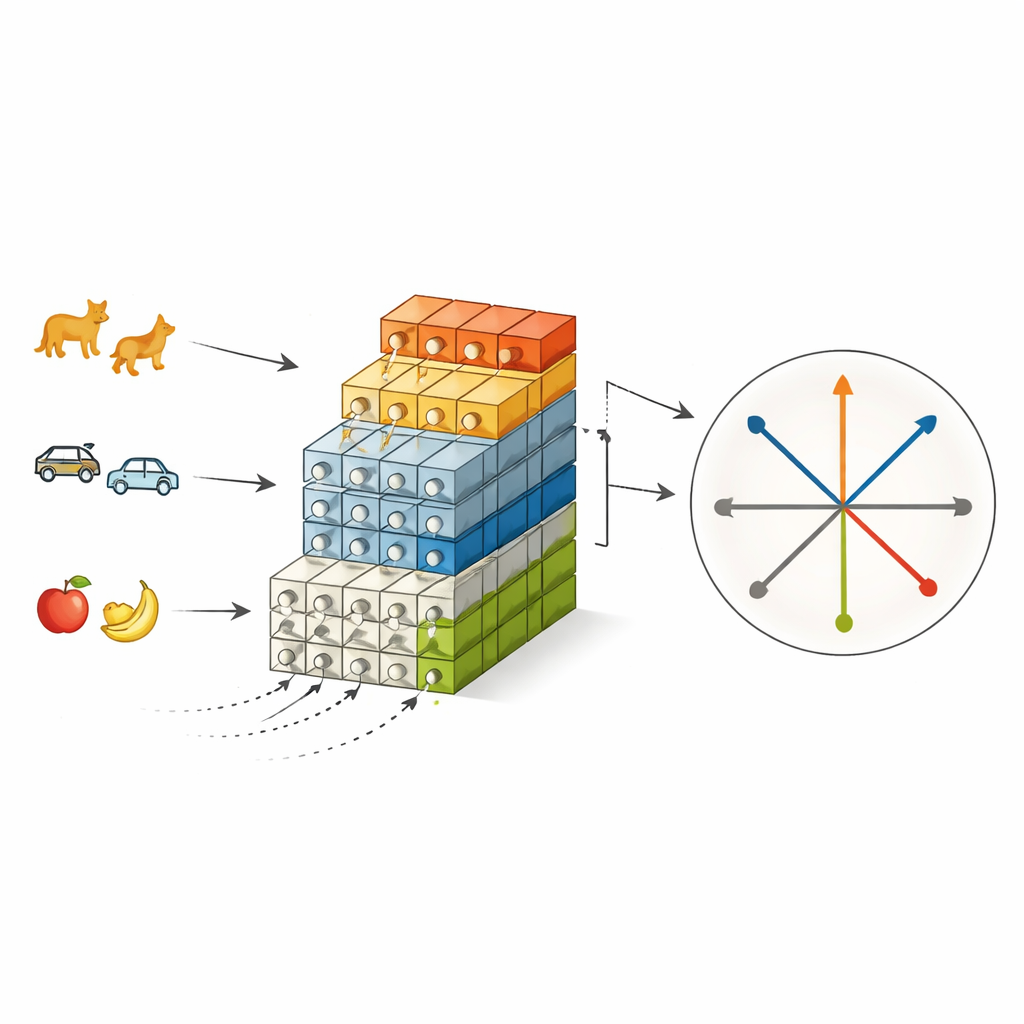
בעיה של שכחה לאורך זמן
רוב מודלי ה-AI מאומנים פעם אחת על מאגר נתונים קבוע ומופעלים אחר כך. במציאות, עם זאת, הנתונים מופיעים בגלים: מצלמה עשויה להיתקל בחודש הבא בסוגי עצמים חדשים שמעולם לא סומנו קודם. כאשר רשת סטנדרטית מעודכנת על הקטגוריות החדשות הללו, "מרחב התכונות" הפנימי שלה משתנה ולעתים קרובות הביצועים על הקטגוריות הקודמות קרסות — תופעה שנקראת שכחה קטастрофית. זה מאתגר במיוחד בלמידה סדרתית לפי מחלקות (class-incremental), שבה המערכת חייבת לזהות את כל הקטגוריות שנראו עד כה מבלי לקבל אינדיקציה איזו תקופת אימון התייחסה לאיזו קטגוריה. רשתות נוירונים דוקרות, שתקשורתן נעשית באמצעות דקירות חשמליות קצרות בדומה לנוירונים ביולוגיים והן מושכות לשבבים חסכוניים באנרגיה, סובלות מאותה הבעיה וקיבלו פחות תשומת לב מאשר רשתות עמוקות קונבנציונליות.
למידה מהתפתחות והפרדה במוח
הנוירוביולוגיה מציעה שתי רעיונות משלימים ללמידה לכל החיים. ראשית, המוח יכול לייצר נוירונים חדשים, במיוחד באזור הנקרא היפוקמפוס, מה שמאפשר לאחסן זיכרונות חדשים מבלי למחוק ישנים. שנית, חלק אחר בהיפוקמפוס, האזור שנקרא דנטייט ג'ירוס (dentate gyrus), נתפס כמפעיל "מפריד דפוסים": גם חוויות דומות ממפות לדפוסי פעילות מובחנים ולא חופפים כדי שלא יתערבו זו בזו. שיטות קיימות של למידה מתמשכת לרשתות דוקרות בדרך כלל מתמקדות בשינוי מבנה הרשת או בשימוש מחדש בנתונים ישנים, אך הן עדיין מסתמכות על שכבות פלט שמאותחלות אקראית, מה שיכול לגרום לייצוגים הפנימיים של קטגוריות להסתחרר ולהתערבב ככל שמשימות חדשות מגיעות. המחברים טוענים שעיצוב הממיין הזה, שנשמט מהשיח, הוא מקור מרכזי לאי-יציבות.
כיצד PS-SNN מעצב מחדש את תהליך הלמידה
PS-SNN משלב את שתי הרעיונות המוחיים הללו בתוך רשת דוקרת שמתוכננת ללמידה סדרתית לפי מחלקות. ככל שמגיעות קבוצות חדשות של קטגוריות, הרשת מתרחבת על ידי הוספת מודולים חדשים לחילוץ תכונות, בעוד שמודולים קודמים מקופאים, מה שמדמה נוירוגנזה ושומר על הידע הקודם. במקביל, במקום ללמוד שכבת פלט חדשה מאפס בכל פעם, השיטה מקצה לכל קטגוריה כיוון מחושב מראש במרחב התכונות. כיוונים אלה נבנים כך שיהיו אורטוגונליים זה לזה, כלומר כל קטגוריה מעוגנת לסלוט מובחן ולא חופף כבר מהתחלה. במהלך שלב האימון הראשון, שנקרא למידת הפרדת דפוסים, הממיין נשמר קבוע ורק חילוצי התכונות מתאימים עצמם, מה שמכריח את הייצוג המבוסס-דקירה של כל קטגוריה להתאסף בצפיפות סביב הכיוון המוקצה ולהקטין קונפליקטים בין משימות ישנות לחדשות.

כיווני כיוונון עדינים בלי לשבור זיכרונות
עוגני כיוונים אורטוגונליים משפרים מאוד את היציבות, אך הם גם נוקשים. כדי להשיב גמישות, PS-SNN מוסיף שלב שני שנקרא למידת עדכון דפוסים. כאן חילוצי התכונות מקופאים ורק הממיין מותאם, באמצעות תערובת מאוזנת בזהירות של דוגמאות ישנות וחדשות כך שלא תגרום של קבוצה אחת של קטגוריות להשתלט. שלב זה מעצב בעדינות את גבולות ההחלטה בין כיווני הקטגוריות שכבר הופרדו היטב, ומשפר את ההבחנה — במיוחד בקטגוריות דומות חזותית — מבלי להפריע לייצוגים הבסיסיים שהוצבו בשלב הראשון. המערכת שומרת גם זיכרון שיחזור קטן של דגימות עבר, שעוזר לכוון את שני השלבים תוך שמירה על נפח אחסון צנוע.
מה המשמעות של התוצאות עבור עתיד ה-AI
נבדק על קריטריונים סטנדרטיים של תמונות שבהם הקטגוריות מגיעות במספר שלבים, PS-SNN מדגים ביצועים טובים משמעותית לעומת שיטות למידה מתמשכת מבוססות-דקירות קודמות ואף מתחרה או עוקף מספר רשתות עמוקות קונבנציונליות מובילות, וכל זאת תוך שמירה על היתרונות של חישוב מבוסס-דקירות מבחינת חיסכון באנרגיה. על ידי שילוב מבנה רשת הניתן להרחבה עם עוגנים קבועים ומופרדים היטב לכל קטגוריה, הגישה מקטינה באופן ניכר את הסטייה האיטית של הייצוגים הפנימיים שבדרך כלל פוגעת בלמידה לטווח ארוך. עבור קהל שאינו מומחה, המסקנה היא שעבודה זו מקרבת את ה-AI ליכולת של המוח להמשיך ללמוד מבלי לשכוח, בצורה שניתן להפעיל ביעילות על שבבי נוירומורפיים עתידיים המוטמעים במכשירים יומיומיים.
ציטוט: Hu, K., Wen, L., Zhang, T. et al. PS-SNN: pattern separation learning for expandable spiking neural networks in class-incremental learning. Sci Rep 16, 12653 (2026). https://doi.org/10.1038/s41598-026-42970-6
מילות מפתח: למידה מתמשכת, רשתות נוירונים דוקרות, שכחה קטастрофית, חישוב נוירומורפי, הפרדת דפוסים