Clear Sky Science · nl
Verbetering van plantziekteclassificatie met een aandacht-gebaseerde CNN voor intra-dataset- en cross-dataset-training
Waarom het signaleren van zieke bladeren belangrijk is
Voedselgewassen zoals maïs en aardappelen voeden honderden miljoenen mensen, maar bladaandoeningen kunnen opbrengsten langzaam aantasten nog voordat boeren zichtbare schade opmerken. Tegenwoordig maken smartphones en goedkope camera’s het eenvoudig om foto’s van gewassen te verzamelen, maar die beelden betrouwbaar omzetten in vroege waarschuwingen blijft lastig. Deze studie onderzoekt hoe een slimmer type beeldherkenningssysteem kan leren plantenziekten te detecteren, niet alleen in nette laboratoriumfoto’s, maar ook in rommelige praktijkbeelden die in velden zijn genomen onder wisselende licht- en achtergrondomstandigheden.
Computers leren bladeren ‘lezen’
Moderne beeldherkenningssystemen leunen vaak op convolutionele neurale netwerken, of CNN’s, die uitblinken in het vinden van patronen in afbeeldingen—randen, vlekken, vormen en texturen. Deze technieken hebben al aangetoond dat ze plantenziekten met indrukwekkende nauwkeurigheid kunnen classificeren wanneer ze zijn getraind en getest op dezelfde zorgvuldig samengestelde dataset. Het merendeel van eerder werk richtte zich echter op wat de auteurs „intra-dataset” training noemen: het model oefent en doet zijn examen op zeer vergelijkbare afbeeldingen. Wanneer zo’n model bladeren ontmoet die met een andere camera zijn gefotografeerd, in een ander land, of tegen een rommelige achtergrond, kan de prestatie sterk dalen.
Het model helpen aandacht te geven
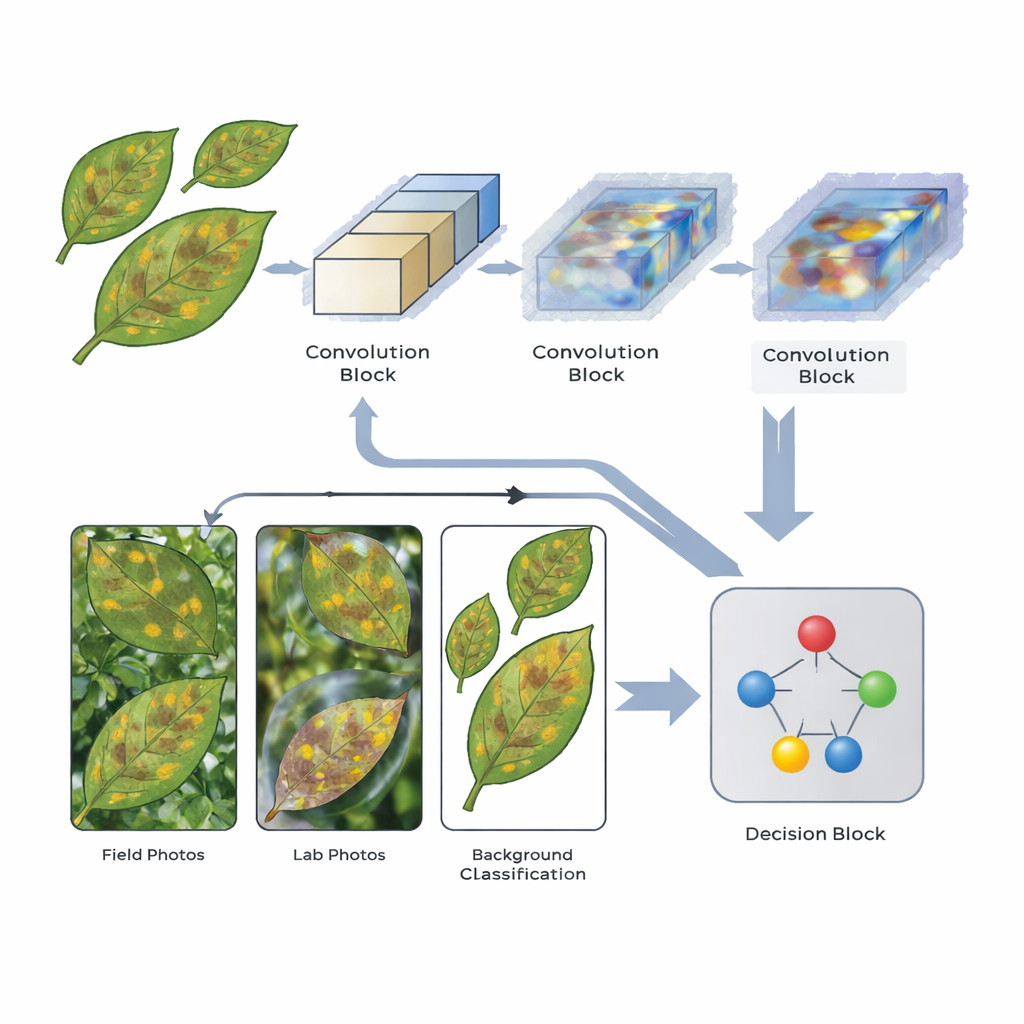
De onderzoekers ontwierpen een gestroomlijnde CNN die speciale aandachtmechanismen bevat—componenten die het netwerk helpen zich te concentreren op de meest informatieve delen van elke afbeelding. Het model verwerkt elke bladfoto via drie fasen van feature-extractie. Na de tweede en derde fase wegen aandachtlagen de interne signalen opnieuw zodat patronen die verband houden met ziektevlekken en letsels benadrukt worden, terwijl minder relevante details, zoals achtergrondgrond of lucht, worden afgezwakt. De architectuur is bewust lichtgewicht, met gematigde afbeeldingsgroottes en beperkte diepte zodat hij op relatief bescheiden hardware kan draaien—een praktische overweging voor gebruik in de landbouwpraktijk.
Testen op veel verschillende bladfoto’s
Om te beoordelen hoe goed dit ontwerp standhoudt, maakte het team gebruik van vijf publiek toegankelijke bladbeeldverzamelingen. Deze omvatten de veelgebruikte PlantVillage-dataset met schone, gecentreerde bladeren; PlantDoc, met realistischer veldfoto’s; Digipathos en een NLB-set gericht op een specifieke maïsziekte; en de Corn Disease & Severity (CD&S)-dataset, die meerdere versies van elke afbeelding biedt: originele veldopnamen, bladeren waarvan de achtergrond is verwijderd, en bladeren geplaatst op uniforme zwarte of witte achtergronden. Het model leerde meerdere ziektes van maïs en aardappel te herkennen, evenals gezonde bladeren, en de prestaties werden geëvalueerd met gangbare maatstaven zoals nauwkeurigheid, precisie en recall.
Sterke resultaten thuis en in het buitenland
Wanneer het netwerk binnen dezelfde dataset werd getraind en getest, overtrof of evenaarde de aandacht-gebaseerde netwerk veel eerdere methoden. Het bereikte 98% nauwkeurigheid voor maïsziekteclassificatie en 99,38% nauwkeurigheid voor aardappelziekteclassificatie op de PlantVillage-afbeeldingen, en 98% nauwkeurigheid op de CD&S-veldafbeeldingen. Meer veeleisende experimenten vroegen het model te trainen op één dataset en vervolgens ziektes in een andere te classificeren—een “cross-dataset” uitdaging die dichter bij echte uitrol staat. Hier werden de beste resultaten behaald wanneer het systeem was getraind op CD&S-afbeeldingen waarvan de achtergrond was verwijderd. Onder deze instelling behaalde het een gemiddelde nauwkeurigheid van ongeveer 82,93% over verschillende andere maïsdatasets, waarmee het eerdere cross-dataset-studies verbeterde. Het model was minder consistent voor aardappelbeelden over datasets heen, maar leverde toch een eerste referentiepunt voor die taak.
Wat dit betekent voor slimmer boeren
Voor niet-specialisten is de kernboodschap dat de manier waarop we detectiesystemen trainen even belangrijk is als de gebruikte algoritmen. Door het netwerk te helpen zich te richten op de werkelijke symptomen op bladeren in plaats van op de omgeving, maken aandachtmechanismen het systeem beter in het omgaan met nieuwe soorten afbeeldingen. Hoewel de studie opmerkt dat publieke datasets nog niet de volledige rommeligheid van echte boerderijen vangen, laten de resultaten zien dat een relatief compact model beter kan generaliseren over verschillende afbeeldingsverzamelingen. Op de lange termijn zouden zulke hulpmiddelen telefoongebaseerde of dronegebaseerde scouts kunnen ondersteunen die boeren waarschuwen voor opkomende problemen voordat ze zich verspreiden, wat bijdraagt aan preciezer, minder verspild gebruik van chemicaliën en betere bescherming van de wereldwijde voedselvoorziening.
Bronvermelding: Mahapatra, P., Panda, M., Dash, S.K. et al. Advancing plant disease classification using an attention-based CNN for intra-dataset and cross- dataset training. Sci Rep 16, 10925 (2026). https://doi.org/10.1038/s41598-026-45464-7
Trefwoorden: detectie van plantenziekten, deep learning, attention CNN, monitoring van gewasgezondheid, cross-dataset generalisatie