Clear Sky Science · de
Weiterentwicklung der Klassifizierung von Pflanzenkrankheiten mittels auf Aufmerksamkeit basierendem CNN für intra-dataset- und cross-dataset-Training
Warum das Erkennen kranker Blätter wichtig ist
Lebensmittelkulturen wie Mais und Kartoffeln ernähren hunderte Millionen Menschen, dennoch können Blattkrankheiten die Erträge lange unbemerkt schrittweise verringern, bevor Landwirtinnen und Landwirte sichtbaren Schaden bemerken. Heute erleichtern Smartphones und preiswerte Kameras das Sammeln von Pflanzenbildern, doch diese Bilder in verlässliche Frühwarnungen zu verwandeln, bleibt schwierig. Diese Studie untersucht, wie eine intelligentere Form der Bilderkennung lernen kann, Pflanzenkrankheiten nicht nur in ordentlichen Laborfotos, sondern auch in unordentlichen Feldaufnahmen unter wechselnden Licht- und Hintergrundbedingungen zu erkennen.
Computern das Lesen von Blättern beibringen
Moderne Bilderkennungssysteme beruhen oft auf Convolutional Neural Networks (CNNs), die sehr gut darin sind, Muster in Bildern zu finden – Kanten, Flecken, Formen und Texturen. Diese Werkzeuge haben bereits gezeigt, dass sie Pflanzenkrankheiten mit beeindruckender Genauigkeit klassifizieren können, wenn sie auf demselben sorgfältig zusammenstellten Dataset trainiert und getestet werden. Die meisten früheren Arbeiten konzentrierten sich jedoch auf das, was die Autoren „intra-dataset“-Training nennen: das Modell übt und macht seine Prüfung an sehr ähnlichen Bildern. Trifft ein solches Modell auf Blätter, die mit einer anderen Kamera, in einem anderen Land oder vor einem unruhigen Hintergrund fotografiert wurden, kann seine Leistung deutlich abfallen.
Dem Modell helfen, aufzupassen
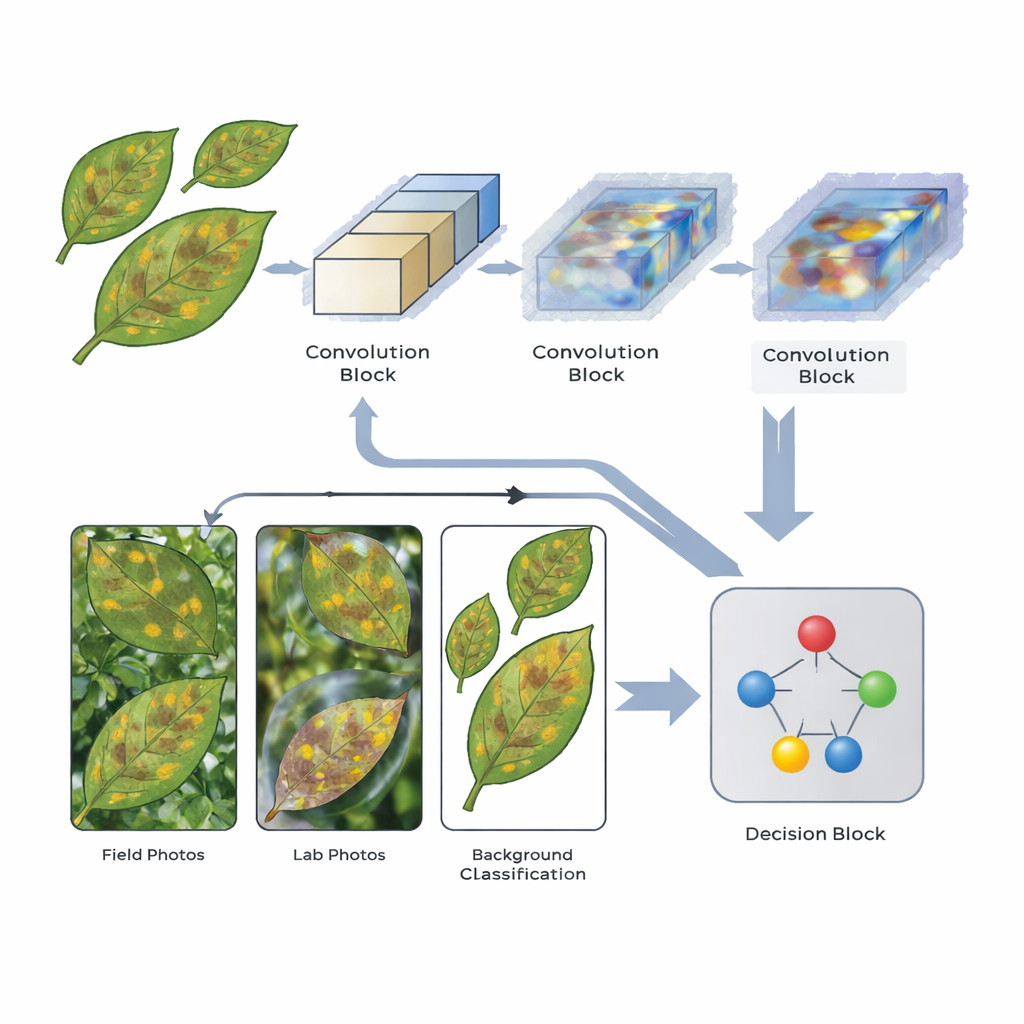
Die Forscher entwickelten ein schlankes CNN, das spezielle Aufmerksamkeitsmechanismen enthält – Komponenten, die dem Netzwerk helfen, sich auf die informativsten Bereiche eines Bildes zu konzentrieren. Das Modell verarbeitet jedes Blattbild in drei Feature-Extraktionsstufen. Nach der zweiten und dritten Stufe gewichten Attention-Schichten die internen Signale neu, sodass Muster, die mit Krankheitsflecken und Läsionen verbunden sind, hervorgehoben werden, während weniger relevante Details wie Boden oder Himmel im Hintergrund abgeschwächt werden. Die Architektur ist bewusst leichtgewichtig gehalten, verwendet moderate Bildgrößen und begrenzte Tiefe, sodass sie auf relativ bescheidener Hardware laufen kann – ein praktischer Gesichtspunkt für den Einsatz in der Landwirtschaft.
Tests mit vielen Arten von Blattfotos
Um zu prüfen, wie robust dieses Design ist, griff das Team auf fünf öffentlich verfügbare Blattbildsammlungen zurück. Dazu gehörte das weit verbreitete PlantVillage-Dataset mit sauberen, zentrierten Blättern; PlantDoc, das realistischere Feldaufnahmen enthält; Digipathos und ein NLB-Set, das sich auf eine spezifische Maiskrankheit konzentriert; sowie das Corn Disease & Severity (CD&S)-Dataset, das mehrere Versionen jedes Bildes anbietet: originale Feldaufnahmen, Hintergrund-entfernte Blätter sowie Blätter auf einheitlichem schwarzem oder weißem Hintergrund. Das Modell lernte, mehrere für Mais und Kartoffeln relevante Krankheiten sowie gesunde Blätter zu erkennen, und seine Leistung wurde mit Standardmaßen wie Genauigkeit, Precision und Recall bewertet.
Starke Ergebnisse zuhause und im Ausland
Beim Training und Testen innerhalb desselben Datensatzes entsprach das auf Aufmerksamkeit basierende Netzwerk vielen früheren Methoden oder übertraf sie. Es erreichte 98 % Genauigkeit bei der Klassifizierung von Maiskrankheiten und 99,38 % Genauigkeit bei der Klassifizierung von Kartoffelkrankheiten auf den PlantVillage-Bildern sowie 98 % Genauigkeit auf den CD&S-Feldaufnahmen. Anspruchsvollere Experimente verlangten vom Modell, auf einem Datensatz zu trainieren und Krankheiten in einem anderen zu klassifizieren – eine „cross-dataset“-Herausforderung, die dem realen Einsatz näherkommt. Hier erzielte das beste Ergebnis, wenn das System auf CD&S-Bildern trainiert wurde, deren Hintergründe entfernt worden waren. Unter dieser Bedingung erreichte es eine durchschnittliche Genauigkeit von etwa 82,93 % über mehrere andere Mais-Datensätze hinweg und verbesserte damit frühere cross-dataset-Studien. Bei Kartoffelbildern über Datensätze hinweg war das Modell weniger konsistent, lieferte jedoch dennoch einen ersten Benchmark für diese Aufgabe.
Was das für intelligentere Landwirtschaft bedeutet
Für Nicht-Spezialisten lautet die zentrale Botschaft, dass die Art des Trainings von Systemen zur Krankheitserkennung ebenso wichtig ist wie die angewandten Algorithmen. Indem sie dem Netzwerk helfen, sich auf die eigentlichen Symptome auf Blättern statt auf die Umgebung zu konzentrieren, machen Aufmerksamkeitsmechanismen das System besser in die Lage, mit neuen Bildarten umzugehen. Die Studie weist zwar darauf hin, dass öffentliche Datensätze immer noch nicht die volle Unordnung realer Höfe abbilden, doch zeigen die Ergebnisse, dass ein vergleichsweise kompaktes Modell über verschiedene Bildsammlungen besser generalisieren kann. Langfristig könnten solche Werkzeuge telefon- oder drohnengestützte Inspektionen unterstützen, die Landwirtinnen und Landwirte vor aufkommenden Problemen warnen, bevor sie sich ausbreiten, und so zu präziserem, weniger verschwenderischem Chemikalieneinsatz und besserem Schutz der globalen Nahrungsmittelversorgung beitragen.
Zitation: Mahapatra, P., Panda, M., Dash, S.K. et al. Advancing plant disease classification using an attention-based CNN for intra-dataset and cross- dataset training. Sci Rep 16, 10925 (2026). https://doi.org/10.1038/s41598-026-45464-7
Schlüsselwörter: Erkennung von Pflanzenkrankheiten, Deep Learning, Attention-CNN, Überwachung des Pflanzenzustands, Cross-Dataset-Generalisation