Clear Sky Science · it
Migliorare la classificazione delle malattie delle piante usando una CNN con attenzione per l’addestramento intra-dataset e cross-dataset
Perché individuare le foglie malate è importante
Colture alimentari come mais e patate sfamano centinaia di milioni di persone, eppure le malattie fogliari possono erodere le rese molto prima che gli agricoltori notino danni visibili. Oggi gli smartphone e le fotocamere economiche rendono semplice raccogliere immagini delle colture, ma trasformare quelle foto in avvisi precoci affidabili rimane difficile. Questo studio esplora come un sistema di riconoscimento delle immagini più intelligente possa imparare a rilevare le malattie delle piante non solo in foto ordinate da laboratorio, ma anche in immagini reali e disordinate scattate nei campi con condizioni di luce e sfondi variabili.
Insegnare ai computer a leggere le foglie
I moderni sistemi di riconoscimento delle immagini spesso si basano su reti neurali convoluzionali, o CNN, che eccellono nell’individuare pattern nelle immagini: bordi, macchie, forme e texture. Questi strumenti hanno già dimostrato di poter classificare le malattie delle piante con precisioni impressionanti quando vengono addestrati e testati sullo stesso dataset accuratamente curato. Tuttavia, la maggior parte dei lavori precedenti si è concentrata su quello che gli autori chiamano addestramento “intra-dataset”: il modello si esercita e sostiene l’esame su immagini molto simili. Quando un tale modello incontra foglie fotografate con una diversa fotocamera, in un altro paese o su uno sfondo affollato, le sue prestazioni possono diminuire drasticamente.
Aiutare il modello a prestare attenzione
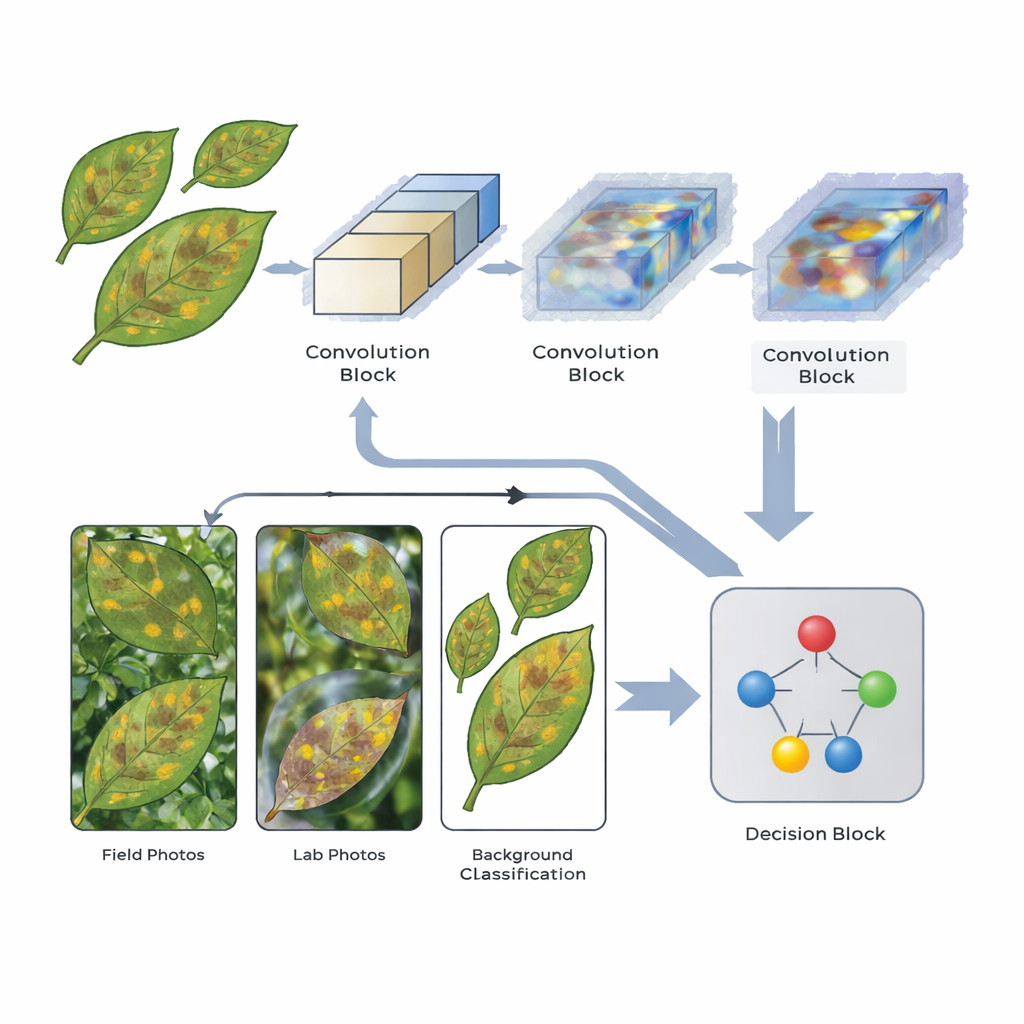
I ricercatori hanno progettato una CNN snella che include meccanismi di attenzione speciali—componenti che aiutano la rete a concentrarsi sulle parti più informative di ciascuna immagine. Il modello elabora ogni foto di foglia attraverso tre fasi di estrazione delle caratteristiche. Dopo la seconda e la terza fase, strati di attenzione ripesano i segnali interni in modo che i pattern collegati a macchie e lesioni siano enfatizzati mentre dettagli meno rilevanti, come il terreno o il cielo sullo sfondo, vengano attenuati. L’architettura è intenzionalmente leggera, usando dimensioni moderate delle immagini e una profondità limitata affinché possa girare su hardware relativamente modesto, una considerazione pratica per l’uso agricolo nel mondo reale.
Test su molti tipi di foto di foglie
Per valutare la robustezza del progetto, il team ha sfruttato cinque collezioni di immagini di foglie disponibili pubblicamente. Queste comprendevano l’ampio dataset PlantVillage di foglie pulite e centrate; PlantDoc, che contiene foto di campo più realistiche; Digipathos e un set NLB focalizzato su una malattia specifica del mais; e il dataset Corn Disease & Severity (CD&S), che offre più versioni di ciascuna immagine: scatti originali di campo, foglie con sfondo rimosso e foglie posizionate su sfondi uniformi neri o bianchi. Il modello ha imparato a riconoscere diverse malattie che colpiscono mais e patate, oltre alle foglie sane, e le sue prestazioni sono state valutate con misure standard come accuratezza, precisione e richiamo.
Risultati solidi in patria e all’estero
Quando addestrata e testata all’interno dello stesso dataset, la rete con attenzione ha eguagliato o superato molti metodi precedenti. Ha raggiunto il 98% di accuratezza per la classificazione delle malattie del mais e il 99,38% di accuratezza per la classificazione delle malattie della patata sulle immagini PlantVillage, e il 98% di accuratezza sulle immagini di campo del CD&S. Esperimenti più impegnativi hanno chiesto al modello di addestrarsi su un dataset e poi classificare le malattie in un altro—una sfida “cross-dataset” più vicina al dispiegamento reale. Qui, i migliori risultati si sono ottenuti quando il sistema è stato addestrato su immagini CD&S con sfondo rimosso. In questo setting ha raggiunto un’accuratezza media di circa il 82,93% su diversi altri dataset di mais, migliorando rispetto a studi cross-dataset precedenti. Il modello è risultato meno consistente per le immagini di patate tra dataset diversi, ma ha comunque fornito un primo punto di riferimento per quel compito.
Cosa significa per un’agricoltura più intelligente
Per i non specialisti, il messaggio centrale è che il modo in cui addestriamo i sistemi di rilevamento delle malattie conta tanto quanto gli algoritmi che usiamo. Aiutando la rete a concentrarsi sui sintomi effettivi sulle foglie anziché sul paesaggio circostante, i meccanismi di attenzione rendono il sistema più capace di gestire nuovi tipi di immagini. Pur riconoscendo che i dataset pubblici non catturano ancora tutta la disordinata variabilità delle aziende agricole reali, i risultati mostrano che un modello relativamente compatto può generalizzare meglio tra diverse raccolte di immagini. Nel lungo periodo, tali strumenti potrebbero supportare operatori su smartphone o droni che avvisano gli agricoltori di problemi emergenti prima che si diffondano, contribuendo a un uso più mirato e meno sprecone di prodotti chimici e a una migliore protezione delle risorse alimentari globali.
Citazione: Mahapatra, P., Panda, M., Dash, S.K. et al. Advancing plant disease classification using an attention-based CNN for intra-dataset and cross- dataset training. Sci Rep 16, 10925 (2026). https://doi.org/10.1038/s41598-026-45464-7
Parole chiave: rilevamento delle malattie delle piante, apprendimento profondo, CNN con attenzione, monitoraggio della salute delle colture, generalizzazione cross-dataset