Clear Sky Science · nl
Geoptimaliseerde ontbinding en deep learning met biascorrectie voor betrouwbare punt- en intervalvoorspelling van afvoer
Waarom slimere rivierprognoses ertoe doen
Gemeenschappen langs grote rivieren zoals de Yangtze leven voortdurend tussen te veel en te weinig water. Plotselinge overstromingen kunnen levens en infrastructuur bedreigen, terwijl langdurige droogte de drinkwatervoorziening, landbouw en waterkracht in gevaar brengt. Deze studie presenteert een nieuwe manier om maanden vooruit te voorspellen hoeveel water er door de Yangtze stroomt, niet alleen als een enkele beste schatting maar ook met een duidelijk beeld van hoe onzeker die schatting is — informatie die planners kan helpen zich voor te bereiden op zowel alledaagse omstandigheden als zeldzame extremen.
Een rusteloos riviersignaal temmen
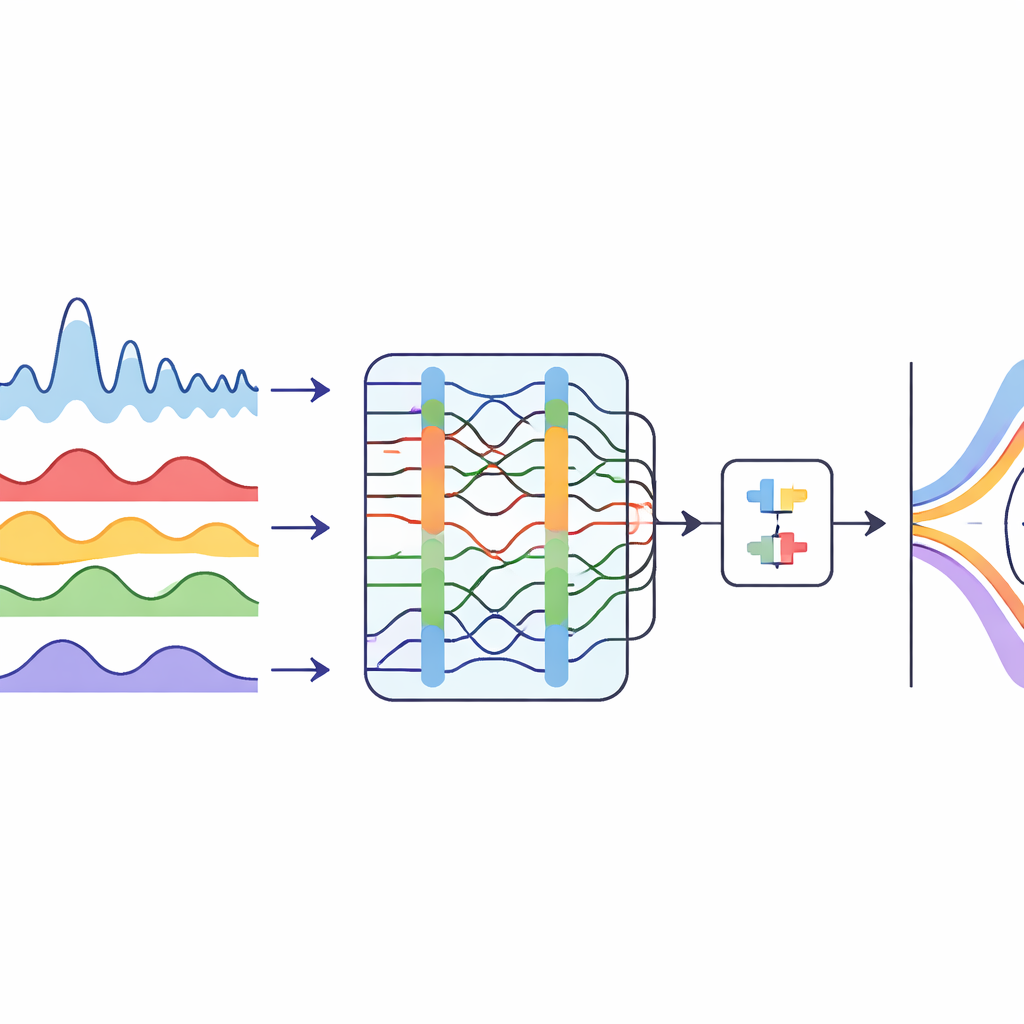
Rivierafvoer stijgt en daalt in complexe patronen die worden gevormd door moessonregens, dammen, landgebruik en klimaatverandering. Deze op- en neergangen maken de gegevens “ruisachtig” en onregelmatig, wat zelfs geavanceerde computermodellen kan verwarren. De auteurs pakken dit eerst aan door het maandelijkse afvoerverloop van twee Yangtze-stations in meerdere soepelere componenten te ontleden. Ze gebruiken een techniek die een verward signaal in schonere bouwstenen scheidt en laten vervolgens een optimalisatie-algoritme, geïnspireerd op de jachtgedragingen van bultruggen, automatisch bepalen hoeveel componenten te gebruiken en hoe sterk elke component gesmoord moet worden. Het resultaat is een set stabielere stroompatronen die makkelijker zijn voor een leersysteem om te begrijpen.
Machines leren de rivier te lezen
Nadat het afvoerverloop is ontleed, richt de studie zich op een hybride deep learning-model om de toekomstige afvoer te voorspellen. Een deel van het model, een temporeel convolutioneel netwerk, is goed in het herkennen van langetermijnpatronen en seizoensritmes in een tijdreeks. Een ander deel, een bidirectioneel recurrent netwerk, kijkt zowel terug als vooruit in de tijd om beter te begrijpen hoe voorgaande maanden de volgende beïnvloeden. De walvis-geïnspireerde optimizer stemt ook belangrijke ontwerpinstellingen van dit gecombineerde model af, zoals het aantal filters dat wordt gebruikt en de leersnelheid. Deze zorgvuldige afstemming stelt het systeem in staat veel nauwkeurigere prognoses voor één maand vooruit te maken dan een reeks concurrerende methoden, waaronder meer traditionele neurale netwerken en op transformers gebaseerde sequentiemodellen.
Verborgen bias in voorspellingen corrigeren
Zelfs wanneer de gemiddelde fouten klein zijn, kan een model nog steeds subtiele, terugkerende fouten vertonen — bijvoorbeeld het consequent onderschatten van grote overstromingen. Om deze verborgen biases te corrigeren voegen de auteurs een tweede leerstap toe. Eerst produceert het model een initiële voorspelling uit de ontlede signalen. Vervolgens berekenen ze het verschil tussen deze voorspelling en de werkelijk waargenomen afvoeren en trainen ze hetzelfde type netwerk om deze resterende fouten te voorspellen. Door de voorspelde fouten weer bij de initiële voorspelling op te tellen, verkrijgen ze een biasgecorrigeerd resultaat. Bij beide Yangtze-stations reduceert deze strategie de standaardfout van voorspellingen met ongeveer twee derde vergeleken met hetzelfde model zonder biascorrectie, en volgt het de pieken in het overstromingsseizoen veel nauwkeuriger.
Van één lijn naar een reeks mogelijkheden
Voor beslissingen in de echte wereld is het kennen van slechts één “beste” voorspelling niet voldoende; managers moeten het bereik van mogelijke afvoeren begrijpen dat plausibel blijft. De studie gaat daarom verder dan puntvoorspellingen en schat voorspellingsintervallen — banden die de werkelijke afvoer een gekozen percentage van de tijd zouden moeten bevatten. In plaats van uit te gaan van een eenvoudige klokvormige foutverdeling, schatten de auteurs de foutverdeling rechtstreeks uit de gegevens met een flexibele methode die de waargenomen residualen gladstrijkt. Deze niet-parametrische benadering vangt scheve en zwaarstaartige verdelingen beter op, wat belangrijk is voor extremen. Met behulp van deze aangepaste foutverdelingen construeren ze afvoerintervallen bij verschillende betrouwbaarheidsniveaus en tonen aan dat hun methode consequent de waargenomen afvoeren betrouwbaarder dekt, en toch relatief smalle banden oplevert, dan standaard statistische verdelingen.
Wat dit betekent voor mensen en planning
In eenvoudige bewoordingen levert de studie een voorspellingsinstrument dat zowel scherper is als eerlijker over zijn onzekerheid. Door het afvoerverloop te zuiveren, een geoptimaliseerde deep learning-motor te gebruiken, systematische fouten te corrigeren en vervolgens data-gedreven onzekerheidsbanden te bouwen, geeft het raamwerk waterbeheerders langs de Yangtze een duidelijker beeld van wat te verwachten is en hoe zeker we daarover kunnen zijn. Hoewel de methode rekenkundig intensief is en nog getest moet worden in andere rivierbekkens, wijst het op een nieuwe generatie rivierprognoses die beter kunnen sturen bij dambeheer, overstromingswaarschuwingen en langetermijn waterplanning in een veranderend klimaat.
Bronvermelding: Ma, H., Marsani, M.F., Mansor, M.A. et al. Optimized decomposition and deep learning with bias correction for reliable runoff point-interval prediction. Sci Rep 16, 9616 (2026). https://doi.org/10.1038/s41598-025-33713-0
Trefwoorden: overstromingsvoorspelling, rivierafvoer, deep learning, onzekerheidsinschatting, Yangtze-rivier