Clear Sky Science · de
Optimierte Zerlegung und Deep Learning mit Bias-Korrektur für verlässliche Punkt- und Intervallschätzungen des Abflusses
Warum intelligentere Flussprognosen wichtig sind
Gemeinden entlang großer Flüsse wie des Jangtsekiang leben in ständiger Spannung zwischen zu viel und zu wenig Wasser. Plötzliche Überschwemmungen können Menschenleben und Infrastruktur gefährden, während langanhaltende Trockenperioden die Trinkwasserversorgung, Landwirtschaft und Wasserkraft bedrohen. Diese Studie stellt einen neuen Ansatz zur Vorhersage des Abflusses im Jangtsekiang über Monate im Voraus vor — nicht nur als einzelne beste Schätzung, sondern auch mit einer klaren Einschätzung der dabei bestehenden Unsicherheit. Diese Informationen können Planern helfen, sowohl für alltägliche Verhältnisse als auch für seltene Extremereignisse besser vorzusorgen.
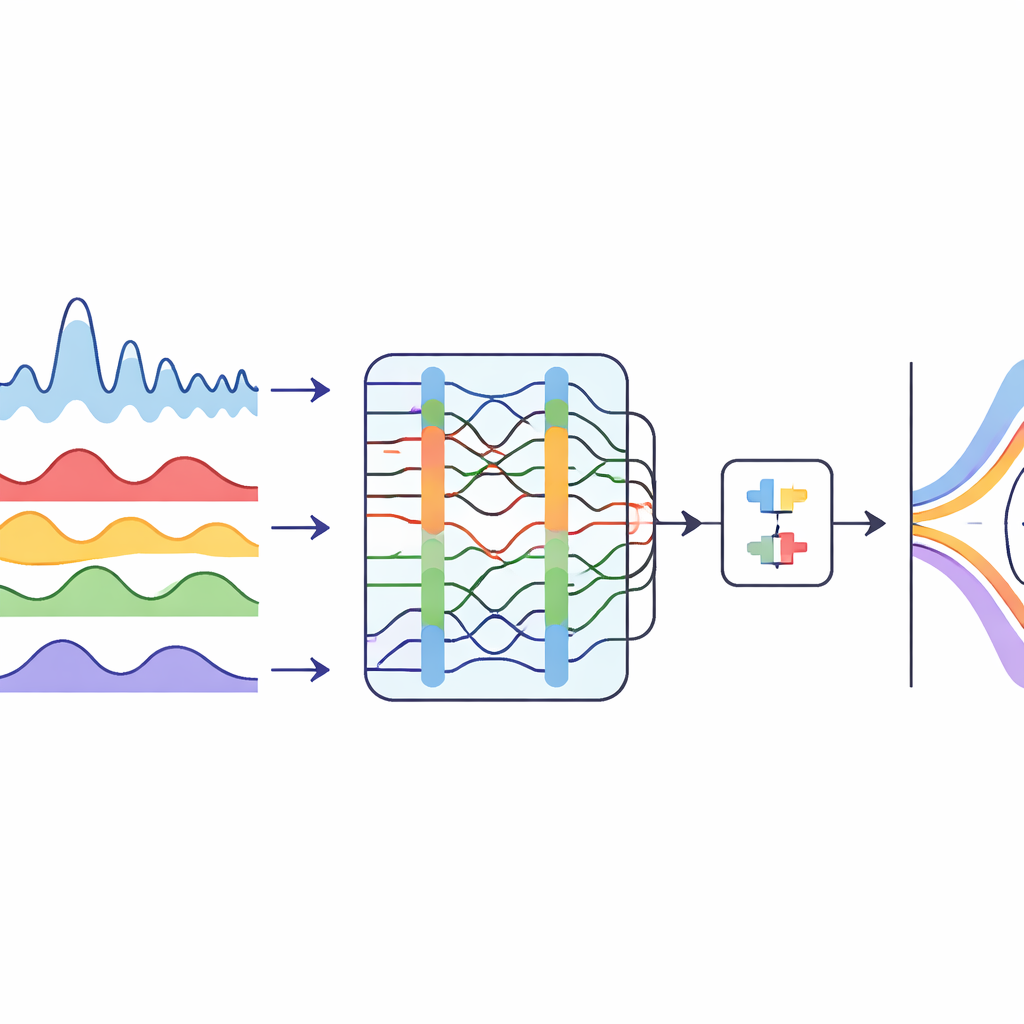
Ein unruhiges Flusssignal beherrschen
Der Flussabfluss steigt und fällt in komplexen Mustern, geformt von Monsunregen, Staudämmen, Landnutzung und Klimawandel. Diese Schwankungen machen die Daten „rauschhaft“ und unregelmäßig, was selbst fortgeschrittene Computermodelle verwirren kann. Die Autor:innen gehen das Problem zunächst an, indem sie die monatlichen Abflussreihen zweier Jangtse-Stationen in mehrere glattere Komponenten zerlegen. Sie verwenden eine Technik, die ein verschlungenes Signal in sauberere Bausteine trennt, und lassen dann einen Optimierungsalgorithmus, inspiriert vom Jagdverhalten von Buckelwalen, automatisch entscheiden, wie viele Komponenten zu verwenden sind und wie stark jede einzelne geglättet werden soll. Das Ergebnis ist eine Reihe stabilerer Abflussmuster, die ein Lernsystem leichter erfassen kann.
Maschinen beibringen, den Fluss zu lesen
Sobald die Abflussreihe zerlegt ist, wendet sich die Studie einem hybriden Deep-Learning-Modell zur Vorhersage des zukünftigen Abflusses zu. Ein Teil des Modells, ein temporales Konvolutionsnetzwerk, ist gut darin, langfristige Muster und saisonale Rhythmen in einer Sequenz zu erkennen. Ein anderer Teil, ein bidirektionales rekurrentes Netzwerk, schaut sowohl zurück als auch vorwärts entlang der Zeitachse, um besser zu erfassen, wie vergangene Monate den nächsten beeinflussen. Der walbasierte Optimierer justiert auch zentrale Gestaltungsparameter dieses kombinierten Modells, etwa wie viele Filter zum Einsatz kommen und wie schnell es lernt. Diese sorgfältige Abstimmung ermöglicht dem System deutlich genauere Ein-Monat-Vorhersagen als eine Reihe konkurrierender Methoden, darunter traditionellere neuronale Netze und transformerbasierte Sequenzmodelle.
Versteckte Verzerrungen in Vorhersagen beheben
Selbst wenn durchschnittliche Fehler klein sind, kann ein Modell weiterhin subtile, wiederkehrende Fehler zeigen — etwa das regelmäßige Unterschätzen großer Hochwasser. Um diese versteckten Verzerrungen zu korrigieren, fügen die Autor:innen einen zweiten Lernschritt hinzu. Zuerst erzeugt das Modell aus den zerlegten Signalen eine erste Vorhersage. Dann berechnen sie die Differenz zwischen dieser Vorhersage und den tatsächlich beobachteten Abflüssen und trainieren denselben Netztyp darauf, diese verbleibenden Fehler vorherzusagen. Indem die prognostizierten Fehler wieder zur Erstvorhersage addiert werden, entsteht ein bias-korrigiertes Ergebnis. An beiden Jangtse-Stationen reduziert diese Strategie die Standardfehler der Vorhersagen im Vergleich zum gleichen Modell ohne Bias-Korrektur um etwa zwei Drittel und erfasst die Gipfel der Hochwasserzeit deutlich genauer.
Von einer einzelnen Linie zu einem Spektrum möglicher Szenarien
Für Entscheidungen in der Praxis reicht eine einzelne „beste“ Vorhersage nicht aus; Verantwortliche müssen das Spektrum der noch plausiblen Abflüsse verstehen. Die Studie geht daher über Punktprognosen hinaus und schätzt Vorhersageintervalle — Bänder, die den wahren Abfluss mit einer gewählten Wahrscheinlichkeit einschließen sollten. Statt von einem einfachen glockenförmigen Fehlerverhalten auszugehen, schätzen die Autor:innen die Fehlerverteilung direkt aus den Daten mit einer flexiblen Methode, die die beobachteten Residuen glättet. Dieser nichtparametrische Ansatz erfasst besser schiefe und schwerere Verteilungen, was für Extremereignisse wichtig ist. Mit diesen angepassten Fehlerverteilungen konstruieren sie Abflussintervalle für verschiedene Konfidenzniveaus und zeigen, dass ihre Methode die beobachteten Abflüsse beständiger abdeckt — und das mit vergleichsweise schmalen Bändern — im Vergleich zu Standardstatistikverteilungen.
Was das für Menschen und Planung bedeutet
Einfach gesagt liefert die Studie ein Prognosewerkzeug, das sowohl schärfer ist als auch ehrlicher hinsichtlich seiner Unsicherheit. Durch die Bereinigung der Abflussreihe, den Einsatz eines optimierten Deep-Learning-Kerns, die Korrektur systematischer Fehler und den Aufbau datengetriebener Unsicherheitsbänder gibt das Rahmenwerk Wasserverwaltern am Jangtse ein klareres Bild dessen, was zu erwarten ist und wie sicher diese Erwartungen sind. Zwar ist die Methode rechenintensiv und muss noch in anderen Flusseinzugsgebieten getestet werden, doch sie weist auf eine neue Generation von Flussprognosen hin, die Staudambetrieb, Hochwasserwarnungen und langfristige Wasserplanung in einem sich wandelnden Klima besser unterstützen kann.
Zitation: Ma, H., Marsani, M.F., Mansor, M.A. et al. Optimized decomposition and deep learning with bias correction for reliable runoff point-interval prediction. Sci Rep 16, 9616 (2026). https://doi.org/10.1038/s41598-025-33713-0
Schlüsselwörter: Hochwasserprognose, Flussabfluss, Deep Learning, Unsicherheitsabschätzung, Jangtsekiang