Clear Sky Science · fr
Décomposition optimisée et apprentissage profond avec correction de biais pour une prévision ponctuelle et par intervalle fiable des débits
Pourquoi des prévisions fluviales plus intelligentes importent
Les communautés le long de grands fleuves comme le Yangtsé vivent en permanence entre trop d'eau et trop peu. Les crues soudaines peuvent mettre en danger des vies et des infrastructures, tandis que les longues périodes de sécheresse menacent l'approvisionnement en eau potable, l'agriculture et l'hydroélectricité. Cette étude présente une nouvelle manière de prévoir le débit du Yangtsé sur plusieurs mois, non seulement sous la forme d'une estimation unique mais aussi avec une mesure claire de l'incertitude associée — une information qui peut aider les planificateurs à se préparer pour les conditions courantes comme pour les extrêmes rares.
Domestiquer un signal fluvial agité
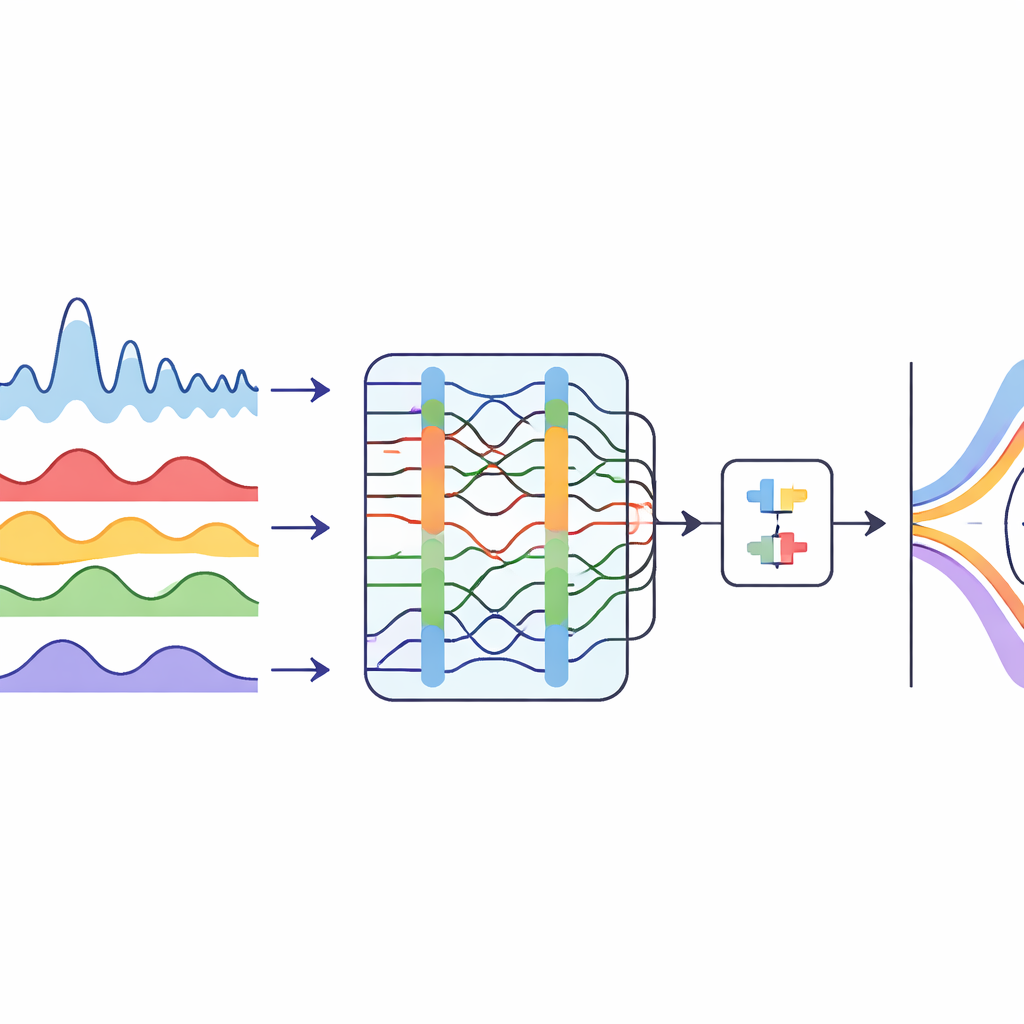
Le débit d'un fleuve monte et descend selon des motifs complexes façonnés par les moussons, les barrages, l'usage des terres et le changement climatique. Ces fluctuations rendent les données « bruyantes » et irrégulières, ce qui peut perturber même des modèles informatiques avancés. Les auteurs commencent par résoudre ce problème en décomposant la série mensuelle de débits de deux stations du Yangtsé en plusieurs composantes plus lisses. Ils utilisent une technique qui sépare un signal emmêlé en éléments de base plus nets, puis laissent un algorithme d'optimisation inspiré du comportement de chasse des baleines à bosse choisir automatiquement combien de composantes utiliser et à quel degré chacune doit être lissée. Le résultat est un ensemble de tendances de débit plus stables et plus faciles à appréhender pour un système d'apprentissage.
Apprendre aux machines à lire le fleuve
Une fois la série décomposée, l'étude utilise un modèle hybride d'apprentissage profond pour prédire le débit futur. Une partie du modèle, un réseau convolutif temporel, est efficace pour repérer les motifs à long terme et les rythmes saisonniers dans une séquence. Une autre partie, un réseau récurrent bidirectionnel, regarde à la fois en arrière et en avant le long de la chronologie pour mieux saisir comment les mois passés influencent le mois suivant. L'optimiseur inspiré des baleines règle également des paramètres clés de conception de ce modèle combiné, comme le nombre de filtres et la vitesse d'apprentissage. Cette mise au point soigneuse permet au système d'obtenir des prévisions à un mois beaucoup plus précises que plusieurs méthodes concurrentes, y compris les réseaux neuronaux plus traditionnels et les modèles de séquence basés sur les transformeurs.
Corriger les biais cachés dans les prédictions
Même lorsque les erreurs moyennes sont faibles, un modèle peut afficher des erreurs subtiles et répétées — par exemple, sous-estimer régulièrement les grandes crues. Pour corriger ces biais cachés, les auteurs ajoutent une seconde étape d'apprentissage. D'abord, le modèle produit une prévision initiale à partir des signaux décomposés. Ensuite, ils calculent la différence entre cette prévision et les débits observés et entraînent le même type de réseau à prédire ces erreurs résiduelles. En ajoutant les erreurs prédites à la prévision initiale, ils obtiennent un résultat corrigé des biais. Dans les deux stations du Yangtsé, cette stratégie réduit l'erreur standard des prévisions d'environ deux tiers par rapport au même modèle sans correction de biais, et suit beaucoup plus fidèlement les pics de la saison des crues.
D'une seule courbe à une gamme de possibilités
Pour les décisions réelles, connaître une seule prévision « optimale » ne suffit pas ; les gestionnaires ont besoin de comprendre l'étendue des débits encore plausibles. L'étude va donc au-delà des prévisions ponctuelles pour estimer des intervalles de prédiction — des bandes qui devraient contenir le débit réel un pourcentage choisi du temps. Plutôt que de supposer une erreur de forme gaussienne simple, les auteurs estiment la distribution des erreurs directement à partir des données en utilisant une méthode flexible qui lisse les résidus observés. Cette approche non paramétrique saisit mieux les comportements asymétriques et à queues lourdes, importants pour les événements extrêmes. En utilisant ces distributions d'erreur ajustées, ils construisent des intervalles de débit à différents niveaux de confiance et montrent que leur méthode couvre de manière plus fiable les débits observés, tout en conservant des bandes relativement étroites, par rapport aux distributions statistiques standard.
Ce que cela signifie pour les populations et la planification
Concrètement, l'étude fournit un outil de prévision à la fois plus précis et plus transparent sur son incertitude. En épurant la série de débit, en utilisant un moteur d'apprentissage profond optimisé, en corrigeant les erreurs systématiques, puis en construisant des bandes d'incertitude fondées sur les données, le cadre offre aux gestionnaires de l'eau le long du Yangtsé une image plus claire de ce à quoi s'attendre et du degré de certitude possible. Bien que la méthode soit gourmande en calcul et nécessite encore des tests dans d'autres bassins fluviaux, elle ouvre la voie à une nouvelle génération de prévisions fluviales pouvant mieux guider l'exploitation des barrages, les alertes de crue et la planification à long terme de l'eau dans un climat en mutation.
Citation: Ma, H., Marsani, M.F., Mansor, M.A. et al. Optimized decomposition and deep learning with bias correction for reliable runoff point-interval prediction. Sci Rep 16, 9616 (2026). https://doi.org/10.1038/s41598-025-33713-0
Mots-clés: prévision des crues, débit fluvial, apprentissage profond, estimation de l'incertitude, fleuve Yangtsé