Clear Sky Science · it
Decomposizione ottimizzata e deep learning con correzione del bias per previsioni affidabili del deflusso puntuali e intervallari
Perché previsioni fluviali più intelligenti sono importanti
Le comunità lungo grandi fiumi come lo Yangtze vivono in una tensione costante tra acqua in eccesso e scarsità. Inondazioni improvvise possono mettere in pericolo vite e infrastrutture, mentre lunghi periodi di siccità minacciano le riserve idriche potabili, l’agricoltura e l’energia idroelettrica. Questo studio propone un nuovo modo di prevedere quanta acqua scorrerà nello Yangtze nei mesi a venire, non solo come singola stima puntuale ma anche fornendo una chiara misura dell’incertezza di quella previsione — informazione utile ai pianificatori per prepararsi sia alle condizioni ordinarie sia agli eventi estremi rari.
Dominare un segnale fluviale irrequieto
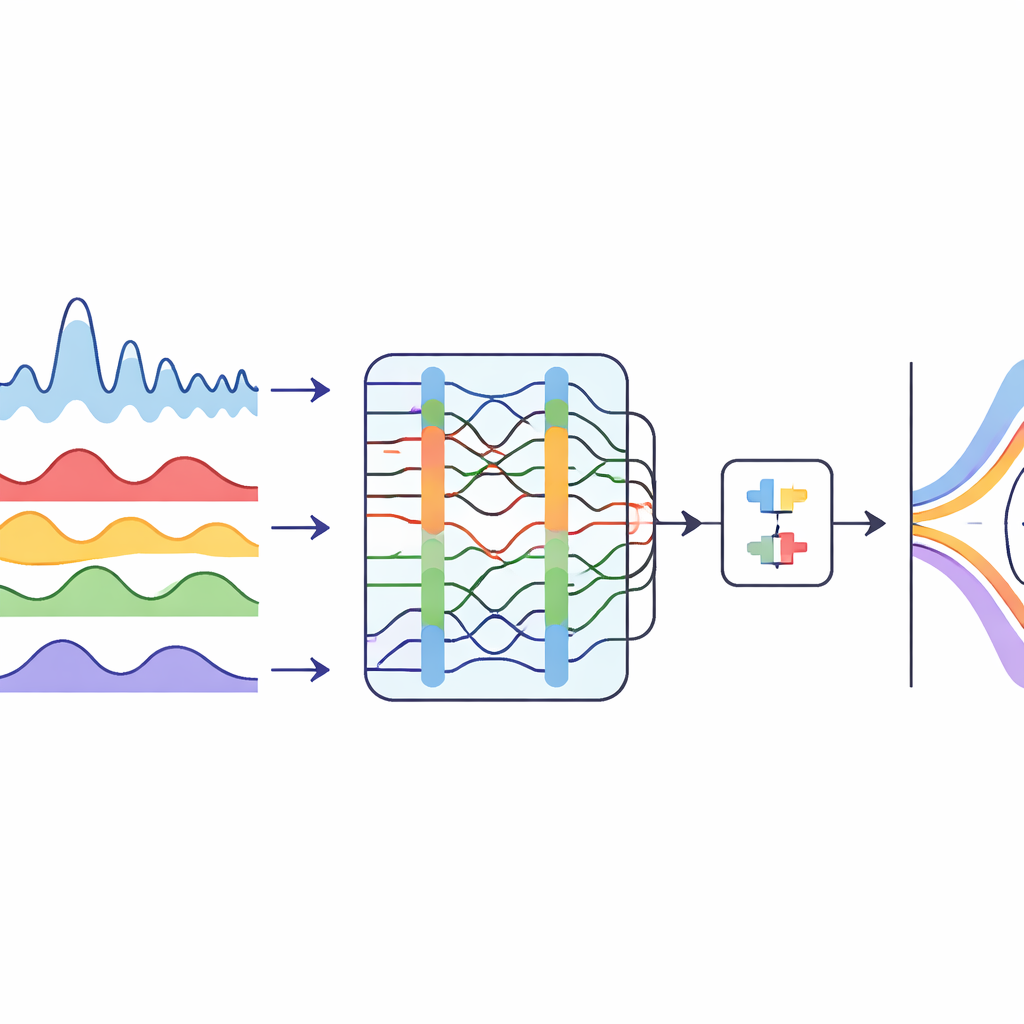
Il deflusso fluviale aumenta e diminuisce secondo schemi complessi modellati dalle piogge monsoniche, dalle dighe, dall’uso del suolo e dai cambiamenti climatici. Questi alti e bassi rendono i dati “rumorosi” e irregolari, condizioni che possono confondere anche modelli informatici avanzati. Gli autori affrontano prima questo problema scomponendo la serie mensile del deflusso di due stazioni sullo Yangtze in diversi componenti più regolari. Usano una tecnica che separa un segnale aggrovigliato in blocchi costitutivi più puliti, e poi lasciano che un algoritmo di ottimizzazione ispirato al comportamento di caccia delle megattere scelga automaticamente quanti componenti usare e quanto ciascuno debba essere levigato. Il risultato è un insieme di pattern di flusso più stabili, più facili da interpretare per un sistema di apprendimento.
Insegnare alle macchine a leggere il fiume
Una volta scomposta la serie dei deflussi, lo studio ricorre a un modello ibrido di deep learning per prevedere i deflussi futuri. Una parte del modello, una rete convoluzionale temporale, è abile a individuare pattern a lungo termine e ritmi stagionali in una sequenza. Un’altra parte, una rete ricorrente bidirezionale, guarda sia indietro che avanti lungo la linea temporale per comprendere meglio come i mesi passati influenzino quello successivo. L’ottimizzatore ispirato alle megattere regola anche impostazioni chiave di questo modello combinato, come il numero di filtri e la velocità di apprendimento. Questa messa a punto permette al sistema di ottenere previsioni a un mese molto più accurate rispetto a una serie di metodi concorrenti, incluse reti neurali più tradizionali e modelli di sequenza basati su transformer.
Correggere bias nascosti nelle previsioni
Anche quando gli errori medi sono piccoli, un modello può comunque mostrare errori sottili e ripetuti — per esempio, sottostimare regolarmente le grandi inondazioni. Per correggere questi bias nascosti, gli autori aggiungono un secondo passaggio di apprendimento. Innanzitutto il modello produce una previsione iniziale a partire dai segnali scomposti. Poi calcolano la differenza tra questa previsione e i deflussi osservati e addestrano lo stesso tipo di rete a prevedere questi errori residui. Sommando gli errori previsti alla previsione iniziale si ottiene un risultato con bias corretto. In entrambe le stazioni sullo Yangtze questa strategia riduce l’errore standard delle previsioni di circa due terzi rispetto allo stesso modello senza correzione del bias, e riesce a seguire i picchi della stagione delle piene in modo molto più accurato.
Da una singola linea a un ventaglio di possibilità
Per decisioni operative reali, conoscere una sola previsione “migliore” non basta; i gestori devono capire l’intervallo di portate che restano plausibili. Lo studio va quindi oltre le previsioni puntuali per stimare intervalli di previsione — fasce che dovrebbero contenere il deflusso vero per una percentuale scelta del tempo. Invece di assumere un semplice errore a campana, gli autori stimano la distribuzione degli errori direttamente dai dati usando un metodo flessibile che leviga i residui osservati. Questo approccio non parametrico cattura meglio asimmetrie e code pesanti, aspetti importanti per gli eventi estremi. Usando queste distribuzioni d’errore adattate, costruiscono intervalli di deflusso a diversi livelli di confidenza e mostrano che il loro metodo copre i deflussi osservati in modo più affidabile, pur mantenendo fasce relativamente strette, rispetto alle distribuzioni statistiche standard.
Che cosa significa per le persone e la pianificazione
In termini semplici, lo studio offre uno strumento di previsione più nitido e più trasparente rispetto alla sua incertezza. Pulendo la serie dei deflussi, impiegando un motore di deep learning ottimizzato, correggendo errori sistematici e quindi costruendo fasce d’incertezza guidate dai dati, il quadro fornisce ai gestori idrici lungo lo Yangtze un’immagine più chiara di cosa aspettarsi e di quanto si può essere sicuri. Pur essendo il metodo computazionalmente complesso e necessitando ancora di test in altri bacini fluviali, indica la direzione per una nuova generazione di previsioni fluviali in grado di guidare meglio la gestione delle dighe, gli allarmi per le piene e la pianificazione idrica a lungo termine in un clima che cambia.
Citazione: Ma, H., Marsani, M.F., Mansor, M.A. et al. Optimized decomposition and deep learning with bias correction for reliable runoff point-interval prediction. Sci Rep 16, 9616 (2026). https://doi.org/10.1038/s41598-025-33713-0
Parole chiave: previsione delle inondazioni, deflusso fluviale, deep learning, stima dell'incertezza, Fiume Yangtze