Clear Sky Science · nl
Een multimodaal retina‑beeldendatabestand voor detectie van diabetische retinopathie met foundation‑modellen
Waarom het vroeg herkennen van oogschade telt
Bij mensen met diabetes kan schade aan het lichtgevoelige weefsel achter in het oog jarenlang sluipend voortschrijden voordat het zicht merkbaar vervaagt. Tegen de tijd dat er symptomen optreden, kan een deel van de schade onherstelbaar zijn. Artsen weten dat regelmatige oogscans problemen vroeg kunnen opsporen, maar het handmatig lezen van duizenden beelden is traag en duur. Deze studie introduceert een grote, zorgvuldig gelabelde verzameling retina‑beelden die AI‑systemen moet helpen diabetische oogaandoeningen nauwkeuriger en betrouwbaarder te detecteren, waardoor veel meer patiënten eerder gewaarschuwd kunnen worden.
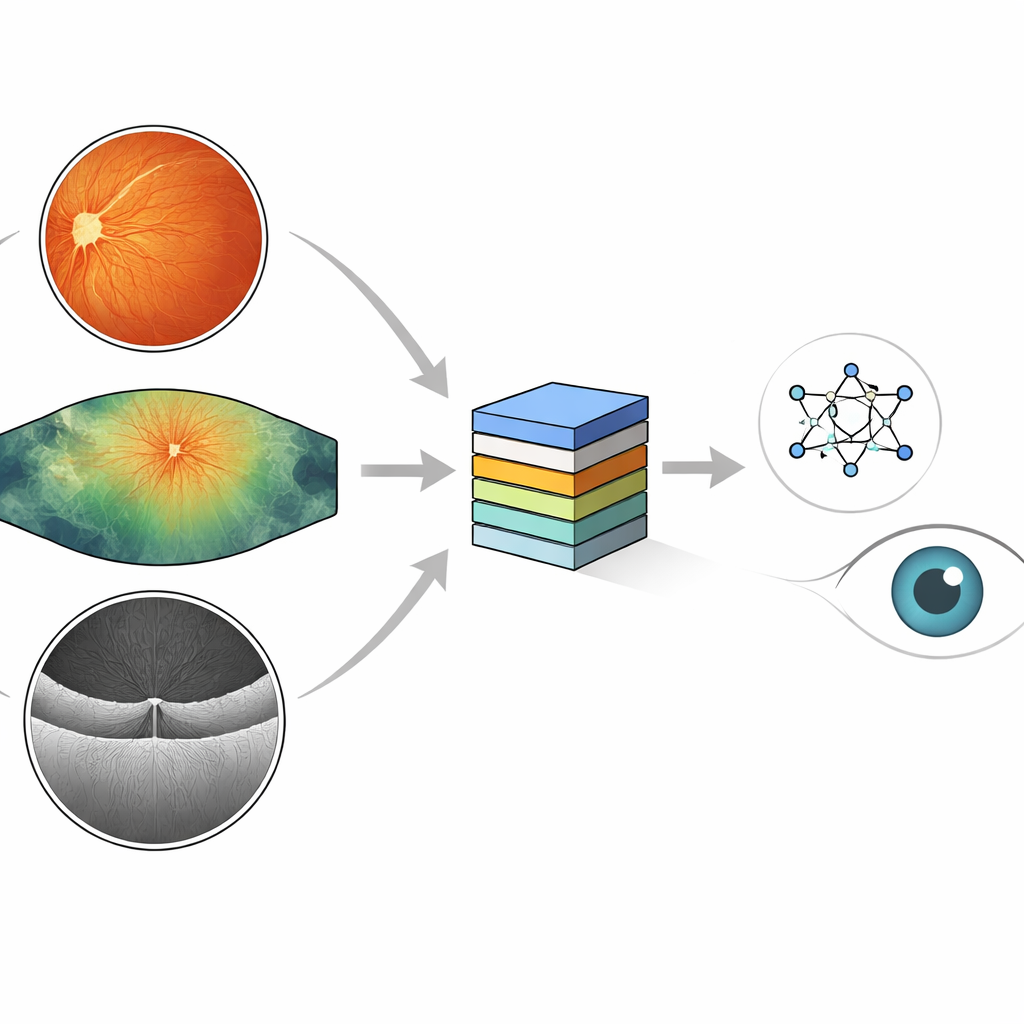
Verschillende camerazichten op hetzelfde oogaandoening
Oogartsen gebruiken meerdere soorten camera’s om naar schade door diabetes te zoeken. Standaardkleurfoto’s van de achterkant van het oog tonen een ronde, roodachtige opname waarin kleine bloedvlekjes, vetafzettingen en nieuwe fragiele vaten kunnen verschijnen. Ultra‑widefield‑beelden leggen een veel groter gebied vast, inclusief de verre randen van het netvlies waar vroege schade zich kan verbergen. Een derde instrument, optical coherence tomography (OCT), snijdt het netvlies in dwarsdoorsnede en onthult zwellingen en vochtophopingen die verband houden met macula‑oedeem dat het zicht bedreigt. Elke methode legt andere aspecten van hetzelfde ziekteproces vast; samen geven ze een vollediger beeld van de ooggezondheid.
Wat nieuw is aan deze beeldverzameling
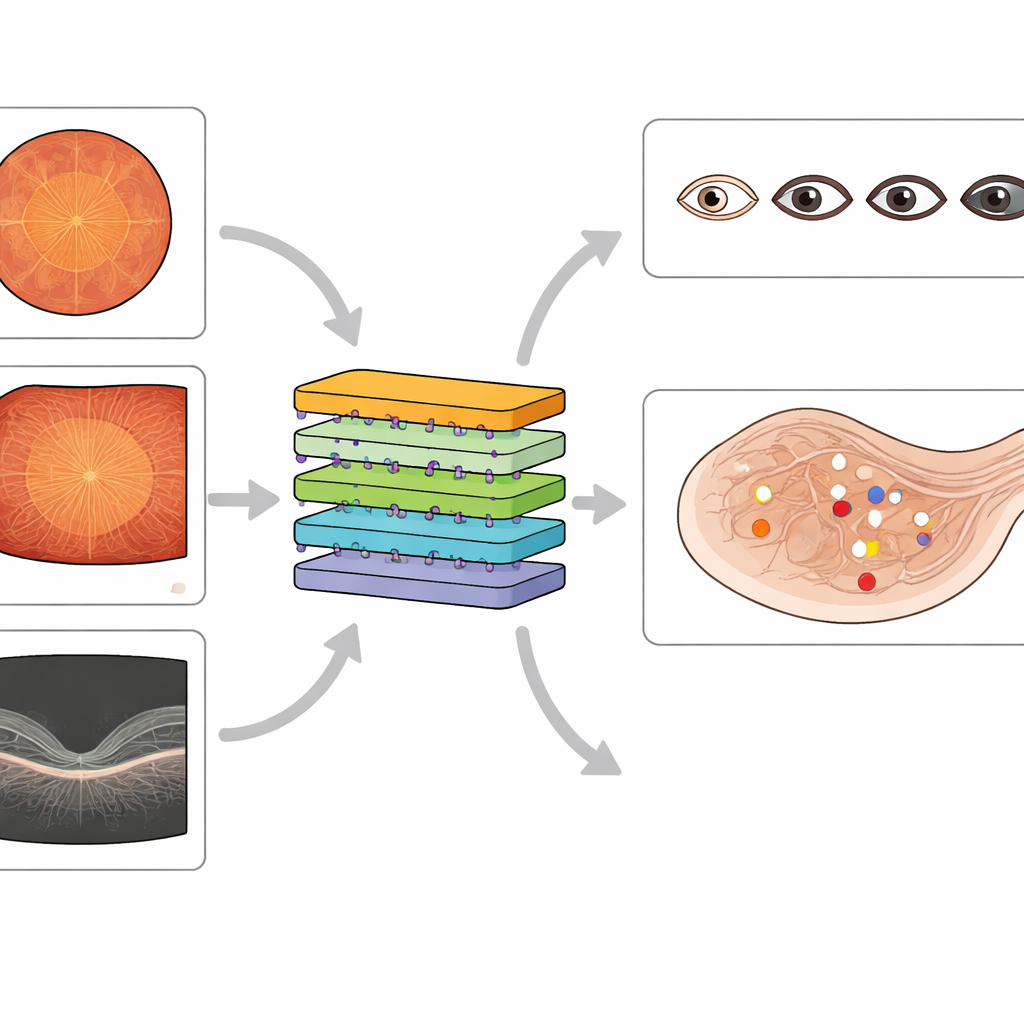
Bestaande openbare datasets hebben veel AI‑systemen voor screening van diabetische ogen aangedreven, maar de meeste richten zich op slechts één beeldvormingsmethode en bieden alleen grove labels, zoals één algemene ziektelasering. Sommige bevatten storende labels of missen belangrijke laesietypen, en veel hebben geen goede dekking van widefield‑beelden of gedetailleerde informatie over maculaire zwelling. De nieuwe MMRDR‑dataset wil deze leemtes vullen. Hij verzamelt 24.460 beelden over drie modaliteiten — standaardkleurfoto’s, ultra‑widefield‑beelden en OCT‑scans — en voorziet deze van rijke, deskundige annotaties. Voor kleur- en widefield‑beelden beoordeelden artsen de algemene ziektegraad op een vijfstappenschaal en noteerden ze zeven specifieke laesietypen, zoals kleine verwijdingen in bloedvaten, bloedingen en netvliesloslating. Voor OCT‑scans beschreven ze of macula‑oedeem afwezig is, aanwezig buiten het centrum, of direct het centrum van het zicht aantast.
Hoe de beelden werden geselecteerd en gelabeld
De auteurs haalden standaardkleurfoto’s uit een bestaande openbare competitie‑dataset en verkregen widefield‑ en OCT‑beelden van een groot Chinees oogziekenhuis, met focus op mensen met diabetes. Ze verwijderden beelden van lage kwaliteit met onscherpte, slechte belichting of ontbrekende centra om te waarborgen dat de overgebleven scans klinisch bruikbaar waren. Vier ervaren oogartsen en een senior netvliesspecialist ontwikkelden duidelijke gradeerregels op basis van internationale richtlijnen. De specialist stelde eerst een referentieset van beelden samen; de andere beoordelaars oefenden op deze set totdat hun beoordelingen sterk overeenkwamen met die van de expert. Vervolgens labelden ze onafhankelijk duizenden beelden en stuurden ze twijfelgevallen terug naar de specialist. De uiteindelijke collectie combineert grondige labeling met een hoge interbeoordelaarsovereenkomst, waardoor het een betrouwbare leerset voor AI is.
Het testen van hedendaagse AI op toekomstige oogdata
Het team gebruikte de dataset vervolgens om verschillende typen geavanceerde AI‑modellen te evalueren. Ze testten grote vision‑language‑modellen die oorspronkelijk op algemene beelden en tekst waren getraind, standaard beeldclassificatoren getraind op alledaagse foto’s, en nieuwere “foundation”‑modellen die al op oogbeelden waren afgestemd. Over de hele linie hadden modellen de meeste moeite met ultra‑widefield‑beelden, waar het veel grotere gezichtsveld en de complexere patronen de nauwkeurigheid verminderden vergeleken met standaardkleurfoto’s. Modellen die specifiek voor oogbeelden waren ontworpen, lieten betere overdracht van standaard naar widefield‑zicht zien dan algemene multimodale systemen, wat erop wijst dat kennis van retinale structuur echt telt. Toen de onderzoekers één groot multimodaal model fijnstelden op MMRDR, verbeterde de prestatie aanzienlijk, wat aantoont dat deze dataset zelfs zeer flexibele AI‑systemen kan leren om beter met oogaandoeningen om te gaan.
Wat dit betekent voor toekomstige oogzorg
In eenvoudige termen levert dit werk een hoogwaardige leerbibliotheek voor computers die leren diabetische oogschade te herkennen. Door drie elkaar aanvullende beeldvormingsmethoden te combineren met gedetailleerde expertlabels, stelt de MMRDR‑dataset onderzoekers in staat AI‑tools te bouwen en eerlijk te vergelijken die ziekteernst beoordelen, individuele laesies lokaliseren en maculaire zwelling volgen. Hoewel deze beelden op zichzelf blindheid niet zullen genezen, bieden ze een cruciale basis voor betrouwbaardere geautomatiseerde screeningssystemen die zichtbedreigende veranderingen eerder kunnen opvangen en expert‑niveau oogzorg binnen bereik van veel meer mensen met diabetes kunnen brengen.
Bronvermelding: Tang, Z., Wang, L., Guo, Z. et al. A multimodal retinal image dataset for diabetic retinopathy detection using foundation models. Sci Data 13, 639 (2026). https://doi.org/10.1038/s41597-026-07005-9
Trefwoorden: diabetische retinopathie, retina‑beeldvorming, medische AI, foundation‑modellen, oculaire OCT