Clear Sky Science · es
Un conjunto multimodal de imágenes retinianas para la detección de la retinopatía diabética mediante modelos foundation
Por qué importa detectar el daño ocular de forma temprana
En las personas con diabetes, el tejido fotosensorial en la parte posterior del ojo puede deteriorarse de forma silenciosa durante años antes de que la visión se note borrosa. Cuando aparecen los síntomas, parte del daño puede ser ya irreversible. Los médicos saben que las exploraciones oculares periódicas permiten detectar problemas a tiempo, pero leer miles de imágenes manualmente es lento y costoso. Este estudio presenta una colección amplia y cuidadosamente etiquetada de imágenes retinianas diseñada para ayudar a que los sistemas de inteligencia artificial (IA) aprendan a detectar la enfermedad ocular diabética con mayor precisión y fiabilidad, llevando alertas más tempranas a muchos más pacientes.
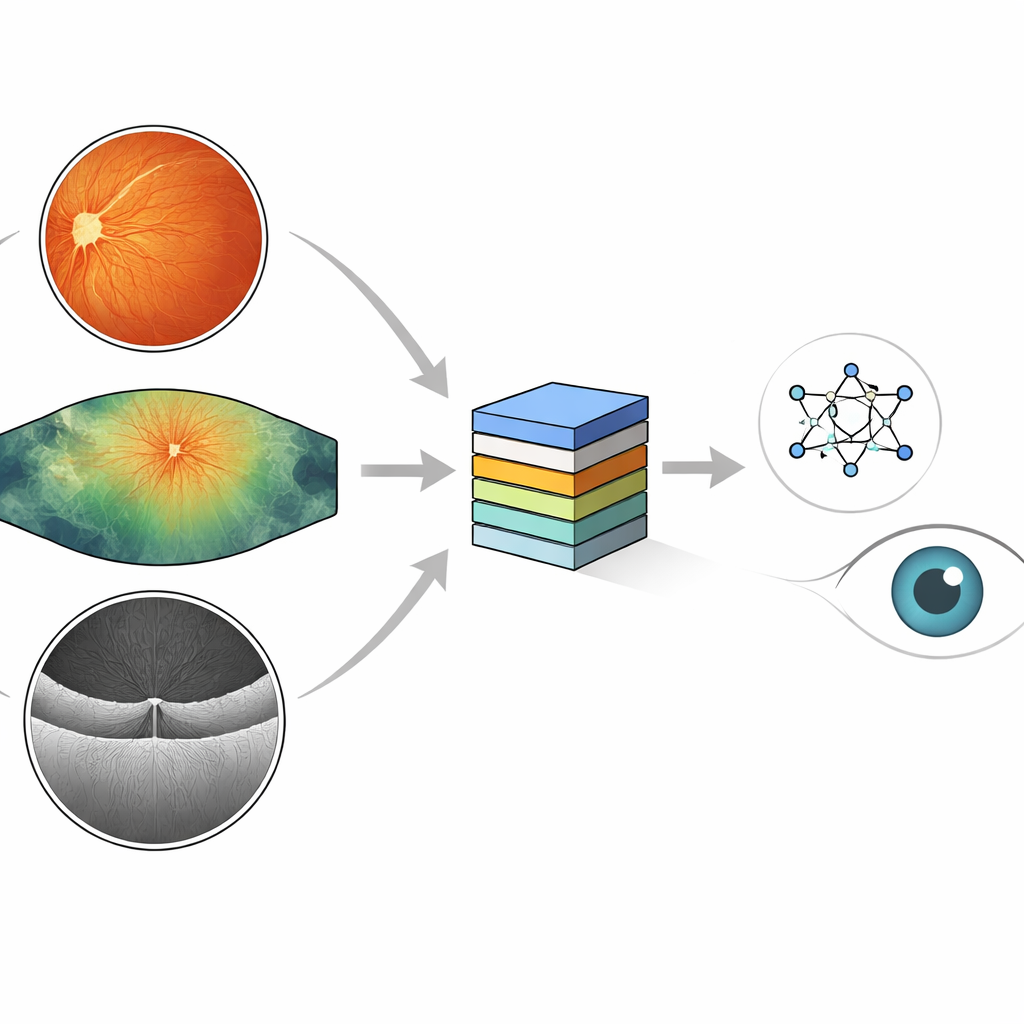
Diferentes vistas con cámaras del mismo problema ocular
Los oftalmólogos usan varios tipos de cámaras para buscar daño relacionado con la diabetes. Las fotografías en color estándar de la parte posterior del ojo muestran una vista redondeada y rojiza donde pueden aparecer pequeños puntos de sangre, depósitos grasos y nuevos vasos frágiles. Las imágenes ultra‑gran angular capturan una zona mucho mayor, incluidos los bordes periféricos de la retina donde el daño temprano puede esconderse. Una tercera herramienta, la tomografía de coherencia óptica (OCT), recorta la retina en sección transversal, revelando hinchazón y bolsas de líquido asociadas al edema macular que amenaza la visión. Cada método muestra piezas diferentes del mismo proceso patológico y, juntos, ofrecen una imagen más completa de la salud ocular.
Qué hay de nuevo en esta colección de imágenes
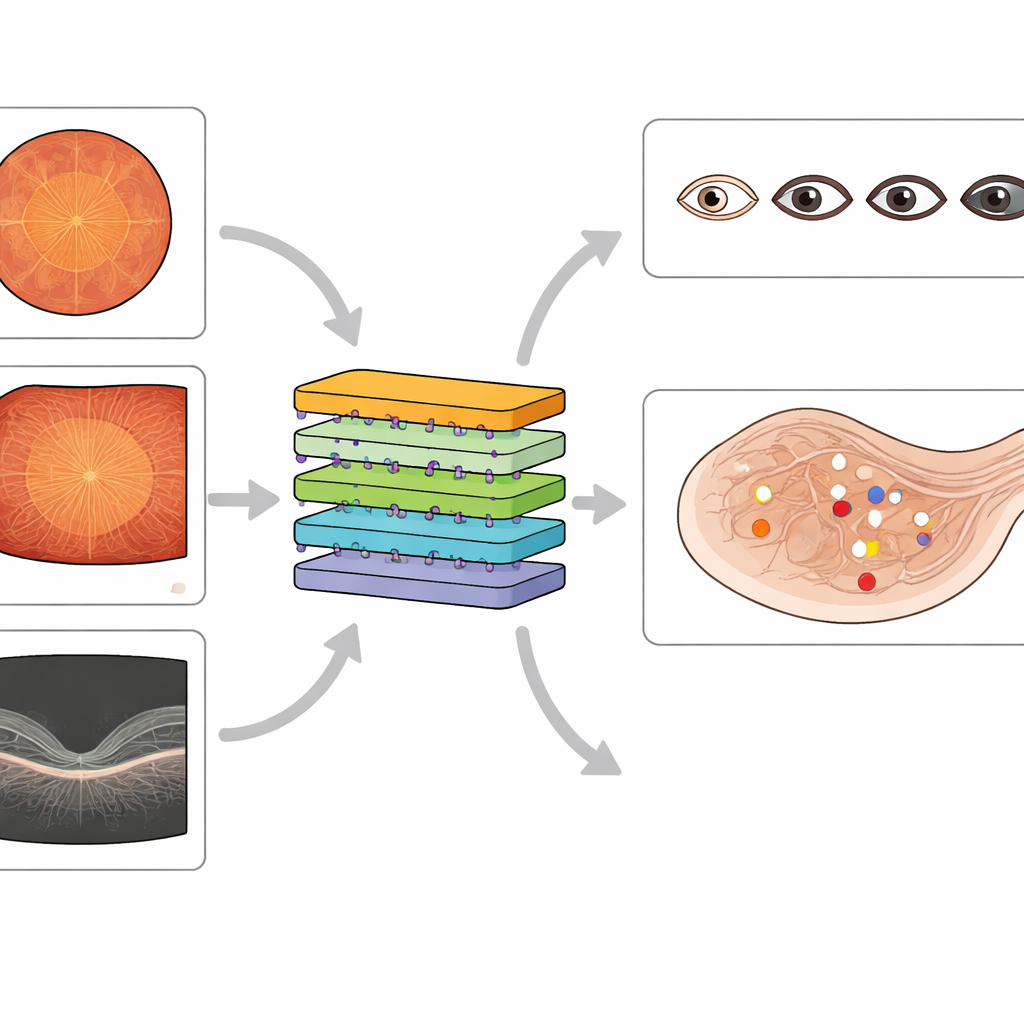
Los conjuntos de datos públicos existentes han alimentado muchos sistemas de IA para cribado de la enfermedad ocular diabética, pero la mayoría se centran en un solo método de imagen y ofrecen etiquetas sólo generales, como una calificación global de la enfermedad. Algunos contienen etiquetas ruidosas o omiten tipos importantes de lesiones, y muchos carecen de buena cobertura de imágenes widefield o de información detallada sobre el edema macular. El nuevo conjunto MMRDR pretende cubrir estas lagunas. Reúne 24.460 imágenes en tres modalidades: fotografías en color estándar, imágenes ultra‑gran angular y exploraciones OCT, y acompaña cada imagen con anotaciones expertas detalladas. Para las imágenes en color y widefield, los médicos gradaron la enfermedad global en una escala de cinco pasos y registraron siete tipos específicos de lesión, como pequeños engrosamientos de vasos, hemorragias y desprendimiento de retina. Para las exploraciones OCT, describieron si el edema macular está ausente, presente fuera del centro o afecta directamente al centro de la visión.
Cómo se seleccionaron y etiquetaron las imágenes
Los autores tomaron fotografías en color estándar de un conjunto de datos público de una competición previa y obtuvieron imágenes widefield y OCT de un gran hospital oftalmológico en China, enfocándose en personas con diabetes. Eliminaron las imágenes de baja calidad con desenfoque, iluminación deficiente o regiones centrales faltantes para asegurar que las exploraciones restantes fueran clínicamente útiles. Cuatro oftalmólogos experimentados y un especialista retiniano sénior desarrollaron reglas de gradación claras basadas en guías internacionales. El especialista creó primero un conjunto de referencia de imágenes; los demás calificadores practicaron con este conjunto hasta alcanzar una alta concordancia con las decisiones del experto. Después, etiquetaron de forma independiente miles de imágenes, remitiendo los casos inciertos al especialista. La colección final equilibra un etiquetado exhaustivo con una sólida concordancia entre médicos, lo que la convierte en un conjunto de enseñanza fiable para la IA.
Evaluando la IA actual con los datos oculares del mañana
El equipo usó después el conjunto de datos para evaluar varios tipos de modelos de IA avanzados. Probaron grandes modelos visión‑lenguaje entrenados originalmente con imágenes y textos generales, clasificadores de imágenes estándar entrenados con fotografías cotidianas y modelos "foundation" más recientes ya afinados en imágenes oculares. En general, los modelos tuvieron más dificultades con las imágenes ultra‑gran angular, donde la vista mucho más amplia y los patrones más complejos redujeron la precisión respecto a las fotografías en color estándar. Los modelos diseñados específicamente para imágenes oculares mostraron mejor transferencia desde vistas estándar a widefield que los sistemas multimodales generales, lo que sugiere que el conocimiento de la estructura retiniana importa. Cuando los investigadores ajustaron finamente un gran modelo multimodal con MMRDR, su rendimiento mejoró notablemente, demostrando que este conjunto puede enseñar incluso a sistemas de IA muy flexibles a manejar la enfermedad ocular con mayor competencia.
Qué significa esto para la atención ocular futura
En términos sencillos, este trabajo entrega una biblioteca de enseñanza de alta calidad para que los ordenadores aprendan a detectar el daño ocular diabético. Al combinar tres métodos de imagen complementarios y etiquetas expertas detalladas, el conjunto MMRDR permite a los investigadores desarrollar y comparar de forma justa herramientas de IA que gradúen la gravedad de la enfermedad, localicen lesiones individuales y controlen el edema macular. Aunque estas imágenes por sí solas no curarán la ceguera, proporcionan una base crucial para sistemas de cribado automatizados más fiables que podrían detectar cambios que amenacen la visión con mayor antelación y acercar atención oftalmológica de nivel experto a muchas más personas con diabetes.
Cita: Tang, Z., Wang, L., Guo, Z. et al. A multimodal retinal image dataset for diabetic retinopathy detection using foundation models. Sci Data 13, 639 (2026). https://doi.org/10.1038/s41597-026-07005-9
Palabras clave: retinopatía diabética, imagenología retiniana, IA médica, modelos foundation, OCT ocular