Clear Sky Science · nl
EPInformer: schaalbare en integratieve voorspelling van genexpressie uit promotor-enhancer-sequenties met multimodale epigenomische profielen
Waarom het voorspellen van genactiviteit ertoe doet
Elke cel in je lichaam draagt in wezen hetzelfde DNA, maar zenuwcellen, bloedcellen en levercellen gedragen zich heel verschillend. Wat hen onderscheidt is welke genen aan- of uitgezet zijn. Het kunnen voorspellen van deze genactiviteit rechtstreeks uit DNA en gerelateerde signalen zou wetenschappers helpen te begrijpen hoe cellen zich ontwikkelen, reageren op hun omgeving en soms ontsporen bij ziekte. Dit artikel introduceert EPInformer, een nieuw computationeel hulpmiddel dat gebruikmaakt van recente vooruitgangen in kunstmatige intelligentie om genactiviteit nauwkeuriger en efficiënter te voorspellen dan eerdere methoden.

Hoe verre DNA-schakelaars genen aansturen
Genen worden niet alleen gereguleerd door het korte stuk DNA waar hun aflezing begint (de promotor). Ze worden ook beïnvloed door verre stukken DNA die enhancers worden genoemd en fungeren als afstandsschakelaars. Deze schakelaars kunnen tienduizenden of zelfs honderdduizenden DNA-letters van een gen verwijderd zitten en via driedimensionale vouwing in de ruimte de promotor bereiken. Naast de ruwe DNA-sequentie geven chemische labels en eiwitmarkeringen langs het DNA — samen epigenomische signalen genoemd — aan welke schakelaars in een bepaald celtype actief zijn. Traditionele computermodellen hebben moeite gehad om al deze informatie te combineren, en met name het effect van zeer verre schakelaars, om te voorspellen hoe sterk een gen tot expressie komt.
Een compact AI-model dat veel signalen tegelijk leest
EPInformer is gebouwd op een moderne AI-architectuur bekend als een transformer, aangepast van taalmodellen. In plaats van zinnen te lezen, leest het model DNA-segmenten rond een gen en zijn kandidaat-schakelaars. Het model zet eerst elke promotor- en nabije enhancer-sequentie om in een numerieke "embedding" die belangrijke patronen vastlegt. Het kan ook extra kanalen toevoegen die lokale chemische merken op het DNA, openheid van het chromatine en metingen van hoe vaak DNA-regio’s elkaar in 3D aanraken, representeren. Een speciaal attentiemechanisme richt zich vervolgens op hoe elke potentiële schakelaar met de promotor interacteert, terwijl interacties tussen schakelaars onderling bewust worden genegeerd. Een laatste voorspellingsstap combineert deze geleerde representatie met basiskenmerken van het gen-RNA om het verwachte activiteitsniveau uit te geven.
Betere voorspellingen met minder rekencapaciteit
Om EPInformer te testen trainden en evalueerden de auteurs het op grote openbare datasets die DNA-toegankelijkheid, chemische merken, 3D-contacten en genactiviteit profilen in meerdere menselijke cellijnen. Ze vergeleken verschillende versies van het model die alleen sequentie en afstand gebruikten, epigenomische signalen toevoegden of daarnaast 3D-contactkaarten opnamen. Zowel voor standaard RNA-sequencing als voor een promotorgerichte assay genaamd CAGE presteerde EPInformer consequent beter dan toonaangevende methoden, waaronder grote sequentie-only modellen die zeer lange stukken DNA scannen. Opmerkelijk is dat het dit deed met een fractie van het aantal parameters — ongeveer 0,4 miljoen versus honderden miljoenen — waardoor training op een enkele grafische processor in ongeveer een uur mogelijk is. Dit maakt nauwkeurige modellering van genactiviteit toegankelijk voor veel laboratoria zonder enorme rekenclusters.
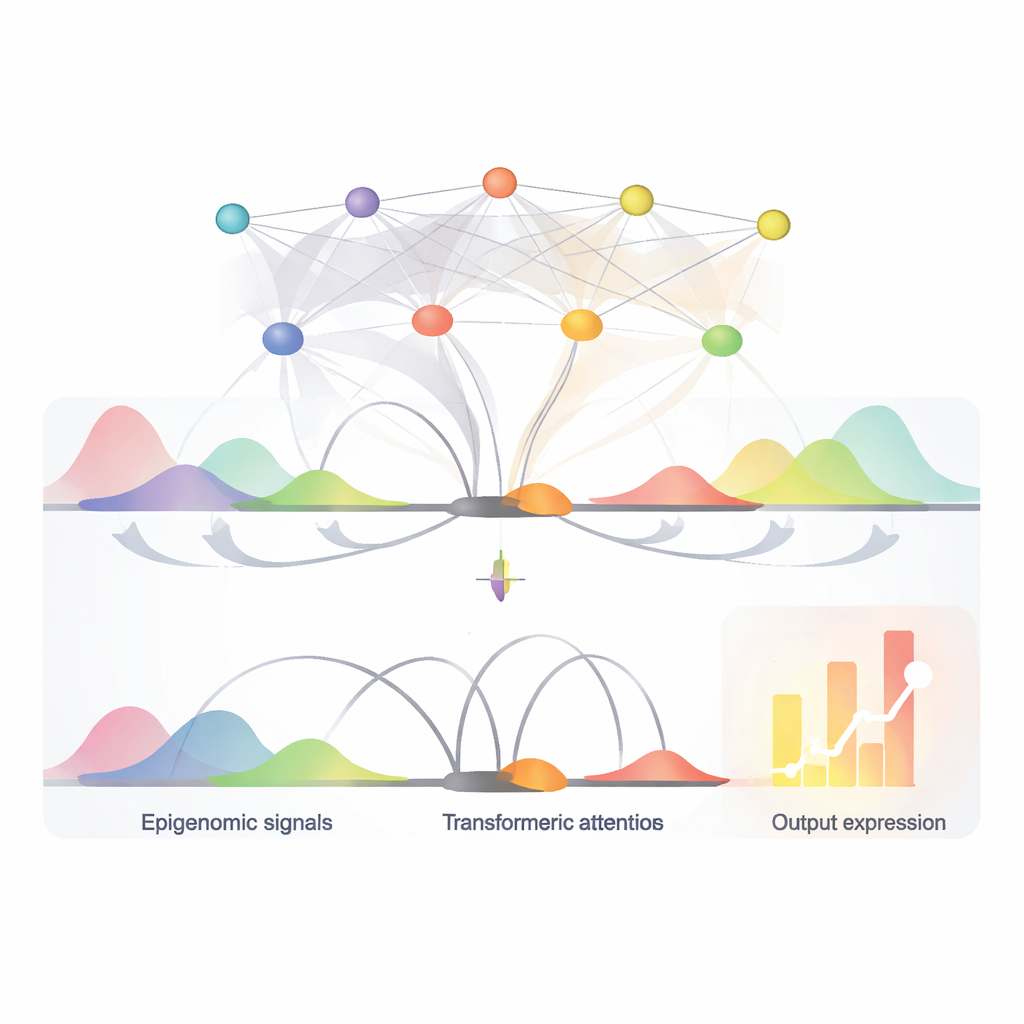
Het vinden van sleutel-schakelaars en hun controlewoorden
Omdat het attentiemechanisme van EPInformer beoordeelt hoe sterk elke kandidaat-enhancer een gen beïnvloedt, kan het ook helpen de belangrijkste schakelaars in een bepaald celtype aan te wijzen. De auteurs toonden aan dat deze attentiescores experimenteel bevestigde enhancer–gen-paren nauwkeuriger terugvonden dan een veelgebruikte scoringsmethode gebaseerd op activiteit en contact alleen, vooral voor verre schakelaars. Ze gebruikten interpretatietools om in de DNA-sequenties van de hoogst scorende enhancers te zoomen en korte terugkerende patronen te identificeren die overeenkomen met bekende bindingsplaatsen van transcriptiefactoren — eiwitten die als controlewoorden in het genoom fungeren. In bloedgerelateerde cellen herkende EPInformer bijvoorbeeld motieven van hoofdregulatoren van de ontwikkeling van rode bloedcellen, wat suggereert dat het biologisch zinvolle regels heeft geleerd in plaats van alleen data te onthouden.
Wat dit betekent voor toekomstige biologie en geneeskunde
In eenvoudige bewoordingen geeft EPInformer onderzoekers een scherper en betaalbaarder venster op hoe genen in verschillende celtypen aan- en uitgezet worden door DNA-sequentie, chemische labels en 3D-vouwing van het genoom te combineren. Het vermogen om te benadrukken welke verre schakelaars belangrijk zijn voor een bepaald gen, en welke controlewoorden ze bevatten, kan experimenten sturen die testen hoe mutaties of gerichte bewerkingen genactiviteit beïnvloeden. Naarmate de aanpak wordt uitgebreid naar meer celtypes en verschillende genvarianten, kan het helpen verklaren hoe niet-coderende veranderingen in het genoom bijdragen aan complexe eigenschappen en ziekten, en het ontwerp van preciezere genetische therapieën informeren.
Bronvermelding: Lin, J., Li, Z., Zhao, Y. et al. EPInformer: scalable and integrative prediction of gene expression from promoter-enhancer sequences with multimodal epigenomic profiles. Nat Commun 17, 3975 (2026). https://doi.org/10.1038/s41467-026-70535-8
Trefwoorden: voorspelling van genexpressie, enhancer-promotor-interacties, epigenomica, deep learning in genomica, chromatine-architectuur