Clear Sky Science · ja
機械学習による言語ベースのうつ病検出:系統的レビューとメタ解析
言葉があなたの気分を示すかもしれない理由
私たちの多くは、テキストメッセージ、電子メール、オンラインチャットなどを通じて日々自分の生活の断片を文章で共有しています。本研究は印象的な問いを投げかけます:日常の言葉のパターンは、誰かがうつ状態に苦しんでいることを示す手がかりになり得るのか。世界各地の10年以上にわたる研究を統合することで、著者らは、人々の発話や書き言葉だけからうつ病の兆候をコンピュータがどの程度検出できるか、そしてそのようなツールを現実の医療で安全に使うには何が必要かを検討します。

多くの会話から手がかりを集める
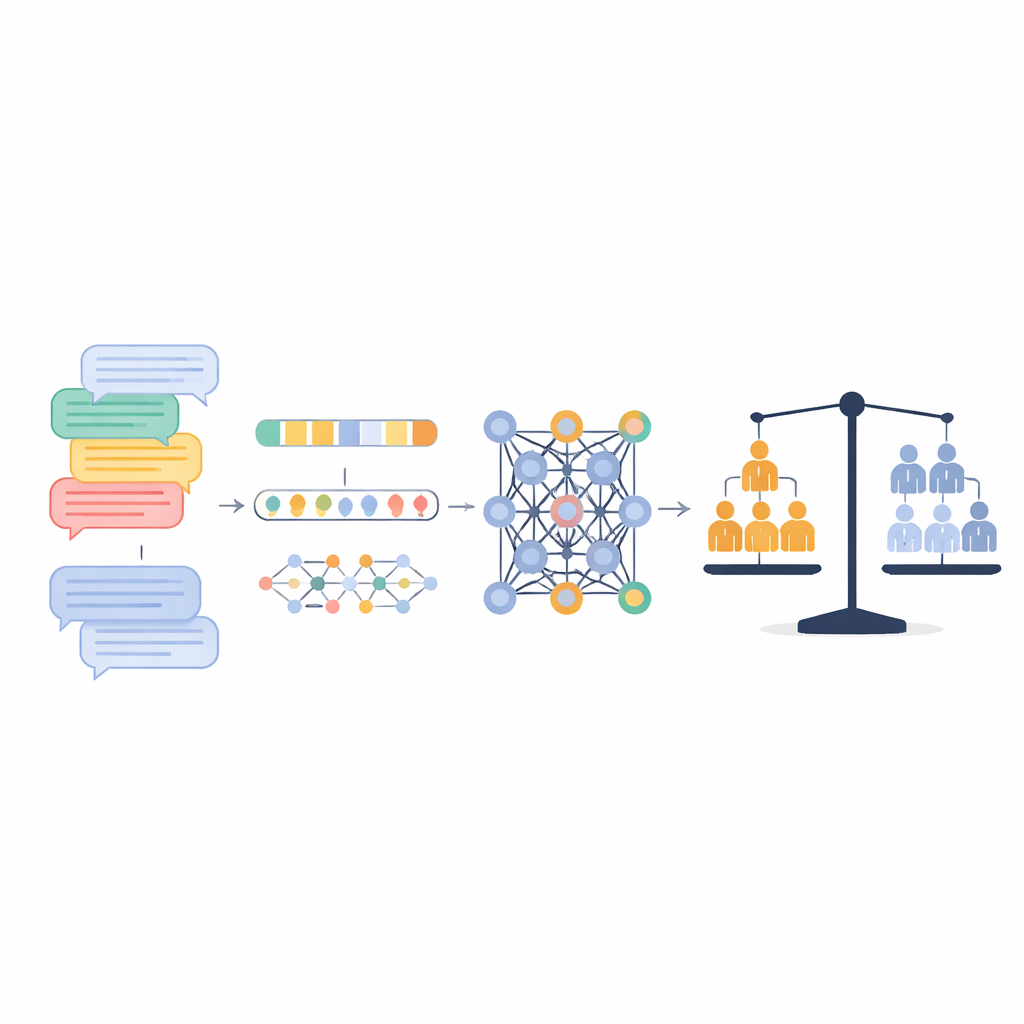
研究者らは医学および計算機科学のデータベースを体系的に検索し、話し言葉または書き言葉から機械学習でうつ病を検出しようとした123件の研究を特定しました。これらの研究は合わせて3万5千人以上、言語サンプルは約6万件に及びます。言葉の出所はさまざまでした:気分や日常生活について尋ねる構造化された臨床面接、例えば「今日はどのように感じていますか?」のような短い自由回答、セラピーやカウンセリングのチャット、そして日常的なメッセージや電子メール、日記風の記述などです。いずれの場合も、うつ病の判定は標準的な質問票や臨床医の診断といった独立した方法で行われており、モデルが予測しているのは単なる文章からの推測ではなく実際の臨床的アウトカムでした。
言葉をコンピュータの信号に変える
言語をアルゴリズムで扱えるようにするため、研究ではテキストをいくつかの方法で数値化しました。あるものは特定の語やフレーズが現れる頻度のような単純な出現数を用いました。別の研究は、否定的感情語や自己志向語のように語を心理的カテゴリーに分類する辞書を使い、各人の発話をこれらのカテゴリのプロファイルに変換しました。近年の研究では、BERTやGPTのような埋め込み(エンベディング)や大型言語モデルを使い、語や文を意味や文脈の微妙な差を捉える密な数学的空間上の点として表現しました。これらの入力に対して、ロジスティック回帰やサポートベクターマシンのような古典的手法から、再帰型ニューラルネットワークやトランスフォーマーベースの深層学習システムまで、さまざまなモデルが訓練されました。
機械の成績はどれほどか
プーリングに適した43の独立データセットを横断すると、モデルは人をうつ病か非うつ病か正しく分類する確率は約80%でした。陽性的中率(陽性判定が実際にうつ病である割合)は平均78%、再現率(うつ病のケースをどれだけ拾えたか)は平均76%でした。ヒットとミスのバランスを取る指標であるAUCは約0.79で、全体としては比較的強い識別能力を示します。ただし、研究間で成績のばらつきは大きかったです。評価は、気分や症状に直接焦点を当てた構造化された臨床面接の言語を解析したときに最も良く、正確さは約84%に達しました。一方で、より自由なセラピー会話や日常的なチャットに頼った場合は成績が落ち、うつ病のサインがより微妙で他の話題と混ざっているため検出が難しくなりました。
最も重要なのは文脈であり、複雑さではない
著者らが研究差の理由をより深く掘り下げたところ、一貫して際立っていた要因は言語の出所でした。言語が構造化面接から来たのか、簡潔な自由回答からか、自然な会話からかが、アルゴリズムや特徴量の種類よりも精度の違いを多く説明していました。驚くべきことに、手作りの言語辞書を用いた少数の研究では、これらの単純なアプローチが複雑な深層学習システムと同等かそれ以上の成績を示すこともありました。従来の機械学習手法と最新のトランスフォーマーモデルは全体として似たような精度を示しており、利用可能な言語断片に実際に含まれる情報量が、モデルの高度さよりも上限を決めている可能性を示唆しています。
可能性、限界、そして倫理的課題
著者らは、テキストベースのツールは臨床家の代替ではなく、初期警戒やモニタリングの補助として位置づけるべきだと主張します。自動化されたシステムは、より詳しい確認が有益な人をフラグする、繰り返しの質問票の負担を減らす、受診間での気分の変化を追跡する、といった役割を果たせる可能性があります。しかし同時に重大な注意点も強調しています:言語は文化、性別、生活環境によって形作られ、ある集団で学習されたモデルは別の集団で失敗することがあり得ます。多くのデータセットが特定の集団を過剰に代表していたり、同じ面接ソースが繰り返し使われていたりして汎化性が制限されています。ほとんどの研究は単純な精度のみを報告しており、支援が必要な人を見逃すことと誤警報を出し過ぎることの現実的なトレードオフを評価するのが難しい状況です。会話や臨床記録をこのように解析する場合、プライバシー、インフォームドコンセント、公平性の問題は中心的な課題です。
ケアの未来にとっての意味
一般の読者にとっての結論は、コンピュータはすでに私たちの話し方や書き方からうつ病のサインをかなりうまく捉えられるが、完璧からは程遠いということです。特に構造化された面接など、慎重に設計された状況では、これらのシステムは約5人中4人を正しく分類できます。それでも、本研究は、言語がどこから来るかとどう定義されるかが最新のアルゴリズムの工夫と同じくらい、あるいはそれ以上に重要であることを示しています。こうしたツールを医療に安全に組み込むためには、より多様なデータセット、明確な報告基準、および臨床家を巻き込んだ設計が必要です。思慮深く使われれば、言語ベースのスクリーニングは、従来よりも早く誰かが苦境に陥り始めていることに気づくための低負担な手段を将来提供するかもしれません。
引用: Fisher, H., Jaffe, N.M., Pidvirny, K. et al. Language-based detection of depression with machine learning: systematic review and meta-analysis. npj Digit. Med. 9, 273 (2026). https://doi.org/10.1038/s41746-026-02448-1
キーワード: うつ病スクリーニング, 自然言語処理, デジタルメンタルヘルス, 機械学習, 臨床面接