Clear Sky Science · it
CODICE oltre FAIR: una tabella di marcia per software di ricerca riutilizzabile
Perché il codice invisibile che sta dietro alla scienza è importante
Dietro quasi ogni scoperta scientifica moderna, dal mappare le galassie al decodificare il DNA, c’è software che silenziosamente svolge il lavoro pesante. Eppure questo codice è spesso trattato come un ripensamento: nascosto, fragile e difficile da riutilizzare o verificare da altri. Questo articolo sostiene che se vogliamo scienza affidabile e riproducibile, dobbiamo considerare il software di ricerca come un prodotto scientifico fondamentale, non come uno strumento usa e getta. Gli autori propongono una tabella di marcia pratica, chiamata CODICE, per aiutare ricercatori e istituzioni a trasformare gli script usa e getta di oggi in mattoni affidabili e condivisibili per le scoperte di domani. 
Come la scienza è venuta a dipendere dal software
In poche decadi, il software è diventato centrale in quasi ogni campo di ricerca. Studi mostrano che quasi la metà degli articoli scientifici menziona ormai software, sia che venga usato per analizzare dati, controllare strumenti, simulare sistemi complessi o persino come prodotto principale della ricerca. A differenza di un articolo finito o di un dataset statico, però, il software è un oggetto “vivo”: cambia quando si correggono bug, si aggiungono funzionalità o contribuiscono nuove persone. Coesistono più versioni dello stesso programma, e ognuna dipende da un ambiente circostante delicato di sistemi operativi e librerie. Una piccola variazione in quell’ambiente può alterare i risultati—o rompere completamente il codice. Questa natura vivente e interdipendente significa che i principi tradizionali di condivisione dei dati, pensati per file statici, non sono sufficienti per rendere il software davvero riutilizzabile.
Da FAIR a CODICE: un nuovo modo di pensare agli strumenti di ricerca
Negli ultimi dieci anni, i principi FAIR—Findable, Accessible, Interoperable, Reusable—hanno trasformato il modo in cui gli scienziati gestiscono i dati. I tentativi di estendere FAIR al software hanno fatto progressi importanti, ma gli autori sostengono che il software richiede indicazioni più su misura. Partendo da decenni di esperienza delle comunità del software libero e open source, propongono una tabella di marcia graduale organizzata attorno a quattro pilastri che formano comodamente l’acronimo CODICE: Open, Document, Execute, Collaborate. Piuttosto che pretendere pratiche perfette fin dall’inizio, la tabella di marcia è a livelli in modo che ricercatori con scarsa formazione formale in ingegneria del software possano adottare buone abitudini passo dopo passo, mentre team più avanzati possano puntare a livelli maggiori di robustezza e apertura.
Rendere il codice aperto, comprensibile ed eseguibile
Sotto il pilastro “Open”, gli autori invitano gli scienziati a smettere di inviare zip via email su richiesta e a pubblicare invece il codice sorgente su piattaforme pubbliche di sviluppo che tracciano la storia e supportano la collaborazione. Sottolineano l’importanza dell’archiviazione a lungo termine in infrastrutture dedicate, come archivi globali di codice sorgente, in modo che i progetti restino disponibili anche se un sito di hosting chiude. Licenze open‑source chiare e una paternità esplicita sono essenziali affinché altri sappiano cosa è legalmente permesso fare e chi accreditare. Il pilastro “Document” si concentra nel rendere il software comprensibile: usare nomi significativi, aggiungere commenti che spieghino il ragionamento piuttosto che ripetere il codice, fornire esempi e tutorial semplici e scrivere documentazione di riferimento separata per le parti del programma con cui gli utenti effettivamente interagiscono.
Garantire che i risultati possano essere riprodotti e condivisi
Il pilastro “Execute” affronta una frustrazione comune: codice che tecnicamente esiste ma non può essere eseguito altrove. La tabella di marcia invita gli autori a elencare l’hardware e il software da cui il loro programma dipende, offrire ambienti di calcolo riutilizzabili quando possibile (tramite container o gestori di pacchetti specializzati), fornire suite di test in modo che gli utenti possano verificare se il software si comporta correttamente sulle proprie macchine e condividere casi d’uso reali ed eseguibili che rispecchino analisi tipiche. L’ultimo pilastro, “Collaborate”, incoraggia un impegno aperto e continuo: rispondere a segnalazioni di bug e richieste di funzionalità, spiegare se e come i contributi esterni sono benvenuti, essere chiari sui limiti del supporto e, quando appropriato, costruire una comunità tramite tutorial, workshop e mentoring. Insieme, questi passaggi trasformano codice di ricerca isolato in uno strumento condiviso che molti possono fidarsi e migliorare.
Il ruolo di tutti nel sostenere software di ricerca migliore
L’articolo chiarisce che i singoli ricercatori non possono risolvere da soli il problema del software. Le istituzioni dovrebbero investire in ingegneri del software di ricerca dedicati, riconoscere il software nelle assunzioni e nelle promozioni e fornire piattaforme di hosting del codice ben gestite. I finanziatori sono invitati a sostenere la manutenzione a lungo termine di strumenti ampiamente usati, non solo la creazione di nuovi, e a incoraggiare la licenza open‑source come opzione predefinita per aiutare ad affrontare la crisi di riproducibilità. Le biblioteche possono estendere il loro ruolo tradizionale aiutando ad archiviare software, gestire identificatori e curare cataloghi che rendano facili da trovare programmi importanti. Infine, agli editori si chiede di richiedere che il codice alla base dei risultati pubblicati sia effettivamente condiviso, collegato all’articolo e sempre più soggetto a revisione, proprio come l’articolo stesso. 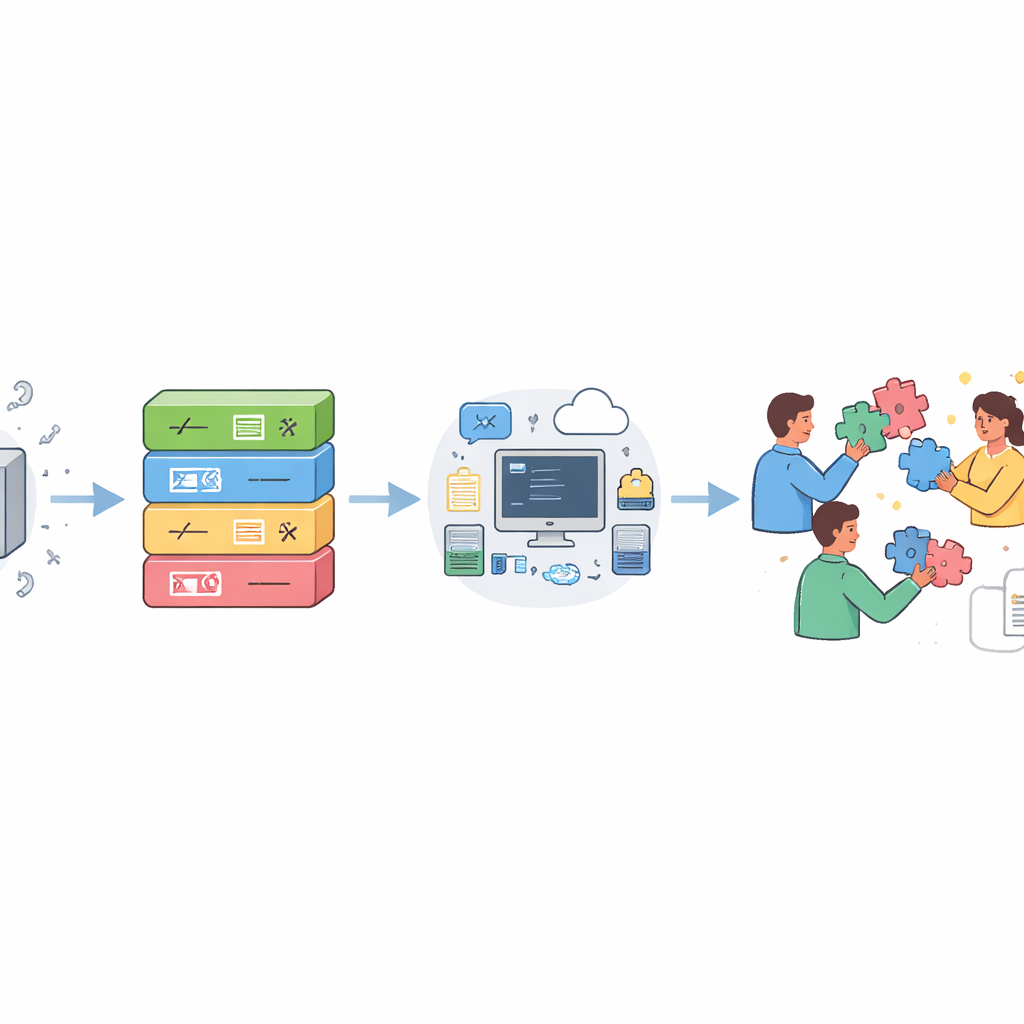
Cosa significa questa tabella di marcia per il futuro della scienza
In termini chiari, la conclusione degli autori è che una buona scienza oggi dipende da buon software, e il buon software non avviene per caso. La loro tabella di marcia CODICE offre un percorso realistico dall’odierno mosaico di script nascosti verso un ecosistema in cui il codice di ricerca è aperto, ben documentato, eseguibile altrove e migliorato da molte mani. Seguendo questi passaggi—e con università, finanziatori, biblioteche e riviste che svolgono ciascuno la propria parte—la scienza può avvicinarsi a un mondo in cui i risultati non sono solo impressionanti al primo annuncio, ma anche verificabili, riutilizzabili e durevoli per anni a venire.
Citazione: Di Cosmo, R., Granger, S., Hinsen, K. et al. CODE beyond FAIR: a roadmap for reusable research software. Sci Data 13, 514 (2026). https://doi.org/10.1038/s41597-026-06705-6
Parole chiave: software di ricerca, open source, riproducibilità, sostenibilità del software, scienza aperta