Clear Sky Science · fr
CODE au‑delà de FAIR : une feuille de route pour des logiciels de recherche réutilisables
Pourquoi le code invisible derrière la science compte
Derrière presque chaque avancée scientifique moderne, de la cartographie des galaxies au décodage de l’ADN, se trouve du logiciel qui effectue discrètement le gros du travail. Pourtant, ce code est souvent traité comme un après‑coup : caché, fragile et difficile à réutiliser ou à vérifier par d’autres. Cet article soutient que, si l’on souhaite une science fiable et reproductible, il faut considérer le logiciel de recherche comme un produit scientifique central, et non comme un outil jetable. Les auteurs proposent une feuille de route pratique, appelée CODE, pour aider les chercheurs et les institutions à transformer les scripts ponctuels d’aujourd’hui en composants fiables et partageables pour les découvertes de demain. 
Comment la science en est venue à dépendre du logiciel
En quelques décennies seulement, le logiciel est devenu central dans presque tous les domaines de la recherche. Des études montrent qu’un peu moins de la moitié des articles scientifiques mentionnent désormais des logiciels, qu’il s’agisse d’outils d’analyse de données, de contrôle d’instruments, de simulation de systèmes complexes, ou même du résultat principal de la recherche. Contrairement à un article finalisé ou à un ensemble de données statique, le logiciel est un objet « vivant » : il évolue au fur et à mesure que les bugs sont corrigés, que des fonctionnalités sont ajoutées et que de nouvelles personnes contribuent. Plusieurs versions d’un même programme coexistent, et chacune dépend d’un environnement délicat d’éléments comme le système d’exploitation et les bibliothèques. Un minuscule changement dans cet environnement peut modifier les résultats — ou casser complètement le code. Cette nature vivante et interdépendante fait que les principes traditionnels de partage des données, conçus pour des fichiers statiques, ne suffisent pas à rendre le logiciel véritablement réutilisable.
De FAIR à CODE : une nouvelle manière d’envisager les outils de recherche
Au cours de la dernière décennie, les principes FAIR — Trouvable, Accessible, Interopérable, Réutilisable — ont transformé la gestion des données par les scientifiques. Les tentatives d’étendre FAIR au logiciel ont permis des progrès importants, mais les auteurs estiment que le logiciel nécessite des directives mieux adaptées. S’appuyant sur des décennies d’expérience des communautés de logiciels libres et open source, ils proposent une feuille de route graduelle organisée autour de quatre piliers qui forment l’acronyme CODE : Open (Ouvert), Document (Documenter), Execute (Exécuter), Collaborate (Collaborer). Plutôt que d’exiger des pratiques parfaites dès le départ, la feuille de route est stratifiée de sorte que les chercheurs ayant peu de formation en ingénierie logicielle puissent adopter de meilleures habitudes pas à pas, tandis que les équipes plus avancées peuvent viser des niveaux supérieurs de robustesse et d’ouverture.
Rendre le code ouvert, compréhensible et exécutable
Sous le pilier « Open », les auteurs encouragent les scientifiques à cesser d’envoyer des fichiers zip sur demande et à publier plutôt leur code source sur des plateformes publiques de développement qui conservent l’historique et favorisent la collaboration. Ils insistent sur l’importance de l’archivage à long terme dans des infrastructures dédiées, telles que des archives mondiales de code source, afin que les projets restent disponibles même si un site d’hébergement ferme. Des licences open source claires et une paternité explicite sont essentielles pour que les autres sachent ce qu’ils sont autorisés à faire légalement et qui créditer. Le pilier « Document » met l’accent sur la compréhension du logiciel : utiliser des noms significatifs, ajouter des commentaires qui expliquent le raisonnement plutôt que de répéter le code, fournir des exemples simples et des tutoriels, et rédiger une documentation de référence séparée pour les parties du programme avec lesquelles les utilisateurs interagissent réellement.
Garantir que les résultats peuvent être reproduits et partagés
Le pilier « Execute » s’attaque à une frustration courante : le code qui existe techniquement mais qui ne peut pas être exécuté ailleurs. La feuille de route incite les auteurs à lister le matériel et les logiciels dont dépend leur programme, à proposer des environnements informatiques réutilisables lorsque c’est possible (via des conteneurs ou des gestionnaires de paquets spécialisés), à fournir des suites de tests pour que les utilisateurs puissent vérifier si le logiciel se comporte correctement sur leurs propres machines, et à partager des cas d’utilisation réels et exécutables qui reflètent les analyses typiques. Le dernier pilier, « Collaborate », encourage un engagement ouvert et continu : répondre aux rapports de bugs et aux demandes de fonctionnalités, expliquer si et comment les contributions extérieures sont les bienvenues, être transparent quant aux limites du support, et, lorsque c’est approprié, construire une communauté par des tutoriels, des ateliers et du mentorat. Ensemble, ces étapes transforment du code de recherche isolé en un outil partagé auquel beaucoup peuvent faire confiance et qu’ils peuvent améliorer.
Le rôle de chacun pour soutenir de meilleurs logiciels de recherche
L’article souligne clairement que les chercheurs individuels ne peuvent pas résoudre seuls le problème du logiciel. Les institutions devraient investir dans des ingénieurs logiciels dédiés à la recherche, reconnaître le logiciel dans les recrutements et les promotions, et fournir des plateformes d’hébergement de code bien gérées. Les financeurs sont encouragés à soutenir la maintenance à long terme des outils largement utilisés, pas seulement la création de nouveaux, et à promouvoir les licences open source par défaut pour aider à résoudre la crise de la reproductibilité. Les bibliothèques peuvent étendre leur rôle traditionnel en aidant à archiver les logiciels, à gérer les identifiants et à constituer des catalogues qui rendent les programmes importants faciles à trouver. Enfin, les éditeurs sont appelés à exiger que le code à l’origine des résultats publiés soit effectivement partagé, lié à l’article, et de plus en plus soumis à une revue, tout comme l’article lui‑même. 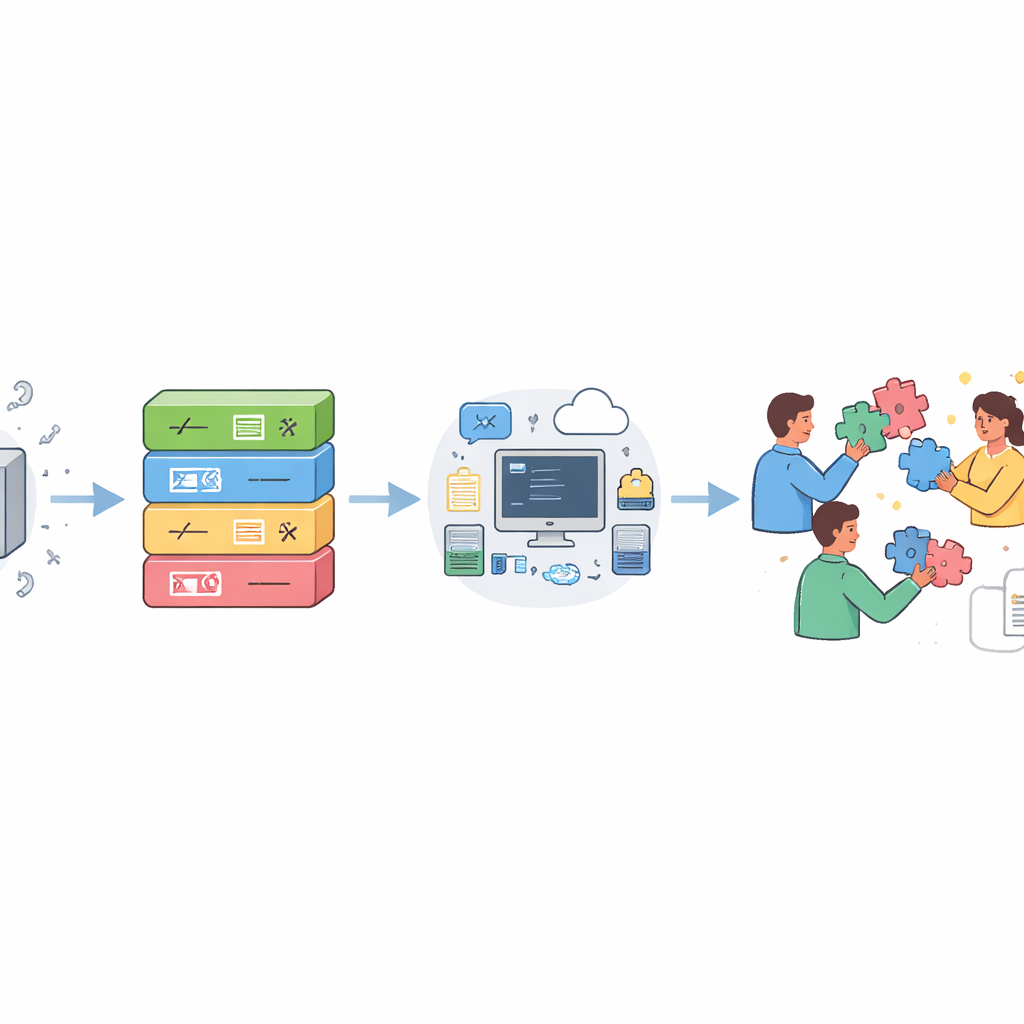
Ce que cette feuille de route signifie pour l’avenir de la science
En termes clairs, la conclusion des auteurs est que la bonne science dépend désormais du bon logiciel, et que le bon logiciel ne survient pas par accident. Leur feuille de route CODE offre un chemin réaliste depuis le patchwork actuel de scripts cachés vers un écosystème où le code de recherche est ouvert, bien expliqué, exécutable ailleurs et amélioré par de nombreuses mains. En suivant ces étapes — et en faisant jouer leur rôle aux universités, financeurs, bibliothèques et revues — la science peut se rapprocher d’un monde où les résultats ne sont pas seulement impressionnants à l’annonce, mais aussi vérifiables, réutilisables et durables pendant des années.
Citation: Di Cosmo, R., Granger, S., Hinsen, K. et al. CODE beyond FAIR: a roadmap for reusable research software. Sci Data 13, 514 (2026). https://doi.org/10.1038/s41597-026-06705-6
Mots-clés: logiciel de recherche, open source, reproductibilité, durabilité des logiciels, science ouverte