Clear Sky Science · de
CODE jenseits von FAIR: ein Fahrplan für wiederverwendbare Forschungssoftware
Warum der unsichtbare Code hinter der Wissenschaft wichtig ist
Hinter nahezu jedem modernen wissenschaftlichen Durchbruch, vom Kartieren von Galaxien bis zum Entschlüsseln von DNA, steht Software, die leise die schwere Arbeit verrichtet. Oft wird dieser Code jedoch als nachrangig behandelt: verborgen, anfällig und schwer für andere wiederzuverwenden oder zu prüfen. Dieser Artikel argumentiert, dass wir, wenn wir vertrauenswürdige und reproduzierbare Wissenschaft wollen, Forschungssoftware als ein zentrales wissenschaftliches Produkt und nicht als Einwegwerkzeug betrachten müssen. Die Autoren schlagen einen praktischen Fahrplan namens CODE vor, der Forschenden und Institutionen helfen soll, die heutigen einmaligen Skripte in verlässliche, teilbare Bausteine für die Entdeckungen von morgen zu verwandeln. 
Wie die Wissenschaft von Software abhängig wurde
Innerhalb weniger Jahrzehnte ist Software in nahezu jedem Forschungsfeld zentral geworden. Studien zeigen, dass inzwischen fast die Hälfte der wissenschaftlichen Arbeiten Software erwähnt — sei es zur Datenanalyse, zur Steuerung von Instrumenten, zur Simulation komplexer Systeme oder sogar als zentrales Forschungsergebnis. Im Gegensatz zu einem fertigen Artikel oder einem statischen Datensatz ist Software jedoch ein „lebendiges“ Objekt: Sie ändert sich, wenn Fehler behoben, Funktionen ergänzt und neue Beitragende aktiv werden. Mehrere Versionen desselben Programms koexistieren, und jede hängt von einer empfindlichen Umgebung aus Betriebssystemen und Bibliotheken ab. Eine winzige Änderung in dieser Umgebung kann Ergebnisse verändern — oder den Code vollständig zum Absturz bringen. Diese lebendige, gegenseitig abhängige Natur bedeutet, dass traditionelle Prinzipien zum Teilen von Daten, die für statische Dateien ausgelegt sind, nicht ausreichen, um Software wirklich wiederverwendbar zu machen.
Von FAIR zu CODE: ein neuer Blick auf Forschungswerkzeuge
In den letzten zehn Jahren haben die FAIR‑Prinzipien — Findable, Accessible, Interoperable, Reusable — die Handhabung von Daten verändert. Versuche, FAIR auf Software zu übertragen, haben wichtige Fortschritte gebracht, doch die Autoren argumentieren, dass Software maßgeschneiderte Leitlinien benötigt. Aufbauend auf jahrzehntelanger Erfahrung aus Frei‑ und Open‑Source‑Communities schlagen sie einen schrittweisen Fahrplan vor, der sich um vier Säulen gruppiert, die praktischerweise das Akronym CODE bilden: Open, Document, Execute, Collaborate. Statt von Anfang an perfekte Praktiken zu fordern, ist der Fahrplan gestuft, sodass Forschende mit wenig formaler Ausbildung in Softwaretechnik schrittweise bessere Gewohnheiten übernehmen können, während erfahrene Teams höhere Stufen der Robustheit und Offenheit anstreben können.
Code offen, verständlich und ausführbar machen
Unter der Säule „Open“ fordern die Autoren Forschende auf, das Verschicken von ZIP‑Dateien auf Anfrage zu beenden und stattdessen ihren Quellcode auf öffentlichen Plattformen zu veröffentlichen, die Historie verfolgen und Zusammenarbeit ermöglichen. Sie betonen die Bedeutung der Langzeitarchivierung in dedizierten Infrastrukturen, wie globalen Quellcode‑Archiven, damit Projekte verfügbar bleiben, selbst wenn ein Hosting‑Dienst eingestellt wird. Klare Open‑Source‑Lizenzen und explizite Autorennennungen sind essenziell, damit andere wissen, was rechtlich erlaubt ist und wem sie Anerkennung schulden. Die Säule „Document“ konzentriert sich darauf, Software verständlich zu machen: aussagekräftige Namen verwenden, Kommentare hinzufügen, die die Überlegungen erklären statt den Code zu wiederholen, einfache Beispiele und Tutorials bereitstellen und eine separate Referenzdokumentation für die Programmteile schreiben, mit denen Nutzer tatsächlich interagieren.
Sicherstellen, dass Ergebnisse reproduziert und geteilt werden können
Die Säule „Execute“ geht ein häufiges Ärgernis an: Code, der formal vorhanden ist, aber anderswo nicht zum Laufen gebracht werden kann. Der Fahrplan fordert Autoren auf, die Hardware und Software aufzulisten, von der ihr Programm abhängt, wiederverwendbare Rechenumgebungen anzubieten, wenn möglich (etwa durch Container oder spezialisierte Paketmanager), Test‑Suiten bereitzustellen, damit Nutzer prüfen können, ob die Software auf ihren Maschinen korrekt funktioniert, und reale, ausführbare Anwendungsfälle zu teilen, die typische Analysen abbilden. Die letzte Säule „Collaborate“ ermuntert zu offener, fortlaufender Beteiligung: auf Fehlermeldungen und Funktionswünsche reagieren, erklären, ob und wie externe Beiträge willkommen sind, ehrlich über Grenzen des Supports sein und, wenn angebracht, eine Community durch Tutorials, Workshops und Mentoring aufbauen. Zusammen verwandeln diese Schritte isolierten Forschungscode in ein gemeinsames Werkzeug, dem viele vertrauen und das viele verbessern können.
Die Rolle aller, um bessere Forschungssoftware zu unterstützen
Der Artikel macht deutlich, dass einzelne Forschende das Softwareproblem nicht allein lösen können. Institutionen sollten in dedizierte Research Software Engineers investieren, Software bei Einstellung und Beförderung anerkennen und gut verwaltete Code‑Hosting‑Plattformen bereitstellen. Geldgeber werden aufgefordert, die langfristige Wartung weit verbreiteter Werkzeuge zu unterstützen, nicht nur die Entwicklung neuer, und Open‑Source‑Lizenzen als Standard zu fördern, um die Reproduzierbarkeitskrise anzugehen. Bibliotheken können ihre traditionelle Rolle erweitern, indem sie bei der Archivierung von Software helfen, Identifikatoren verwalten und Kataloge kuratieren, die wichtige Programme leicht auffindbar machen. Verlage schließlich werden aufgefordert, zu verlangen, dass der Code hinter publizierten Ergebnissen tatsächlich geteilt, mit dem Artikel verlinkt und zunehmend überprüfbar ist — genau wie der Artikel selbst. 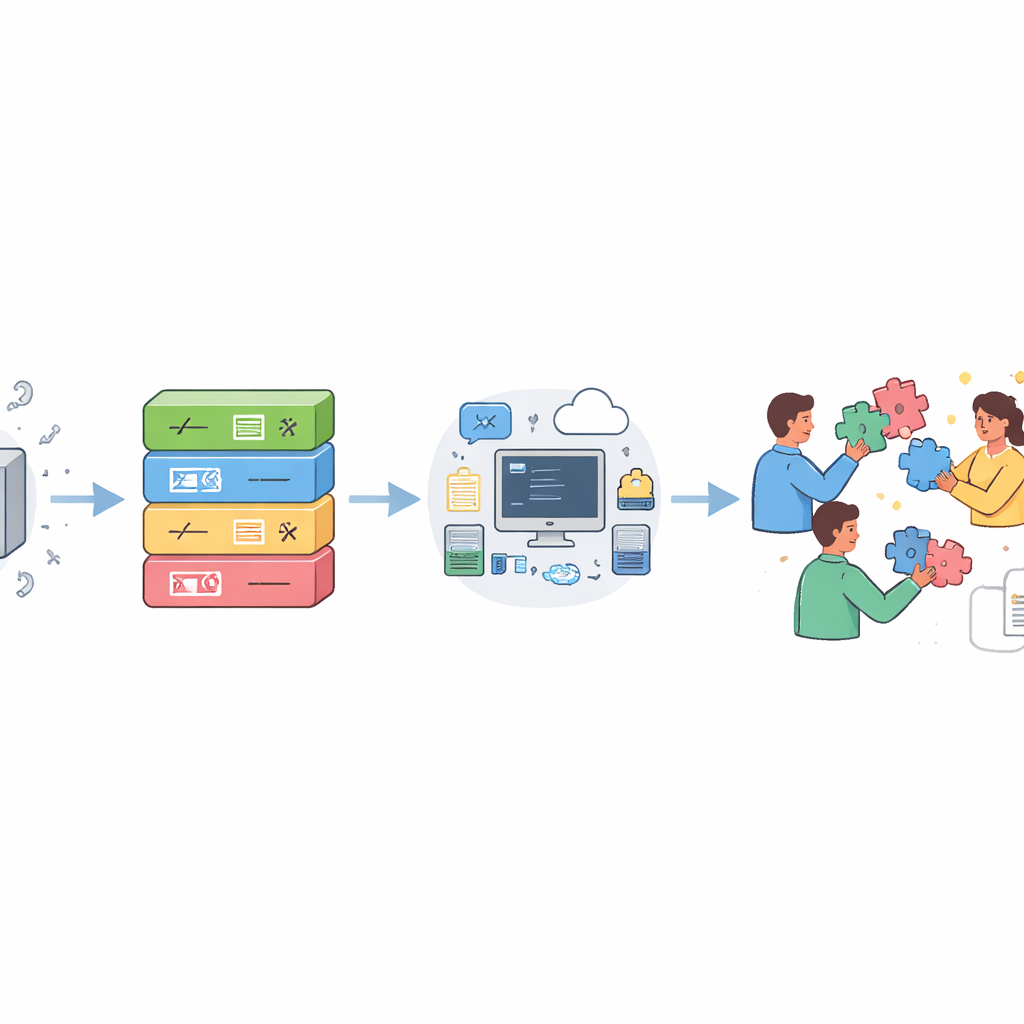
Was dieser Fahrplan für die Zukunft der Wissenschaft bedeutet
Kurz gesagt kommen die Autoren zu dem Schluss, dass gute Wissenschaft heute von guter Software abhängt, und gute Software entsteht nicht zufällig. Ihr CODE‑Fahrplan bietet einen realistischen Weg von dem heutigen Flickwerk aus verborgenen Skripten hin zu einem Ökosystem, in dem Forschungscode offen, gut erklärt, anderswo ausführbar und von vielen Händen verbessert wird. Wenn diese Schritte befolgt werden — und Universitäten, Geldgeber, Bibliotheken und Fachzeitschriften ihren Teil beitragen — kann die Wissenschaft einer Welt näherkommen, in der Ergebnisse nicht nur bei ihrer Ankündigung beeindrucken, sondern auch verifizierbar, wiederverwendbar und dauerhaft über Jahre bleiben.
Zitation: Di Cosmo, R., Granger, S., Hinsen, K. et al. CODE beyond FAIR: a roadmap for reusable research software. Sci Data 13, 514 (2026). https://doi.org/10.1038/s41597-026-06705-6
Schlüsselwörter: Forschungssoftware, Open Source, Reproduzierbarkeit, Software‑Nachhaltigkeit, Offene Wissenschaft