Clear Sky Science · en
Artificial Intelligence-powered tiered early warning framework addressing high false alarm rates for in-hospital mortality prediction
Why smarter hospital alerts matter
Anyone who has visited an emergency department knows it can feel chaotic: alarms beeping, staff rushing, and very sick patients arriving at all hours. Yet the most dangerous patients are sometimes the hardest to spot early, and computer systems meant to warn doctors often cry wolf, triggering far more false alarms than real emergencies. This study introduces a new artificial intelligence framework, called AI-TEW, designed to make hospital warning systems both sharper and quieter—so that when an alarm sounds, clinicians are far more likely to pay attention.
The problem with too many warnings
Hospitals increasingly use computer models to predict which newly admitted patients are at risk of dying during their stay. These models look impressive on paper, correctly ranking high- and low-risk patients most of the time. But in real emergency departments, in-hospital deaths are rare—typically fewer than 5 out of 100 admissions. That imbalance means even an accurate model can generate many more false alarms than true ones. Prior systems have had situations where roughly 9 out of 10 “high-risk” alerts turned out to be wrong. This blizzard of dubious warnings leads to “alert fatigue,” where nurses and doctors become desensitized, potentially missing the few truly critical cases hidden among the noise.
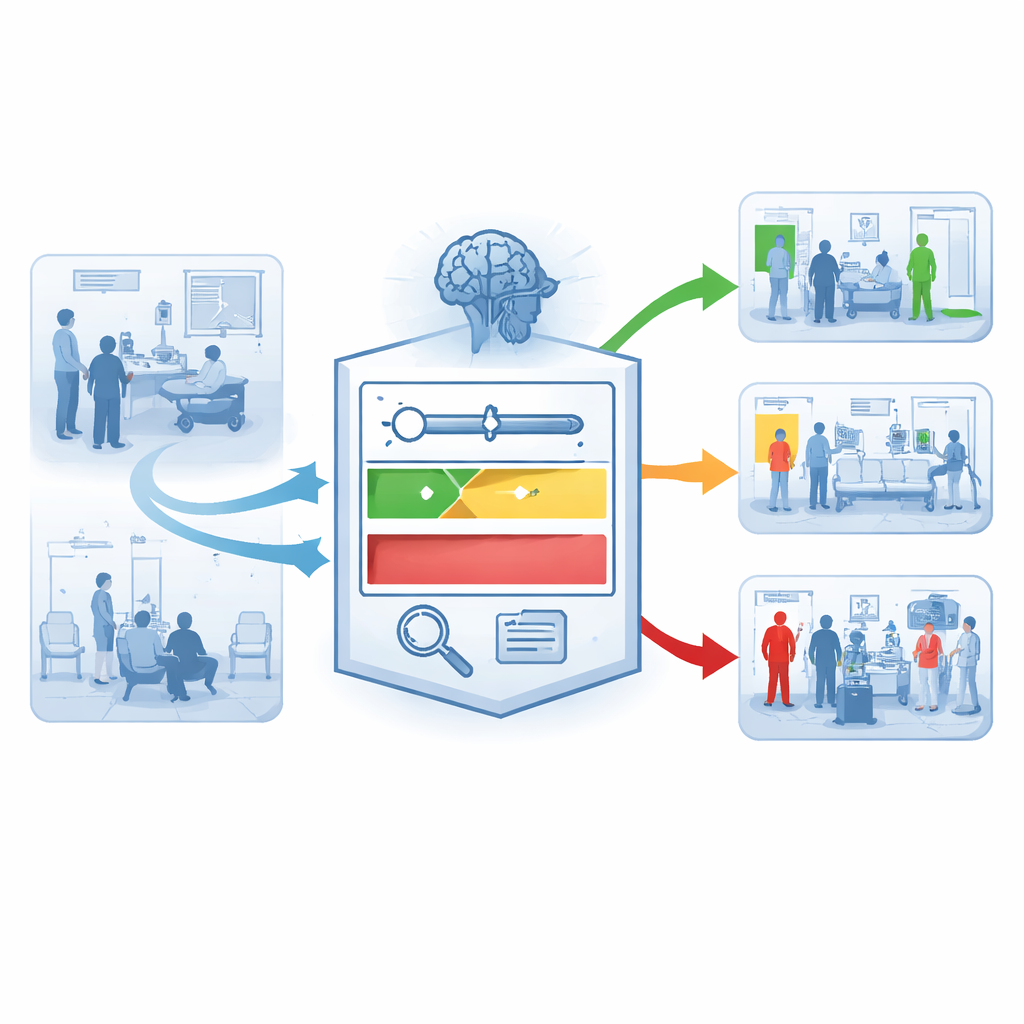
A new two-stage safety net
To tackle this, the researchers analyzed 174,292 emergency visits across three hospitals in China and the United States. They first built several machine-learning models from standard electronic health record data: age, arrival mode, triage level, vital signs such as blood pressure and oxygen level, and routine lab tests like creatinine or lactate. Among seven approaches tested, a method called LightGBM performed best, reliably separating survivors from non-survivors across hospitals and time periods. However, even this strong model still produced too many false positives when used in a simple “high-risk versus low-risk” fashion.
From one big alarm to tiers of concern
The core innovation of AI-TEW is to rethink how predictions are used, not just how they are computed. Instead of a single cut-off that labels patients “high” or “not high” risk, the system creates tiers. At Stage 1, every patient receives a risk score. At Stage 2, two thresholds split these scores into low-, medium-, and high-risk bands. The low-risk tier is tuned to be very safe—over 98–99 percent of patients in this group survive—which helps clinicians confidently de-escalate care. The high-risk tier is intentionally narrow: it covers only a small slice of patients but contains a much higher share of true deaths. In one major hospital, this strategy increased the share of true high-risk cases among those flagged (the positive predictive value) from about 11 percent to roughly 40 percent, while keeping the low-risk tier extremely reassuring. The medium-risk group is further divided into subgroups, allowing hospitals to match monitoring intensity to how worrisome a case truly appears.
Adding medical “common sense” with large language models
Even with smarter tiers, some alerts remain questionable, especially for patients whose data are incomplete or conflicting. To refine things further, the team added a third layer using large language models—the same type of AI used in advanced chatbots, but tuned for medical reasoning. For each high-risk alert, these models review a patient’s key findings and respond in one of three ways: effectively “yes, this looks genuinely high risk,” “no, this seems unlikely to be as dangerous as flagged,” or “uncertain, more human review needed.” Across internal and external tests, all language models kept sensitivity high, meaning they rarely missed true deaths, but several noticeably reduced false alarms. One model, MedGemma, lifted the accuracy of high-risk alerts to nearly one in two being correct, a major improvement over traditional approaches.
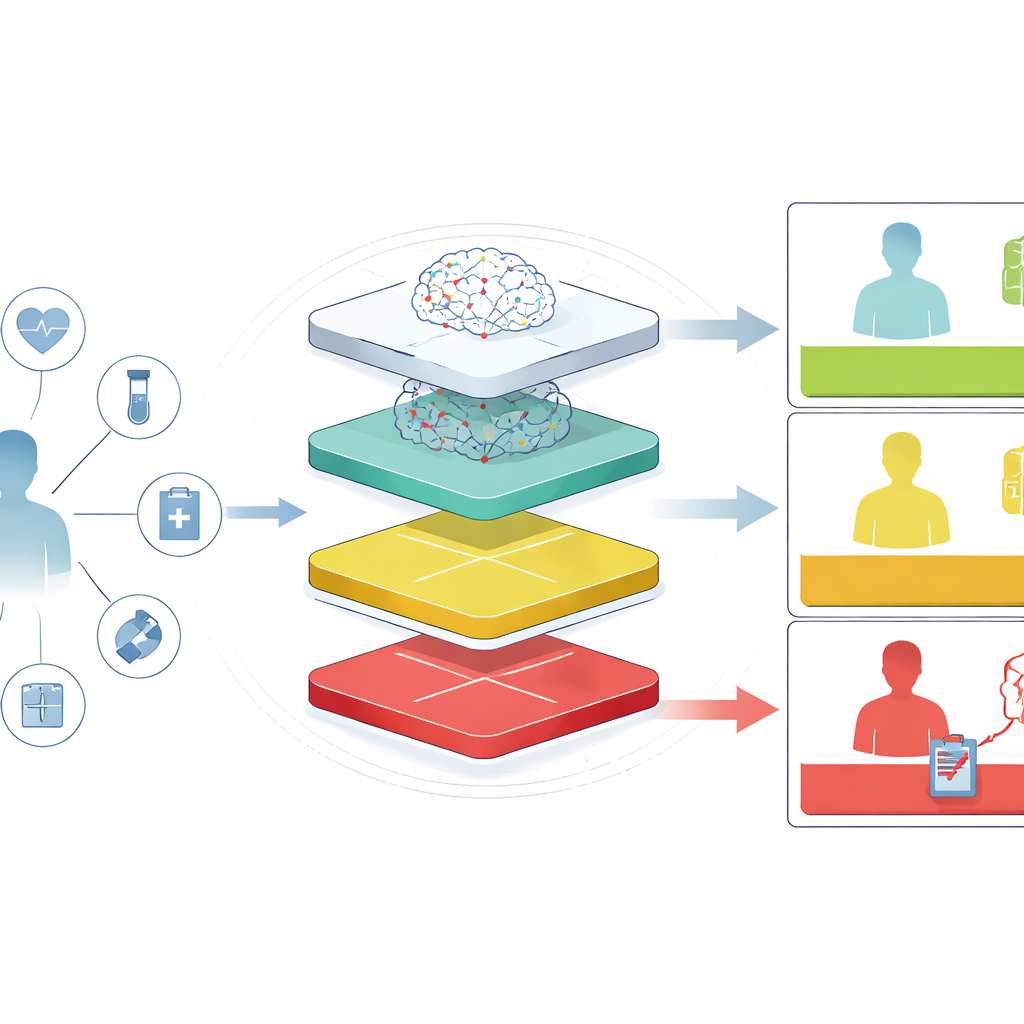
Making risk scores understandable at the bedside
Beyond raw numbers, the framework emphasizes explanations that clinicians can quickly grasp. The authors use a technique that breaks down each patient’s risk into contributing factors, highlighting, for example, that a combination of very high lactate, low albumin, and poor kidney function strongly pushes a prediction toward danger. These patterns match established medical knowledge, reassuring users that the system is not relying on mysterious or implausible signals. The language models then turn these factors into short, plain-language narratives, describing why a given patient has been placed in a particular tier and what kinds of organ failure or infection might be developing.
What this means for patients and staff
In simple terms, this study shows that in emergency care, making prediction tools useful is not only about building a clever model—it is about delivering the right kind of alert, to the right clinician, at the right moment. By combining strong machine-learning predictions, a tiered structure that focuses attention where it is most needed, and a final “reasoning” layer that weeds out weak alerts, AI-TEW turns a noisy, often-ignored warning system into a more trustworthy guide. If adopted and tested in live practice, such frameworks could help clinicians intervene earlier on truly fragile patients, reduce unnecessary panic for stable ones, and ease the cognitive burden on already stretched emergency teams.
Citation: Wu, L., Mai, L., Wang, H. et al. Artificial Intelligence-powered tiered early warning framework addressing high false alarm rates for in-hospital mortality prediction. npj Digit. Med. 9, 346 (2026). https://doi.org/10.1038/s41746-026-02522-8
Keywords: emergency department alerts, clinical risk prediction, medical artificial intelligence, large language models, in-hospital mortality