Clear Sky Science · en
A surrogate-based inverse design framework for targeted diameter control of electrospun nanofibers
Why tiny fibers matter
Many everyday technologies, from air filters and medical bandages to sensors and batteries, rely on mats of extremely thin threads called nanofibers. How thick these fibers are—often just a few hundred billionths of a meter across—strongly affects how well they filter particles, guide cells to grow, or store energy. Yet dialing in the exact fiber thickness usually means tedious trial-and-error in the lab. This paper introduces a smarter, computer-guided way to design nanofibers with chosen diameters quickly and reliably, potentially speeding up innovation in many products that depend on these delicate structures.
From spinning jets to smart design
The study focuses on electrospinning, a widely used method for making continuous nanofibers. In a typical setup, a high voltage pulls a thin jet of polymer solution out of a needle toward a collector, stretching it into fine fibers as the solvent evaporates. Adjusting the solution recipe, the applied voltage, the flow rate, and the distance to the collector can make fibers thicker or thinner, smoother or more porous. But these knobs interact in complex, nonlinear ways, so small changes can give unpredictable results. Instead of relying on rules of thumb, the authors propose building a “digital twin” of the process that can predict fiber diameter from a limited set of well-chosen experiments, and then using this twin in reverse to find the settings that produce a desired thickness. 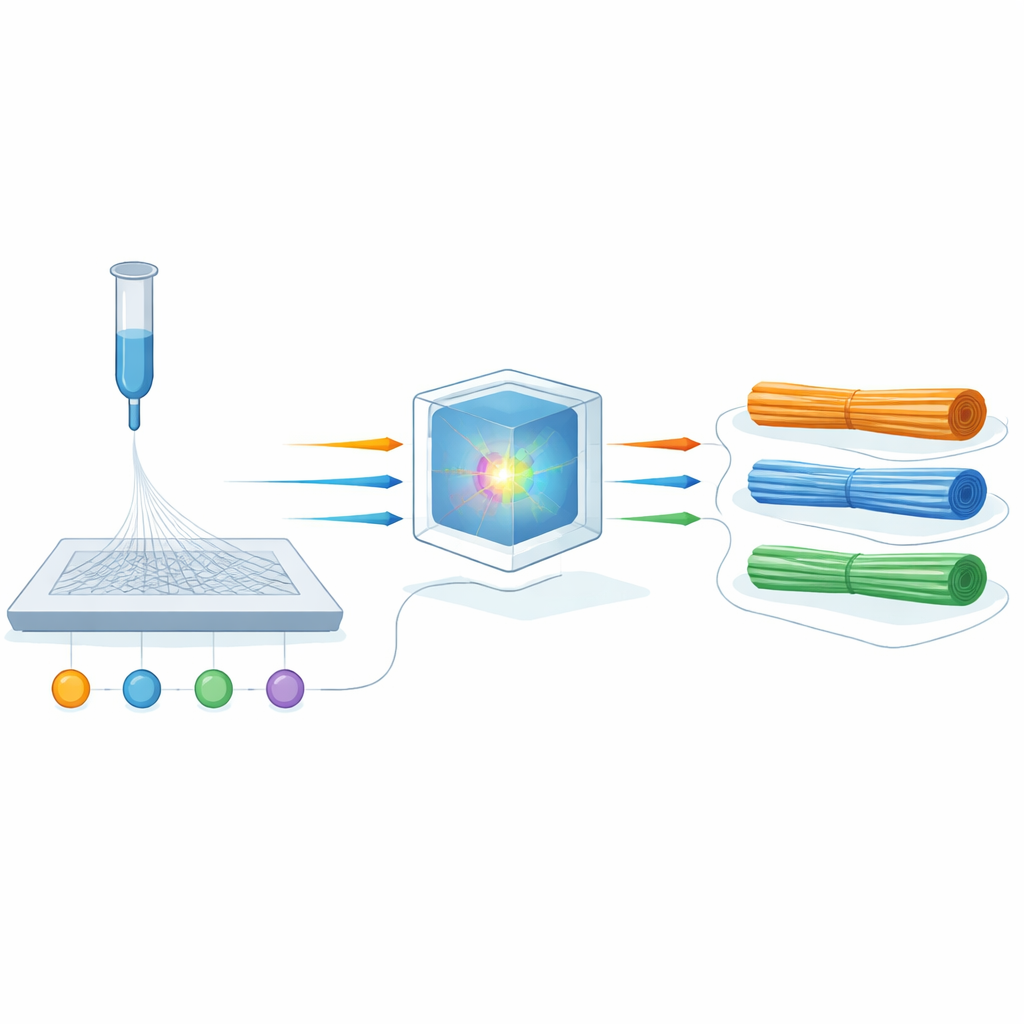
Building a digital twin of the fiber process
To construct this digital twin, the team used an existing, carefully designed data set of 96 electrospinning experiments on poly(vinyl alcohol), a common water-soluble polymer. Each experiment varied four key process parameters: solution concentration, applied voltage, flow rate, and tip-to-collector distance, and recorded the resulting average fiber diameter, which ranged from about 200 to 350 nanometers. The researchers tested eleven different machine-learning methods to see which could best learn the relationship between the four inputs and the fiber diameter. These ranged from simple linear fits to more flexible “ensemble” models that combine many small decision trees.
Finding what really controls fiber size
Among all the models, an algorithm called Extreme Gradient Boosting (XGBoost) performed best, explaining about 89 percent of the variation in fiber diameter on previously unseen data. To make sure this model was not just accurate but also physically sensible, the authors used an interpretability tool known as SHAP analysis. This approach estimates how much each input contributes to the prediction. It revealed that applied voltage and solution concentration dominate fiber thickness: higher voltage tends to stretch the jet more, making thinner fibers, while higher concentration (and thus thicker, more viscous solution) resists stretching and produces thicker fibers. Flow rate and distance mattered less but still nudged the diameter, in line with what experimentalists have long observed.
Letting algorithms search for the right recipe
With the surrogate model in place, the team tackled the “inverse design” problem: given a target diameter, what process settings should you use? They framed this as minimizing the gap between the diameter predicted by the model and the desired value, while keeping all parameters within realistic ranges. Seven optimization strategies were compared, from brute-force grid scanning and simple random search to advanced population-based methods that iteratively refine many candidate solutions. A technique called Particle Swarm Optimization (PSO), which mimics a group of particles exploring a landscape and sharing information, emerged as the clear winner. It reached target diameters with extremely small errors—on average within about 2 nanometers—and did so consistently across repeated runs, all while keeping computation times modest. 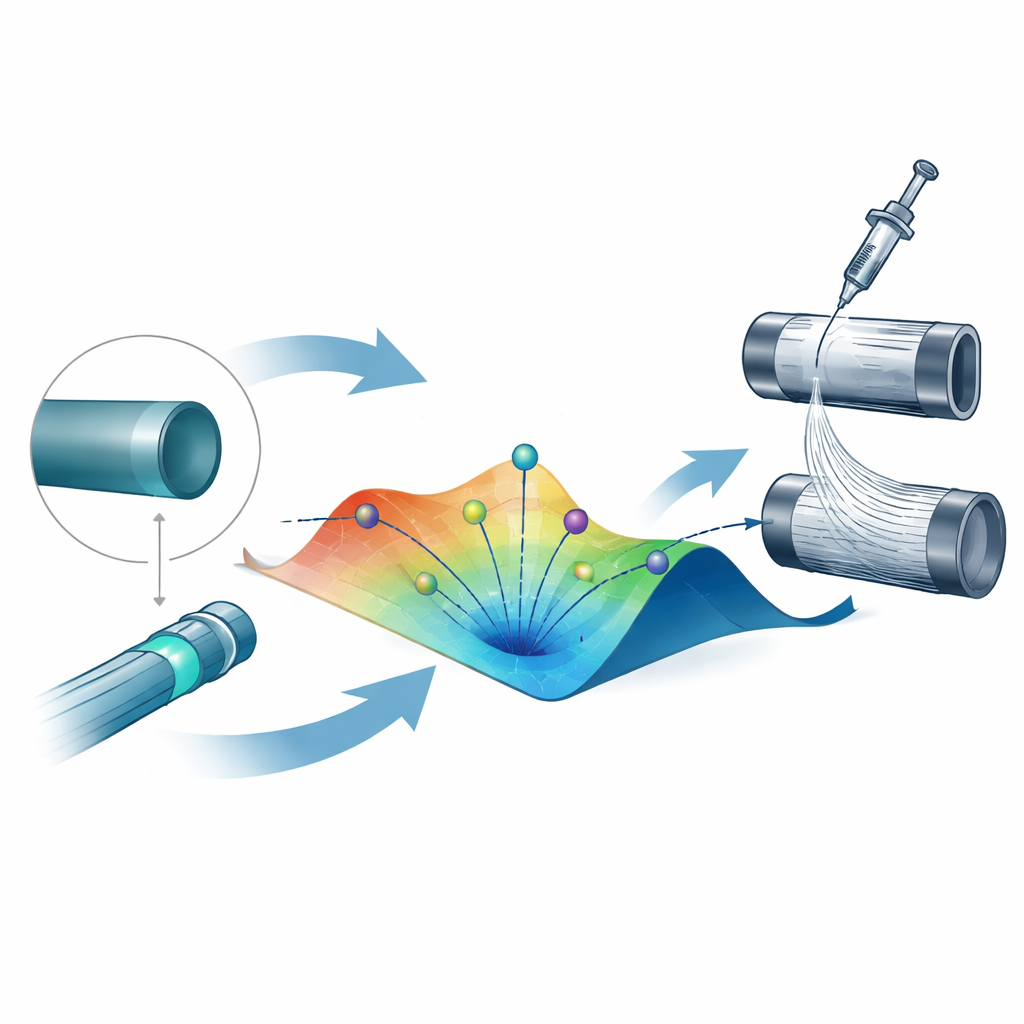
Limitations and room to grow
The framework is currently tuned to one polymer in a controlled lab environment, so it cannot yet predict behavior for entirely different materials or changing room conditions such as humidity. The data set, though carefully planned, is also relatively small and lacks repeated measurements under identical conditions, which would help quantify natural variability. The authors argue that adding more experiments, including different polymers and ambient conditions, and feeding new results back into the model will make the digital twin more general and reliable. They also suggest extending the method to control not just diameter but other features, such as fiber strength or surface texture, and to incorporate practical manufacturing constraints directly into the optimization.
What this means for future materials
By combining a data-driven digital twin with a powerful search algorithm, this work turns electrospinning from an art guided by experience into a more predictable design task. Instead of performing dozens of trial runs to hit the right fiber size, researchers or engineers could specify a target and let the computer propose viable process settings in seconds, then validate only a few suggestions experimentally. While demonstrated on nanofibers, the same strategy—learning from a compact set of experiments, then using that knowledge in reverse—could accelerate the design of many other materials and processes, helping new filters, scaffolds, batteries, and coatings move from concept to reality more quickly.
Citation: Mahdian, M., Ender, F. & Pardy, T. A surrogate-based inverse design framework for targeted diameter control of electrospun nanofibers. Sci Rep 16, 11034 (2026). https://doi.org/10.1038/s41598-026-40692-3
Keywords: electrospinning, nanofibers, inverse design, machine learning, process optimization