Clear Sky Science · zh
将癌症数据协调到观察性医疗结果合作通用数据模型的过程
为何汇聚癌症数据至关重要
癌症护理会产生来自医院、登记处、实验室,甚至患者问卷的大量信息,但这些记录通常以不同格式存储,彼此难以“对话”。本文解释了研究者如何设计一个清晰的逐步流程,将这些分散的癌症信息转为单一且组织良好的格式,从而更可靠地用于治疗模式、生存率和人群健康的研究。
多个数据孤岛,而非一幅共享全景
癌症数据异常详尽,描述肿瘤类型、分期、基因标志物、随时间的治疗、药物副作用和结局等,来源包括电子病历、癌症登记、保险理赔、生物样本库和问卷等。由于每个来源使用不同的结构和命名规则,合并困难,常导致信息缺失或含义丢失。观察性医疗结果合作通用数据模型(OMOP CDM)为健康数据提供了共享结构,且在全球范围内被日益采用。然而,关于如何将癌症数据迁入该模型的现有指南较为笼统,团队往往需要自行设计本地解决方案。
以往项目揭示的经验
作者回顾了20个项目,这些项目来自学术期刊和国际数据科学社区的报告,曾尝试将癌症数据转换为 OMOP 格式。大多数项目要么侧重于患者层面的研究,如特定治疗的结局评估,要么关注群体层面的问题,如生存趋势和疾病监测。癌症登记和医院记录是最常见的数据来源,通常来自欧洲中心,美洲和亚洲的实例较少。许多团队使用 OMOP 社区的专用软件工具来探索源数据、设计映射、检查质量并推导治疗方案,但他们组织工作的方式差异很大。
反复出现的主要障碍
在这些项目中,三类问题反复出现。首先,起始数据混乱或不完整:重要细节缺失、记录为自由文本或分散在多个系统中,合并多个来源需要大量清理和整理。其次,将本地编码和描述映射到 OMOP 标准术语难度大,尤其是对于分期、标志物结果和复杂药物组合等丰富的癌症细节;标准词汇有时不够细化,自由文本或基因组数据需要额外工具和专家参与。第三,一旦建立了映射,它并非静态;通用数据模型、词汇表和工具更新迅速,团队需要规划以保持系统随时间更新。
为团队提供的五步路线图
基于回顾中总结的模式和癌症数据专家的反馈,作者提炼出一个针对肿瘤学的通用五步协调流程。第一步“启动”(Initiation)包括组建跨学科团队、明确研究目标、了解本地规则并熟悉 OMOP 生态。需求分析(Requirement Analysis)深入审查源数据:数据类型、结构、完整性与可信度,以及最大风险所在。设计规划(Design Planning)将这些认知转化为详细的转换与映射计划,包括使用哪些工具、如何处理诸如治疗过程等就诊序列,以及如何评估成效。
从原始记录到可用的研究数据
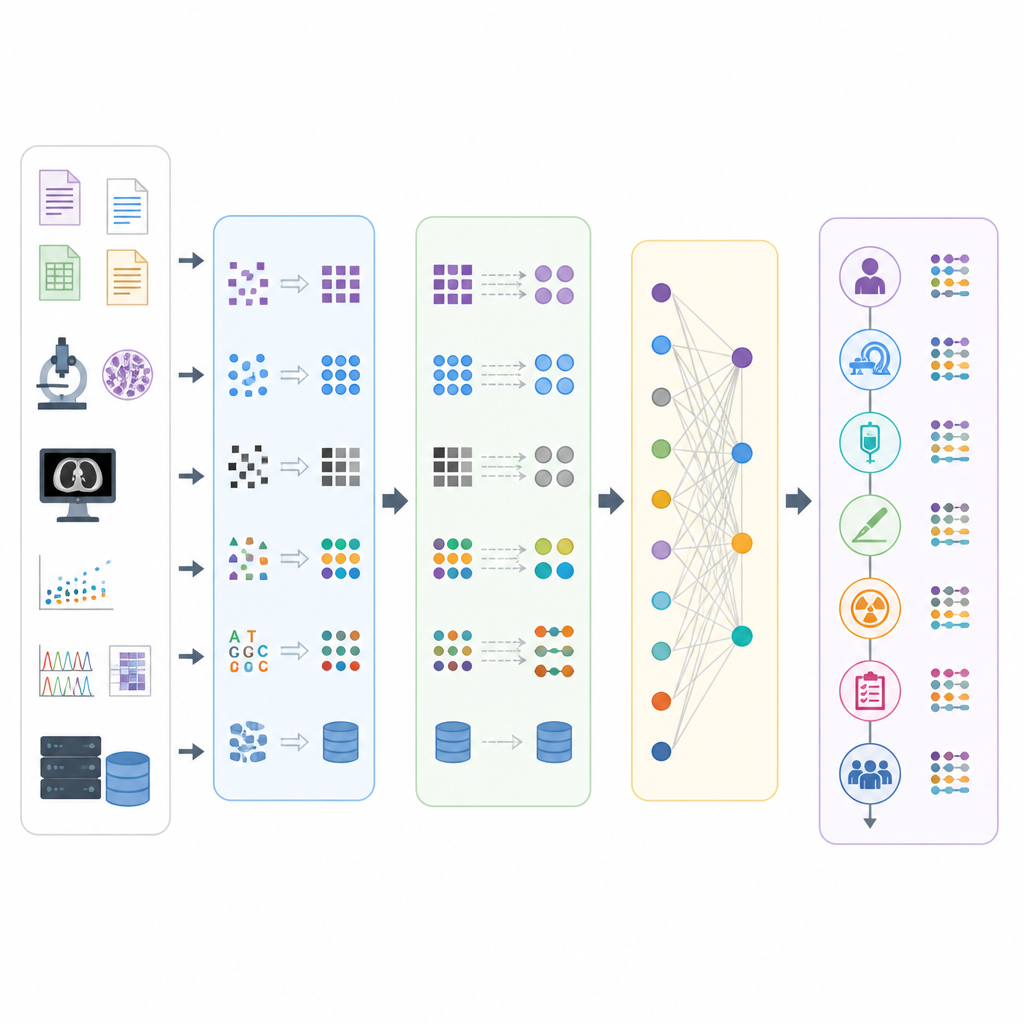
第四步“技术实施”(Technical Implementation)将计划付诸实践。团队在此阶段清理并整理数据、提取相关要素、将其转换为 OMOP 表并以系统化方式进行质量检查。特别重视使用 OMOP 表构建每位患者癌症历程的时间线,这些表表示就诊序列及其关联事件,如诊断、操作和药物暴露。第五步“维护”(Maintenance)认识到工作永无止境:词汇、软件工具和肿瘤学知识都在变化,因此团队必须安排更新、监控新问题并不断细化映射与约定。两个贯穿始终的原则支撑所有步骤:反复的测试与改进循环,以及对决策进行详尽记录,以确保工作的透明性与可复用性。
对患者和研究者的意义
对普通读者而言,核心信息是:更好地利用现有癌症数据,不在于新的设备,而在于谨慎且共享的信息组织方法。本文提供了一个可被任何医院或研究机构采用的实用路线图,帮助将分散的癌症记录整合为通用格式,同时尊重本地规则与技术。通过简化跨中心和跨国汇聚数据的过程,该流程旨在支持更可靠的研究,了解癌症的治疗方式与患者在日常实践中的结局,帮助临床医生与决策者在更清晰、更完整的基础上作出判断。
引用: Nada, I.P., Bonacina, S. Data harmonization processes of cancer data into the observational medical outcomes partnership common data model. Sci Rep 16, 15993 (2026). https://doi.org/10.1038/s41598-026-53570-9
关键词: 癌症数据, OMOP 通用数据模型, 数据协调, 真实世界证据, 健康信息学