Clear Sky Science · en
Data harmonization processes of cancer data into the observational medical outcomes partnership common data model
Why bringing cancer data together matters
Cancer care generates huge amounts of information from hospitals, registries, labs, and even patient questionnaires, but these records are often stored in different formats that cannot easily "talk" to one another. This article explains how researchers designed a clear, step by step process to turn this scattered cancer information into a single, well organized format so that it can be used more reliably for studies of treatment patterns, survival, and population health.
Many data islands instead of one shared picture
Cancer data are unusually detailed. They describe tumor type, stage, genetic markers, treatments over time, side effects, and outcomes, and they come from many places such as electronic health records, cancer registries, insurance claims, biobanks, and questionnaires. Because each source uses its own structure and naming rules, combining them is difficult and often results in gaps or loss of meaning. The Observational Medical Outcomes Partnership Common Data Model, or OMOP CDM, offers a shared structure for health data, and it is increasingly used worldwide. However, existing guidance on how to move cancer data into this model has been general, leaving teams to invent their own local solutions.
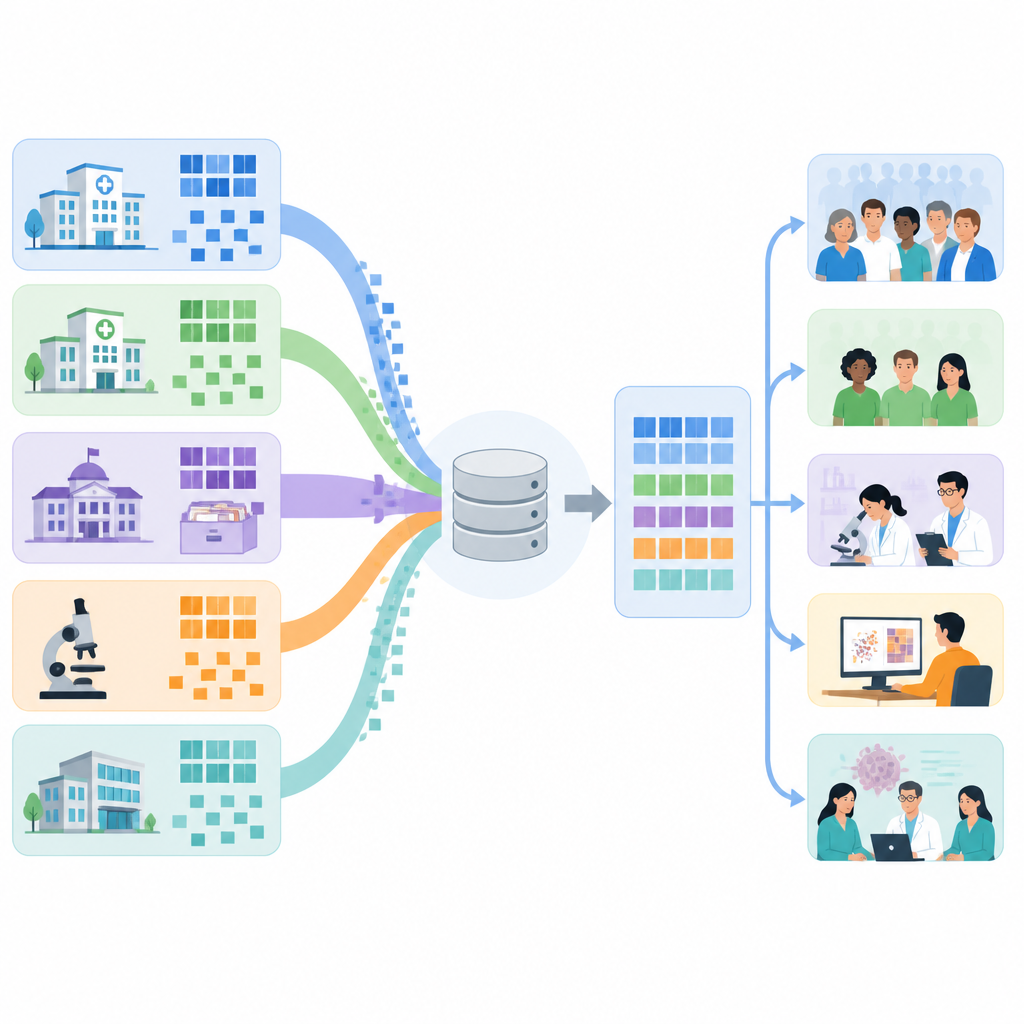
What earlier projects reveal
The authors reviewed 20 projects, drawn from scientific journals and presentations from an international data science community, that had already tried to convert cancer data into the OMOP format. Most focused on either patient level research, such as studying outcomes of specific treatments, or on population level questions like survival trends and disease monitoring. Cancer registries and hospital records were the most common data sources, usually from European centers, with fewer examples from the Americas and Asia. Many teams used specialized software tools from the OMOP community to explore source data, design mappings, check quality, and derive treatment regimens, but the ways they organized their work differed widely.
Key obstacles that keep surfacing
Across these projects, three kinds of problems appeared again and again. First, the starting data were messy or incomplete: important details were missing, stored in free text, or spread across several systems, and combining multiple sources required heavy cleaning and curation. Second, mapping local codes and descriptions to standard OMOP terms was hard, especially for rich cancer details such as staging, biomarker results, and complex drug combinations; the standard vocabularies were sometimes not fine grained enough, and free text or genomic data needed extra tools and expert input. Third, once a mapping was built, it did not stay still; the common data model, vocabularies, and tools evolve quickly, so teams needed plans to keep their systems up to date over time.
A five step roadmap for teams
Using patterns from the review and feedback from cancer data experts, the authors distilled a generic five step harmonization process tailored to oncology. The first step, Initiation, covers forming an interdisciplinary team, agreeing on the research purpose, understanding local rules, and getting familiar with the OMOP ecosystem. Requirement Analysis then digs into the source data: what kinds of data exist, how they are structured, how complete and trustworthy they are, and where the biggest risks lie. Design Planning translates this understanding into a detailed plan for how to transform and map the data, what tools to use, how to handle episodes of care such as treatment courses, and how to evaluate success.
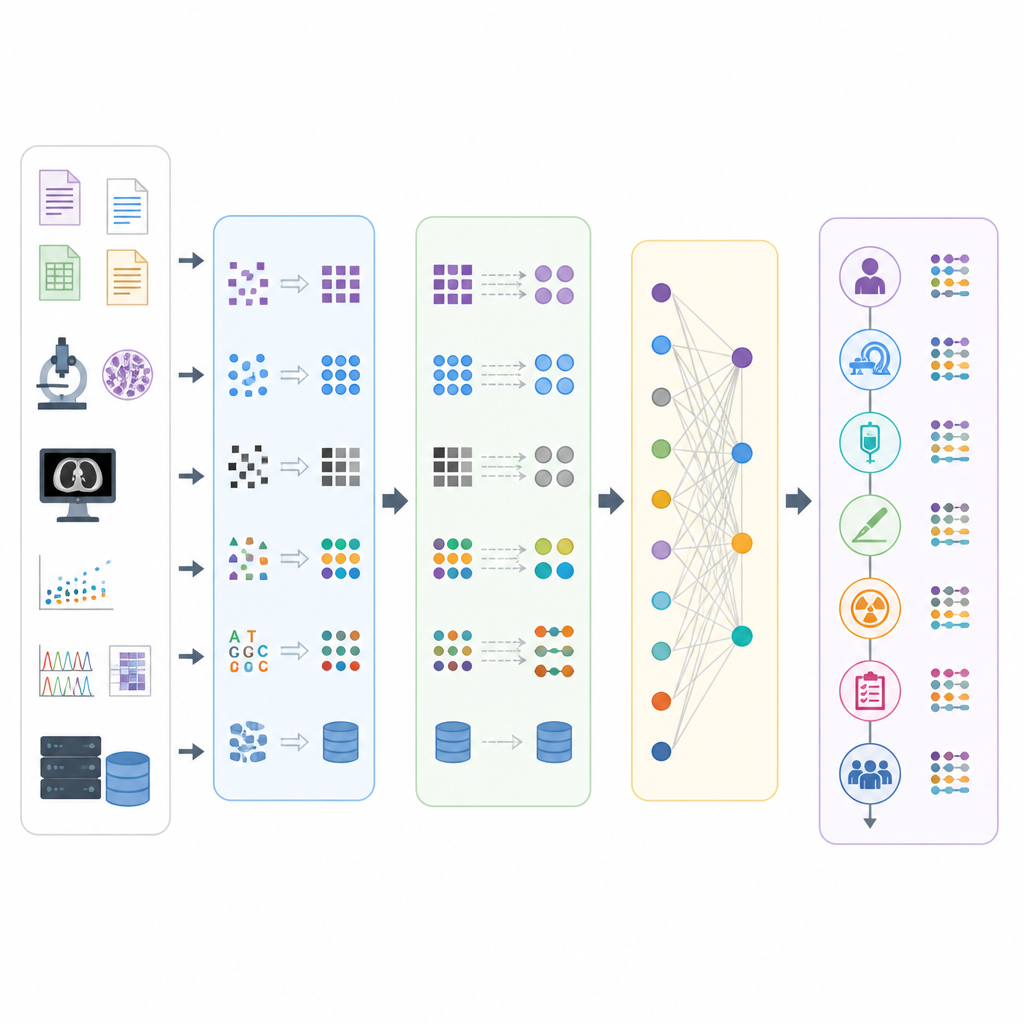
From raw records to usable research data
The fourth step, Technical Implementation, puts the plan into action. Here teams clean and curate the data, extract relevant pieces, transform them into the OMOP tables, and check quality in a systematic way. Special attention is given to building timelines of each patient’s cancer journey using OMOP tables that represent episodes and their linked events, such as diagnoses, procedures, and drug exposures. The fifth step, Maintenance, recognizes that the work is never finished: vocabularies, software tools, and oncology knowledge all change, so teams must schedule updates, monitor for new issues, and refine their mappings and conventions. Two cross cutting principles support all steps: repeating cycles of testing and improvement, and careful documentation of decisions so that work is transparent and reusable.
What this means for patients and researchers
For lay readers, the main message is that better use of existing cancer data depends less on new gadgets and more on careful, shared methods for organizing information. This article offers a practical roadmap that any hospital or research group can adapt to bring scattered cancer records into a common format, while respecting local rules and technology. By making it easier to pool data across centers and countries, the proposed process aims to support more reliable studies on how cancers are treated and how patients fare in everyday practice, helping clinicians and policymakers base decisions on a clearer and more complete picture.
Citation: Nada, I.P., Bonacina, S. Data harmonization processes of cancer data into the observational medical outcomes partnership common data model. Sci Rep 16, 15993 (2026). https://doi.org/10.1038/s41598-026-53570-9
Keywords: cancer data, OMOP common data model, data harmonization, real world evidence, health informatics