Clear Sky Science · pt
Processos de harmonização de dados de câncer para o modelo de dados comum Observational Medical Outcomes Partnership
Por que reunir dados de câncer importa
O cuidado oncológico gera enormes quantidades de informação vindas de hospitais, registros, laboratórios e até questionários de pacientes, mas esses registros frequentemente são armazenados em formatos distintos que não conseguem "conversar" facilmente entre si. Este artigo explica como pesquisadores desenharam um processo claro e passo a passo para transformar essas informações dispersas sobre câncer em um único formato bem organizado, de modo que possam ser usados de forma mais confiável em estudos sobre padrões de tratamento, sobrevida e saúde populacional.
Muitas ilhas de dados em vez de uma imagem compartilhada
Os dados de câncer são excepcionalmente detalhados. Eles descrevem tipo de tumor, estágio, marcadores genéticos, tratamentos ao longo do tempo, efeitos colaterais e desfechos, e provêm de muitos locais como prontuários eletrônicos, registros de câncer, reclamações de seguro, biobancos e questionários. Como cada fonte usa sua própria estrutura e regras de nomenclatura, combiná-las é difícil e frequentemente resulta em lacunas ou perda de significado. O Observational Medical Outcomes Partnership Common Data Model, ou OMOP CDM, oferece uma estrutura compartilhada para dados de saúde e vem sendo cada vez mais adotado mundialmente. No entanto, as orientações existentes sobre como migrar dados de câncer para esse modelo têm sido gerais, deixando as equipes à mercê de soluções locais inventadas ad hoc.
O que projetos anteriores revelam
Os autores revisaram 20 projetos, extraídos de periódicos científicos e apresentações de uma comunidade internacional de ciência de dados, que já haviam tentado converter dados de câncer para o formato OMOP. A maioria se concentrou tanto em pesquisas a nível do paciente, como estudar desfechos de tratamentos específicos, quanto em perguntas a nível populacional, como tendências de sobrevivência e monitoramento de doenças. Registros de câncer e prontuários hospitalares foram as fontes de dados mais comuns, geralmente de centros europeus, com menos exemplos das Américas e da Ásia. Muitas equipes usaram ferramentas de software especializadas da comunidade OMOP para explorar dados de origem, projetar mapeamentos, checar qualidade e derivar regimes de tratamento, mas as maneiras como organizaram o trabalho variaram amplamente.
Principais obstáculos que continuam surgindo
Ao longo desses projetos, três tipos de problema apareceram repetidamente. Primeiro, os dados iniciais eram bagunçados ou incompletos: detalhes importantes estavam ausentes, armazenados em texto livre ou dispersos por vários sistemas, e combinar múltiplas fontes exigia limpeza e curadoria intensas. Segundo, mapear códigos e descrições locais para termos padrão do OMOP foi difícil, especialmente para detalhes oncológicos ricos como estadiamento, resultados de biomarcadores e combinações complexas de medicamentos; os vocabulários padrão às vezes não eram suficientemente granulares, e texto livre ou dados genômicos demandavam ferramentas adicionais e aporte de especialistas. Terceiro, uma vez que um mapeamento era construído, ele não permanecia estático: o modelo de dados comum, os vocabulários e as ferramentas evoluem rapidamente, então as equipes precisavam de planos para manter seus sistemas atualizados ao longo do tempo.
Um roteiro em cinco etapas para as equipes
Com base em padrões observados na revisão e no retorno de especialistas em dados oncológicos, os autores destilaram um processo genérico de harmonização em cinco etapas, adaptado à oncologia. A primeira etapa, Iniciação, abrange a formação de uma equipe interdisciplinar, o consenso sobre o propósito da pesquisa, a compreensão das regras locais e a familiarização com o ecossistema OMOP. A Análise de Requisitos aprofunda-se nos dados de origem: que tipos de dados existem, como são estruturados, quão completos e confiáveis são e onde residem os maiores riscos. O Planejamento de Design traduz esse entendimento em um plano detalhado sobre como transformar e mapear os dados, quais ferramentas usar, como lidar com episódios de cuidado, como cursos de tratamento, e como avaliar o sucesso.
De registros brutos a dados de pesquisa utilizáveis
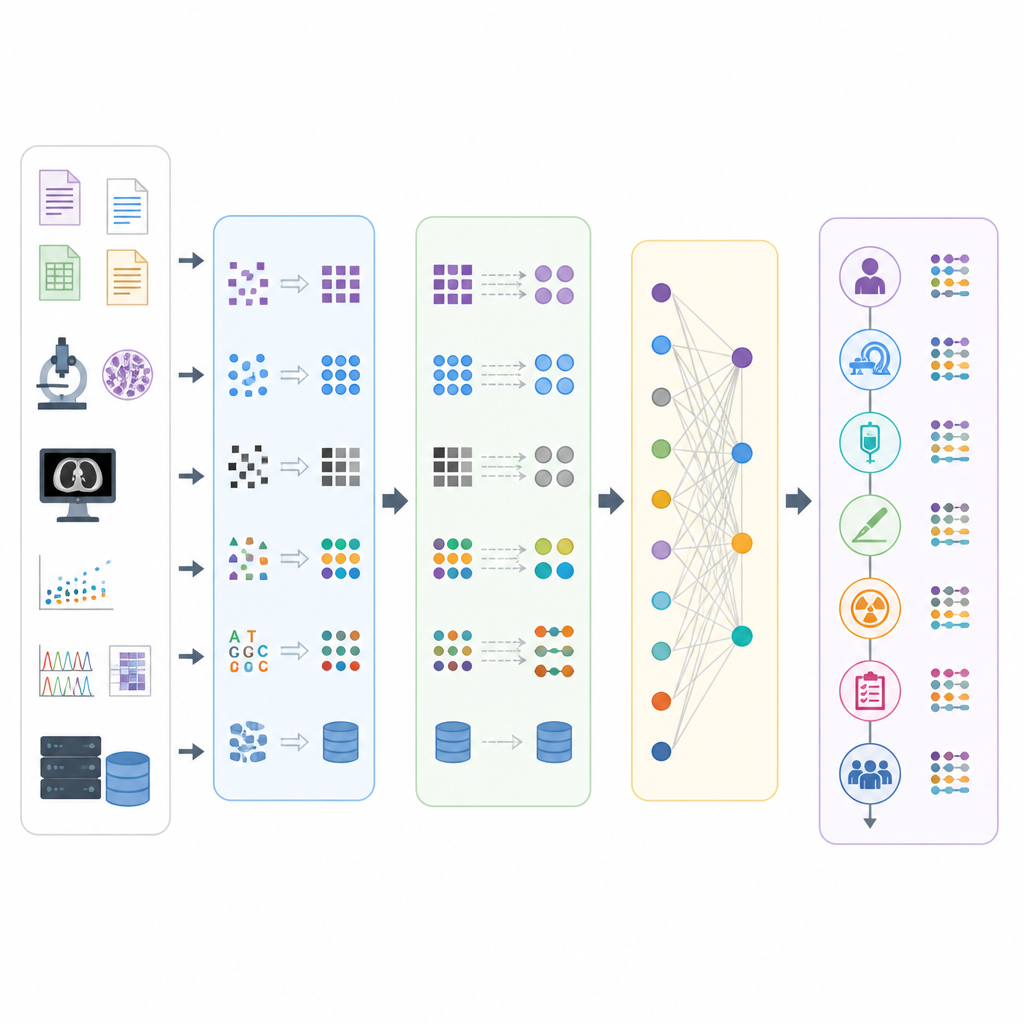
A quarta etapa, Implementação Técnica, coloca o plano em prática. Nessa fase, as equipes limpam e curam os dados, extraem os trechos relevantes, transformam-nos nas tabelas OMOP e checam a qualidade de forma sistemática. Atenção especial é dada à construção de linhas do tempo da jornada oncológica de cada paciente usando as tabelas OMOP que representam episódios e seus eventos vinculados, como diagnósticos, procedimentos e exposições a medicamentos. A quinta etapa, Manutenção, reconhece que o trabalho nunca está concluído: vocabulários, ferramentas de software e conhecimentos em oncologia mudam, então as equipes devem agendar atualizações, monitorar novos problemas e aprimorar seus mapeamentos e convenções. Dois princípios transversais apoiam todas as etapas: ciclos repetidos de teste e melhoria e documentação cuidadosa das decisões para que o trabalho seja transparente e reutilizável.
O que isso significa para pacientes e pesquisadores
Para leitores leigos, a mensagem principal é que fazer melhor uso dos dados existentes sobre câncer depende menos de novos aparelhos e mais de métodos compartilhados e cuidadosos para organizar a informação. Este artigo oferece um roteiro prático que qualquer hospital ou grupo de pesquisa pode adaptar para reunir registros dispersos de câncer em um formato comum, respeitando regras e tecnologias locais. Ao facilitar o agrupamento de dados entre centros e países, o processo proposto busca apoiar estudos mais confiáveis sobre como os cânceres são tratados e como os pacientes se saem na prática cotidiana, ajudando clínicos e formuladores de políticas a fundamentar decisões em uma imagem mais clara e completa.
Citação: Nada, I.P., Bonacina, S. Data harmonization processes of cancer data into the observational medical outcomes partnership common data model. Sci Rep 16, 15993 (2026). https://doi.org/10.1038/s41598-026-53570-9
Palavras-chave: dados sobre câncer, modelo de dados comum OMOP, harmonização de dados, evidência do mundo real, informática em saúde