Clear Sky Science · fr
Processus d'harmonisation des données sur le cancer dans le modèle de données commun OMOP
Pourquoi il est important de regrouper les données sur le cancer
La prise en charge du cancer génère d'énormes volumes d'informations provenant d'hôpitaux, de registres, de laboratoires et même de questionnaires patients, mais ces dossiers sont souvent stockés dans des formats différents qui ne « communiquent » pas facilement entre eux. Cet article explique comment des chercheurs ont conçu un processus clair et étape par étape pour convertir ces informations dispersées sur le cancer en un format unique et bien organisé afin qu'elles puissent être utilisées de manière plus fiable pour des études sur les schémas de traitement, la survie et la santé des populations.
De nombreuses îles de données au lieu d'un panorama partagé
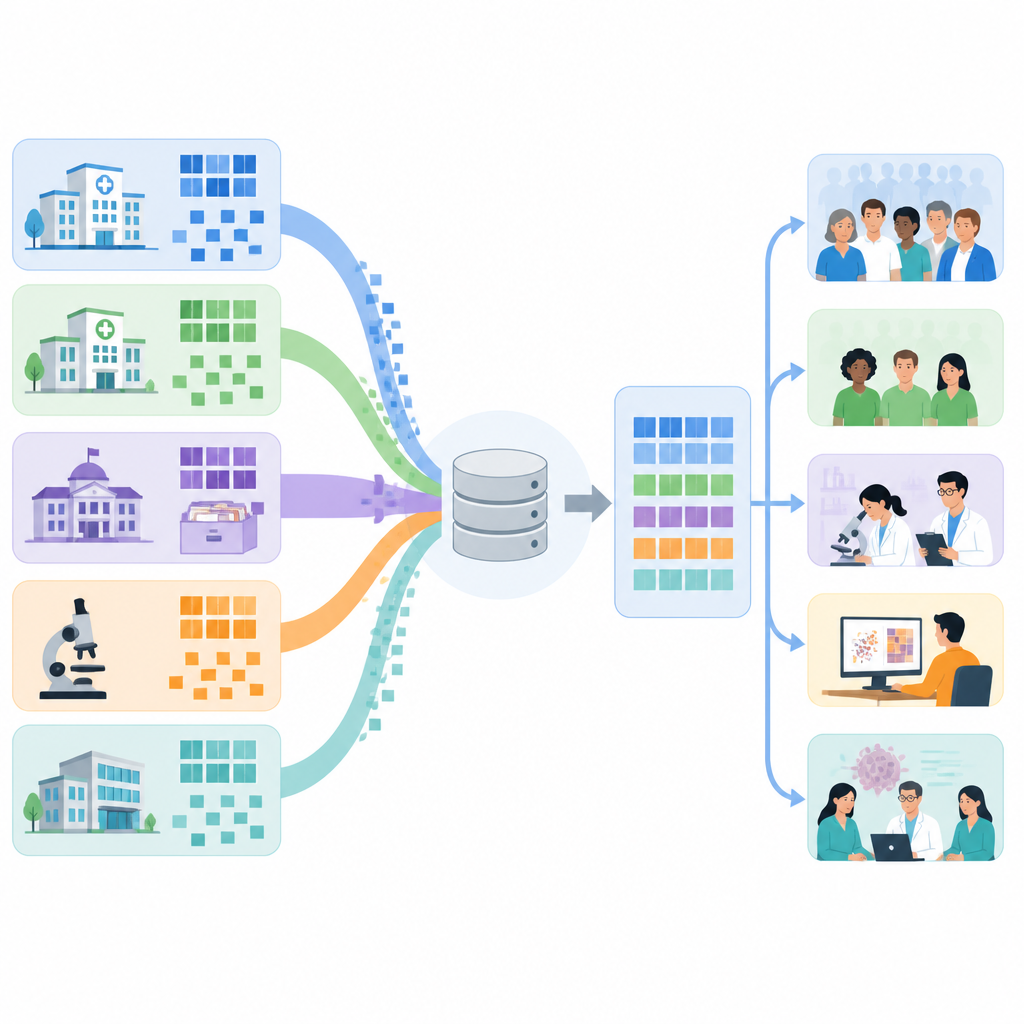
Les données sur le cancer sont exceptionnellement détaillées. Elles décrivent le type de tumeur, le stade, les marqueurs génétiques, les traitements dans le temps, les effets secondaires et les résultats, et proviennent de nombreux lieux tels que les dossiers de santé électroniques, les registres de cancer, les réclamations d'assurance, les biobanques et les questionnaires. Parce que chaque source utilise sa propre structure et ses propres règles de dénomination, les combiner est difficile et se traduit souvent par des lacunes ou une perte de sens. Le modèle de données commun de l'Observational Medical Outcomes Partnership, ou OMOP CDM, propose une structure partagée pour les données de santé et est de plus en plus utilisé dans le monde. Cependant, les recommandations existantes sur la manière d'intégrer les données sur le cancer dans ce modèle sont restées générales, laissant les équipes inventer leurs propres solutions locales.
Ce que révèlent les projets antérieurs
Les auteurs ont examiné 20 projets, issus d'articles scientifiques et de présentations d'une communauté internationale de science des données, qui avaient déjà tenté de convertir des données sur le cancer au format OMOP. La plupart se concentraient soit sur la recherche au niveau du patient, comme l'étude des résultats de traitements spécifiques, soit sur des questions au niveau populationnel comme les tendances de survie et la surveillance des maladies. Les registres de cancer et les dossiers hospitaliers étaient les sources de données les plus fréquentes, généralement issues de centres européens, avec moins d'exemples en Amérique et en Asie. De nombreuses équipes ont utilisé des outils logiciels spécialisés de la communauté OMOP pour explorer les données sources, concevoir des mappages, vérifier la qualité et déduire des schémas thérapeutiques, mais les manières d'organiser leur travail variaient largement.
Principaux obstacles récurrents
Dans ces projets, trois types de problèmes sont apparus à plusieurs reprises. D'abord, les données de départ étaient désordonnées ou incomplètes : des détails importants manquaient, étaient stockés en texte libre ou répartis sur plusieurs systèmes, et la combinaison de plusieurs sources nécessitait un nettoyage et une curation importants. Ensuite, mapper les codes et descriptions locaux aux termes standards OMOP était difficile, en particulier pour des détails riches en oncologie tels que le stadification, les résultats de biomarqueurs et les combinaisons médicamenteuses complexes ; les vocabulaires standards n'étaient parfois pas assez fins, et le texte libre ou les données génomiques demandaient des outils supplémentaires et l'avis d'experts. Enfin, une fois qu'un mappage était établi, il ne restait pas fixe : le modèle de données commun, les vocabulaires et les outils évoluent rapidement, si bien que les équipes devaient prévoir des plans pour maintenir leurs systèmes à jour dans le temps.
Une feuille de route en cinq étapes pour les équipes
En s'appuyant sur les motifs observés dans la revue et sur les retours d'experts en données sur le cancer, les auteurs ont distillé un processus générique d'harmonisation en cinq étapes adapté à l'oncologie. La première étape, Initiation, couvre la formation d'une équipe pluridisciplinaire, l'accord sur l'objectif de recherche, la compréhension des règles locales et la familiarisation avec l'écosystème OMOP. L'analyse des besoins (Requirement Analysis) examine ensuite les données source : quels types de données existent, comment elles sont structurées, à quel point elles sont complètes et fiables, et où se situent les risques les plus importants. La planification de la conception (Design Planning) traduit cette compréhension en un plan détaillé sur la façon de transformer et de mapper les données, quels outils utiliser, comment gérer les épisodes de soins comme les parcours thérapeutiques, et comment évaluer le succès.
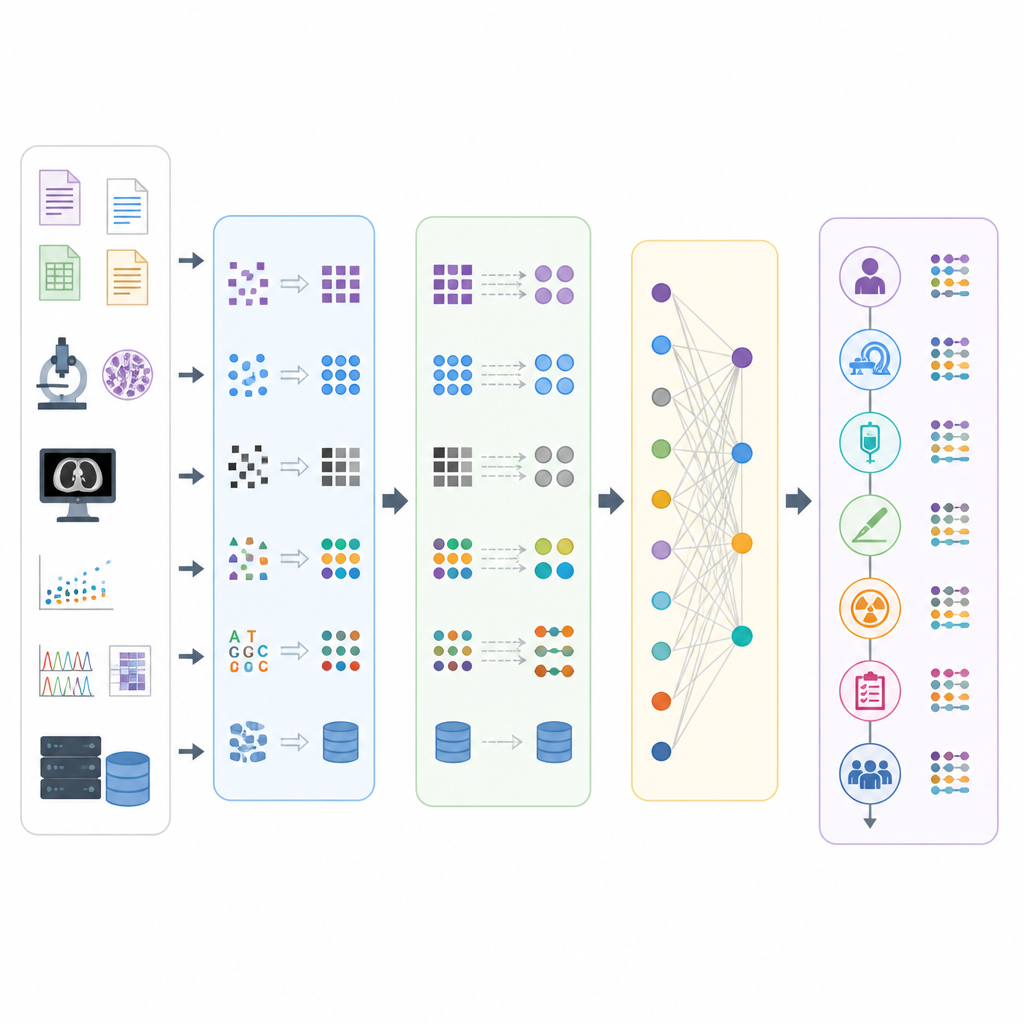
Des dossiers bruts à des données de recherche exploitables
La quatrième étape, Mise en œuvre technique (Technical Implementation), met le plan en action. Les équipes nettoient et curatent les données, extraient les éléments pertinents, les transforment pour les insérer dans les tables OMOP et contrôlent la qualité de manière systématique. Une attention particulière est portée à la construction de chronologies du parcours de cancer de chaque patient en utilisant les tables OMOP qui représentent les épisodes et leurs événements liés, tels que les diagnostics, les interventions et les expositions aux médicaments. La cinquième étape, Maintenance, reconnaît que le travail n'est jamais terminé : les vocabulaires, les outils logiciels et les connaissances en oncologie évoluent, aussi les équipes doivent-elles programmer des mises à jour, surveiller l'apparition de nouveaux problèmes et affiner leurs mappages et conventions. Deux principes transversaux soutiennent toutes les étapes : des cycles répétés de test et d'amélioration, et une documentation soigneuse des décisions afin que le travail soit transparent et réutilisable.
Ce que cela signifie pour les patients et les chercheurs
Pour le grand public, le message principal est que la meilleure utilisation des données existantes sur le cancer dépend moins de nouveaux appareils que de méthodes partagées et rigoureuses pour organiser l'information. Cet article propose une feuille de route pratique qu'un hôpital ou un groupe de recherche peut adapter pour réunir des dossiers de cancer dispersés dans un format commun, tout en respectant les règles et technologies locales. En facilitant la mise en commun des données entre centres et pays, le processus proposé vise à soutenir des études plus fiables sur la manière dont les cancers sont traités et sur l'évolution des patients dans la pratique courante, aidant cliniciens et décideurs à fonder leurs choix sur un tableau plus clair et plus complet.
Citation: Nada, I.P., Bonacina, S. Data harmonization processes of cancer data into the observational medical outcomes partnership common data model. Sci Rep 16, 15993 (2026). https://doi.org/10.1038/s41598-026-53570-9
Mots-clés: données sur le cancer, modèle de données commun OMOP, harmonisation des données, preuves du monde réel, informatique de santé