Clear Sky Science · zh
基于多维文本特征融合的 BA-RILA 用于古代汉诗主题识别
为什么教会计算机“读”古诗很重要
古代汉诗承载着数百年的情感、历史与日常生活,但其语言与现代汉语差异甚大,即使是专家也常对其含义产生分歧。随着越来越多的图书馆和博物馆将这些作品数字化,迫切需要能够快速按主题整理诗歌的智能工具,帮助学者、学生与公众在海量藏品中检索与探索。本研究提出了一种新的计算机识别古诗主题的方法,不仅利用词义,还结合节奏与意象,更好地把握古典诗歌的精神内涵。
把经典诗歌变成可用的数据
为了教会计算机理解诗歌,研究者首先必须构建合适的数据集。他们收集了约一万首来自主要朝代的诗作,主要为唐宋作品,并将每首诗仔细标注为六类宽泛主题,如友情与别离、历史与怀古、山水田园、爱情婚姻、思乡以及边塞与战事。他们剔除了噪声或不完整的文本,对文言文本进行分词,并过滤掉不承载实义的虚词。词云分析显示每个主题具有自身特征词汇,验证了标签与诗歌内容的良好对应关系。
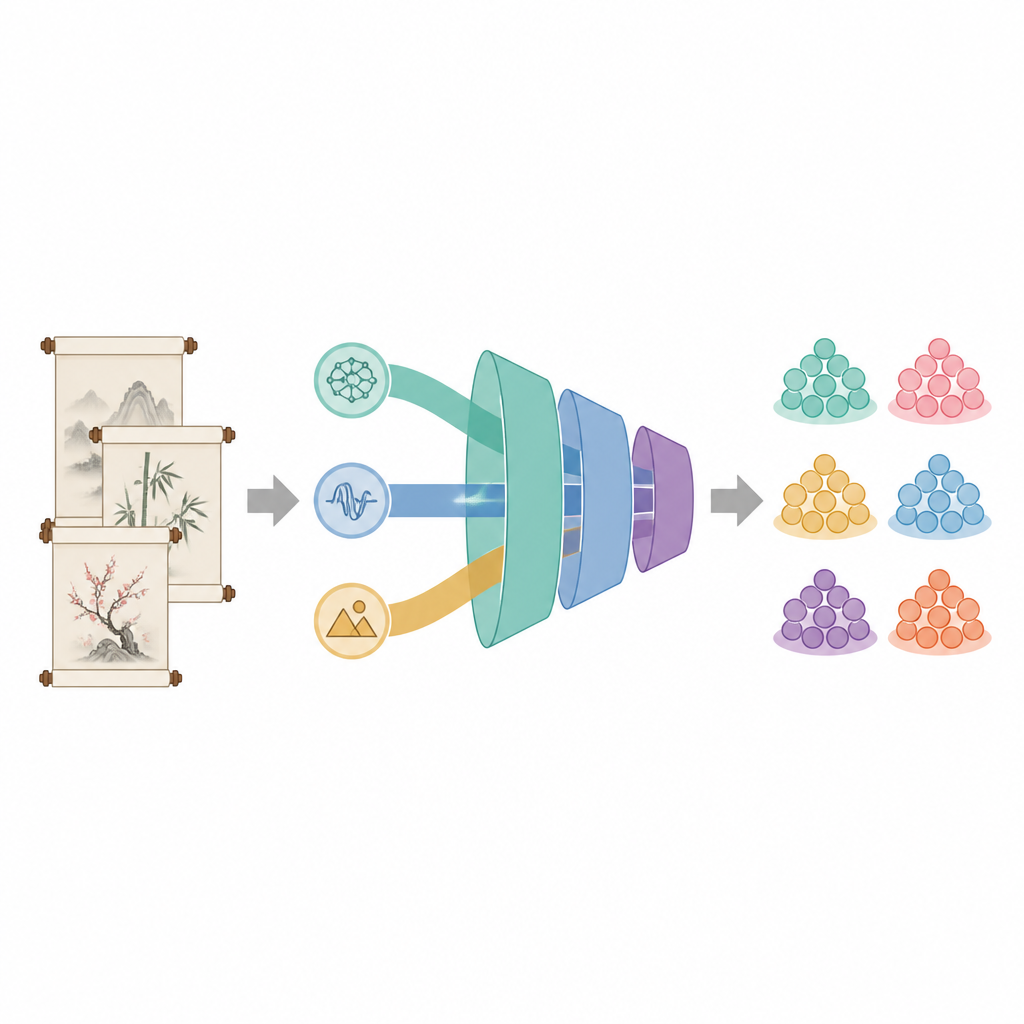
融合语义、音韵与意象
大多数语言技术只关注词义,但古典汉诗也大量依赖音韵模式和象征性意象。新的 BA-RILA 模型结合了三类信息。首先,它使用了在古文语料上再训练的 BERT 版本,使模型更好地理解古语句法和典故用法。其次,它通过十一项数值特征度量节奏,捕捉押韵、句长、平仄格律与对偶结构,反映诗行的音声与平衡感。第三,它用由25个具有文化意义的意象构成的75项描述追踪诗歌意象,例如以杨柳象征离别、以明月象征思念,每项描述包含该意象在诗中的频次、情感色彩与强度。
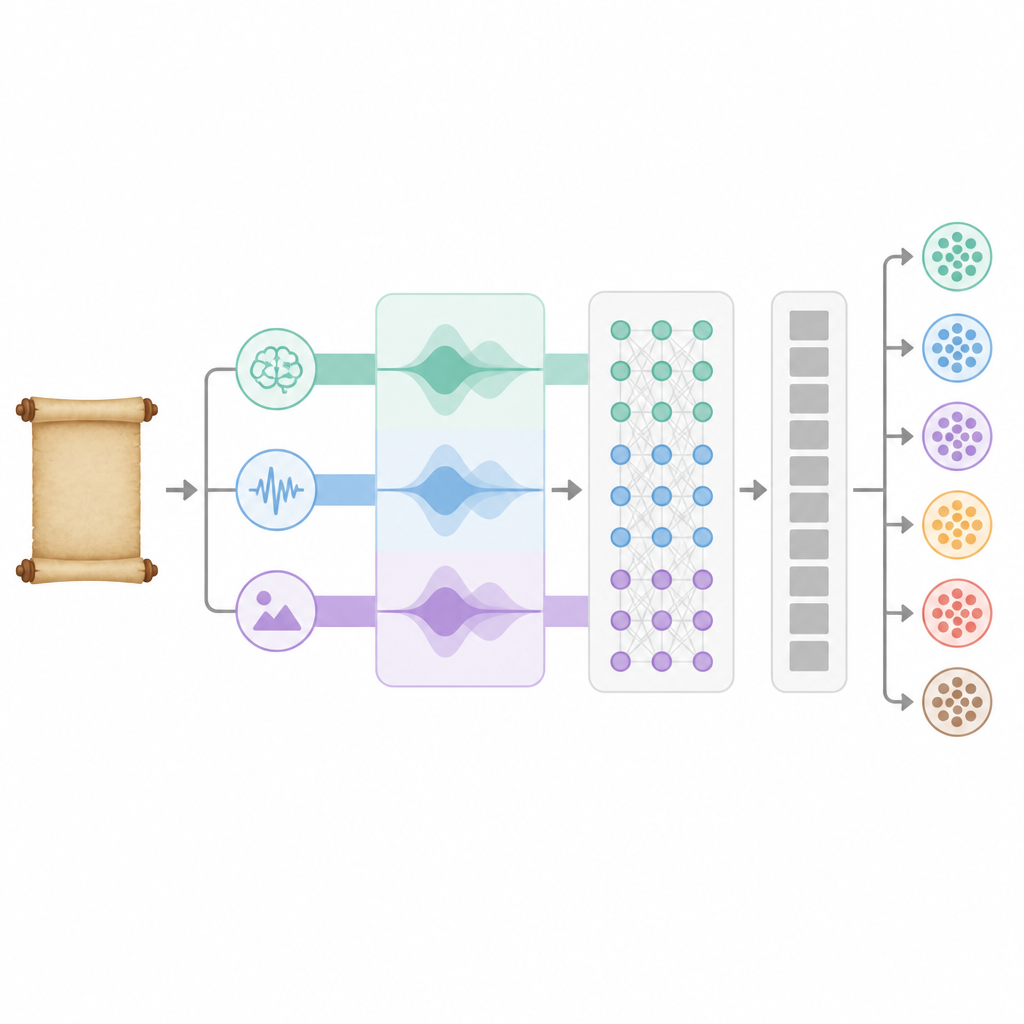
模型如何从整首诗中学习
这三类信息尺度不同,因此系统首先将它们映射到一个公共空间,并使用内部注意力机制决定在每首诗中应给予语义、节奏与意象多少权重。融合后的特征经过两层双向递归网络,前后读取诗句,捕捉意义随时间的展开。随后,多头注意力模块从多个角度进一步突出表示中最具信息量的部分。最后,一组全连接层将这一丰富的内部表征映射为六个主题的概率分布,从而判定最符合该诗的主题。
系统表现如何
大量测试表明,BA-RILA 明显优于若干仅依赖现代 BERT、卷积网络或更简单递归结构的强基线模型。在六类主题任务上,该方法准确率约为 97%,即便在较少见主题上也保持稳定表现。当作者去掉系统中的某些组成部分(例如经古汉语微调的 BERT、节奏与意象的融合、递归层或注意力模块)时,性能显著下降,表明每一部分均对整体性能有实质贡献。该模型也能处理唐宋两代的诗作,但对宋诗的识别稍显困难,原因在于宋诗节奏更不规则、语言更为分散。
这对研究古典文学有何意义
对非专业读者而言,核心结论是:将词义与音声及象征意象结合,使计算机能够按主题更贴近传统阅读方式地整理古诗。BA-RILA 方法并不把诗歌当作普通文本,而是尊重其音乐性与文化意象,从而带来更可靠的自动标注。这类工具可以更便捷地在大规模档案中检索、比较不同朝代的诗人,或研究诸如思乡与战争等主题随时间的演变,既支持学术研究,也有助于公众更好地欣赏古典中国文化。
引用: Zhang, X., Liu, Y. Multi-dimensional text feature fusion-based BA-RILA for ancient Chinese poetry theme recognition. Sci Rep 16, 16573 (2026). https://doi.org/10.1038/s41598-026-48986-2
关键词: 古代汉诗, 主题分类, 文本特征融合, 诗歌意象, 文化类自然语言处理