Clear Sky Science · ru
BA-RILA на основе многомерного слияния текстовых признаков для распознавания тем в древней китайской поэзии
Почему важно учить компьютеры «читать» древние стихи
Древние китайские стихи хранят столетия эмоций, историй и быта, но их язык настолько отличается от современного китайского, что даже специалисты спорят о значениях. По мере того как библиотеки и музеи оцифровывают эти тексты, возрастает потребность в умных инструментах, которые быстро сортируют стихи по темам и помогают ученым, студентам и широкой публике исследовать большие коллекции. В этом исследовании предложен новый подход для автоматического определения тематики древнего стихотворения, использующий не только смысл слов, но и ритм и образность, чтобы лучше уловить дух классической поэзии.
Преобразование классических стихов в данные
Чтобы научить компьютер поэзии, исследователям сначала потребовалось подготовить подходящую базу данных. Они собрали около 10 000 стихотворений из основных династий, в основном Тан и Сун, и тщательно размечали каждое по шести широким темам, таким как дружба и прощание, история и ностальгия, пейзажи и деревня, любовь и брак, тоска по родине, и пограничная тематика и война. Были удалены шумные или неполные тексты, выполнена сегментация классического китайского и отфильтрованы служебные слова, которые мало несут смысла. Анализы облаков слов показали, что у каждой темы есть свой характерный лексикон, что подтвердило соответствие меток поэтическому содержанию.
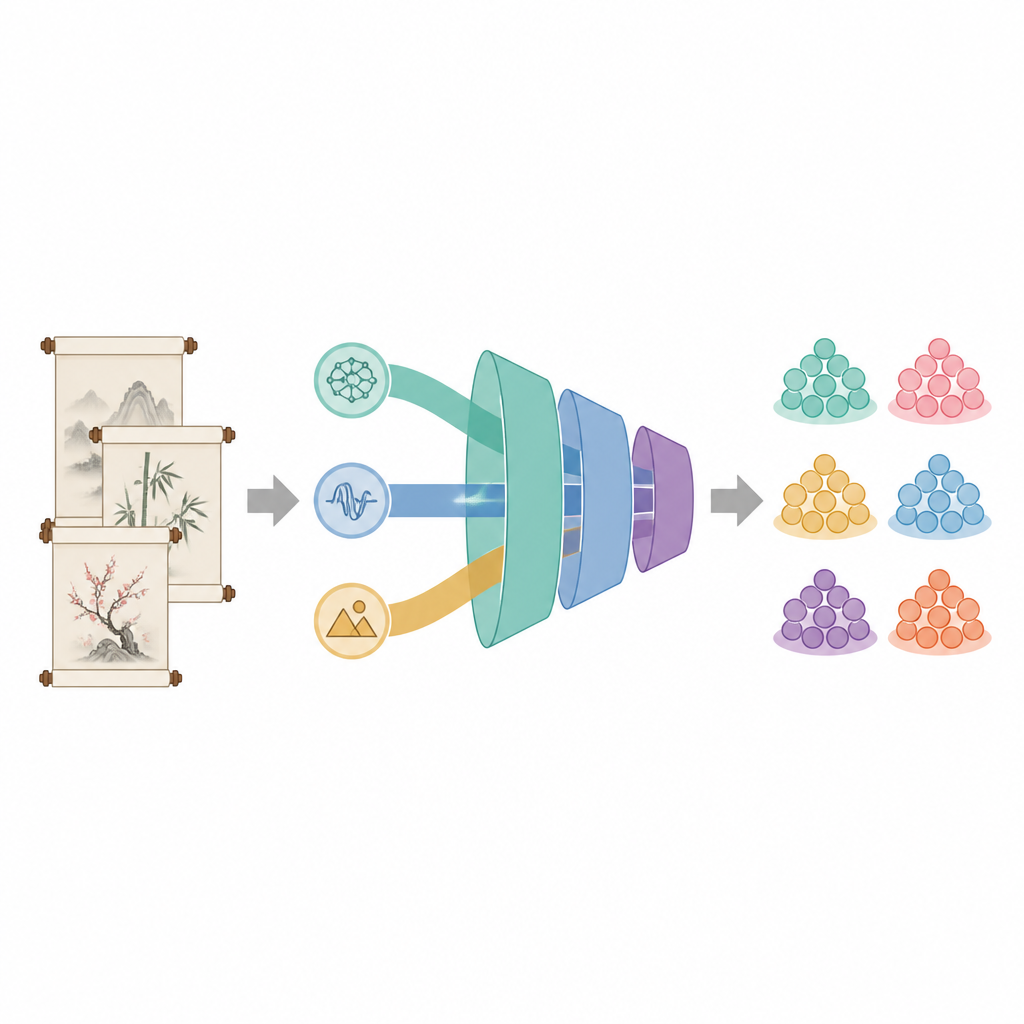
Слияние смысла, звука и образов
Большинство технологий обработки языка опираются только на значение слов, тогда как в классической китайской поэзии большое значение имеют звуковые узоры и символические образы. Новая модель BA-RILA объединяет три вида информации. Во‑первых, она использует версию популярной языковой модели BERT, дообученную на корпусе древнекитайских текстов, чтобы компьютер лучше понимал старую грамматику и классические обороты. Во‑вторых, модель измеряет ритм с помощью одиннадцати числовых признаков, отражающих рифму, длину строк, тоновые схемы и структуру двустиший, то есть то, как строки звучат и уравновешиваются. В‑третьих, она отслеживает поэтическую образность через описание из 75 компонентов, построенное на базе 25 культурно значимых символов, таких как ива для разлуки или луна для тоски, где для каждого учитывается частота, эмоциональная окраска и сила проявления в стихотворении.
Как модель учится на целом стихотворении
Эти три потока информации различаются по масштабу, поэтому система сначала отображает их в общее пространство и использует внутренний механизм внимания, чтобы определить, сколько веса дать семантике, ритму и образности для каждого конкретного стихотворения. Слитые признаки затем проходят через два слоя двунаправленной рекуррентной сети, которая читает стих как вперед, так и назад, улавливая развитие смысла во времени. Модуль многоголового внимания дополнительно выделяет наиболее информативные части представления, рассматривая его с нескольких точек зрения одновременно. Наконец, набор полностью связанных слоев преобразует это богатое внутреннее представление в распределение вероятностей по шести темам, выбирая тему, лучше всего соответствующую стихотворению.
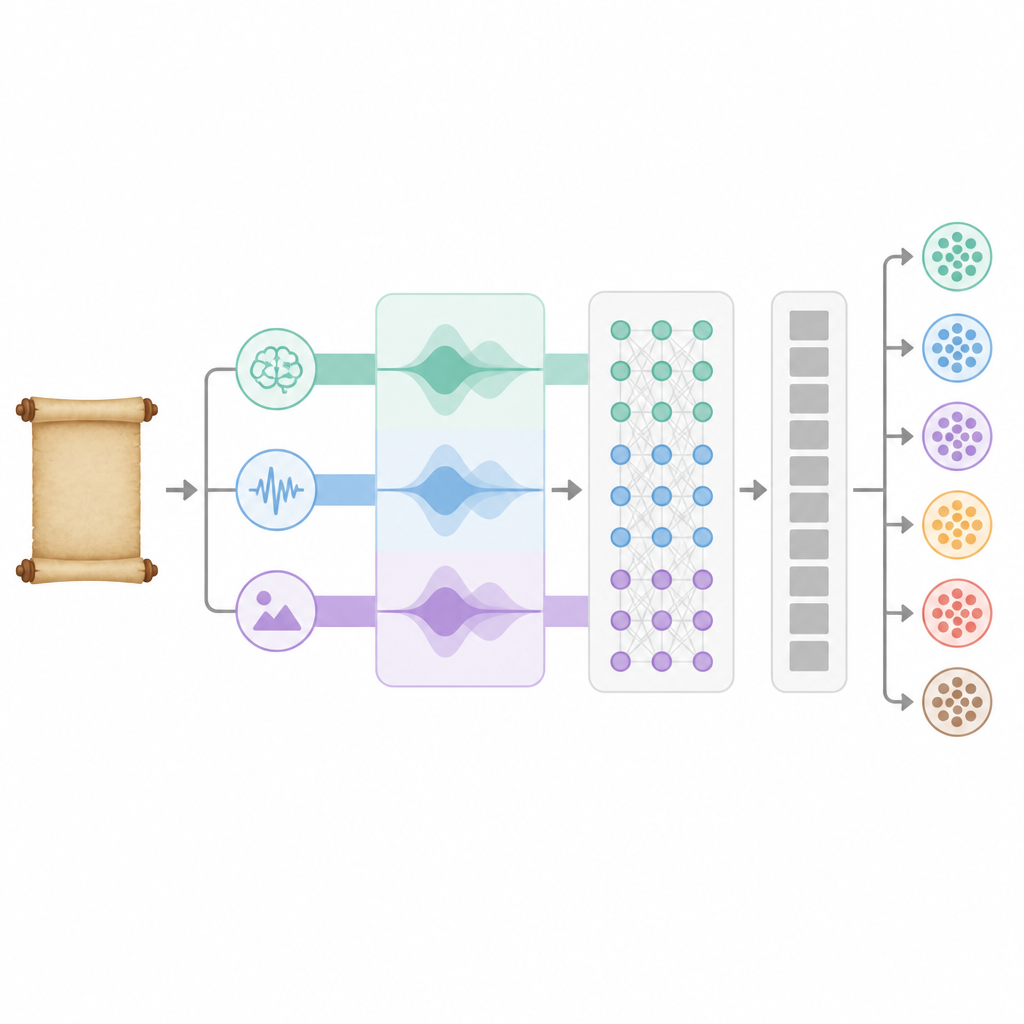
Насколько хорошо работает система
Широкие тесты показывают, что BA-RILA заметно превосходит несколько сильных эталонных моделей, опирающихся только на современный BERT, на сверточные сети или более простые рекуррентные конструкции. В задаче с шестью темами новый метод достигает точности примерно 97 процентов при стабильной работе даже на менее распространенных темах. Когда авторы поочередно исключали отдельные компоненты системы — например, BERT, дообученный на древнем китайском, слияние ритма и образности, рекуррентные слои или модуль внимания — производительность заметно падала, что указывает на вклад каждого элемента. Модель также успешно справлялась со стихами и из Тан, и из Сун, хотя с поэзией Сун она справлялась чуть хуже: ритмы там менее регулярны, а язык — более рассеянный.
Что это значит для изучения классической литературы
Для неспециалиста ключевая мысль такова: объединение смысла слов с звуком и символическими образами позволяет компьютерам сортировать древние стихотворения по темам так, как это ближе к традиционным практикам чтения. Вместо того чтобы воспринимать поэзию как простой текст, подход BA-RILA учитывает ее музыкальность и культурную образность, что обеспечивает более надежную автоматическую разметку. Такие инструменты могут облегчить поиск по большим архивам, сравнительный анализ поэтов разных династий или изучение эволюции тем, таких как тоска по родине или война, служа как академическим исследованиям, так и общественному восприятию классической китайской культуры.
Цитирование: Zhang, X., Liu, Y. Multi-dimensional text feature fusion-based BA-RILA for ancient Chinese poetry theme recognition. Sci Rep 16, 16573 (2026). https://doi.org/10.1038/s41598-026-48986-2
Ключевые слова: древняя китайская поэзия, классификация тем, слияние текстовых признаков, поэтическая образность, культурный NLP