Clear Sky Science · nl
BA-RILA voor thematische herkenning van oude Chinese poëzie op basis van meer-dimensionale tekstkenmerken
Waarom computers leren oude gedichten te lezen ertoe doet
Oude Chinese gedichten bevatten eeuwen aan emotie, geschiedenis en dagelijks leven, maar hun taal wijkt zo sterk af van modern Chinees dat zelfs specialisten de betekenis vaak betwisten. Nu bibliotheken en musea deze werken digitaliseren, groeit de behoefte aan slimme hulpmiddelen die snel gedichten op onderwerp kunnen sorteren en wetenschappers, studenten en het publiek helpen grote collecties te verkennen. Deze studie presenteert een nieuwe manier voor computers om te herkennen waar een oud gedicht over gaat, waarbij niet alleen woordbetekenis maar ook ritme en beeldspraak worden gebruikt om de geest van de klassieke versvorm beter vast te leggen.
Hoe klassieke gedichten tot data worden gemaakt
Om een computer poëzie te leren, moesten de onderzoekers eerst de juiste dataset opbouwen. Ze verzamelden ongeveer 10.000 gedichten uit belangrijke Chinese dynastieën, voornamelijk Tang en Song, en labelden elk gedicht zorgvuldig in zes brede thema’s zoals vriendschap en afscheid, geschiedenis en nostalgie, landschappen en platteland, liefde en huwelijk, heimwee, en grens/oorlog. Ze verwijderden ruisende of onvolledige teksten, segmenteerden het klassiek Chinees en filterden functiewoorden die weinig betekenis dragen. Woordwolk-analyses toonden dat elk thema zijn eigen kenmerkende vocabulaire had, wat bevestigde dat de labels goed overeenkwamen met de poëtische inhoud.
Betekenis, klank en beeldspraak samenbrengen
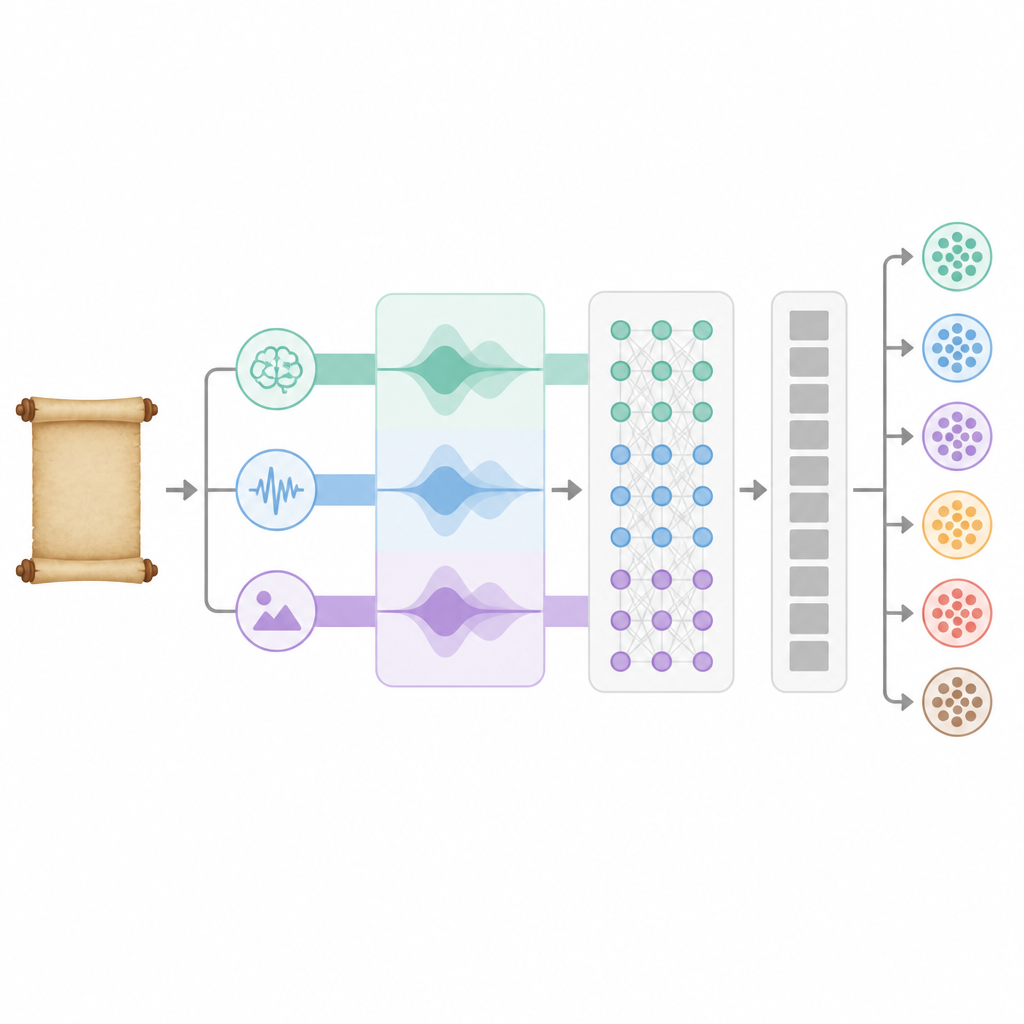
De meeste taaltechnologieën richten zich alleen op woordbetekenis, maar klassieke Chinese poëzie leunt ook sterk op klankpatronen en symbolische beelden. Het nieuwe BA-RILA-model combineert drie soorten informatie. Ten eerste gebruikt het een versie van het populaire BERT-taalmodel die opnieuw is getraind op oud Chinees, zodat de computer oude grammatica en klassieke uitdrukkingen beter begrijpt. Ten tweede meet het ritme met elf numerieke kenmerken die rijm, verslengte, toonpatronen en coupletstructuren vastleggen en daarmee laten zien hoe regels klinken en in balans staan. Ten derde volgt het poëtische beeldspraak via een 75-delige beschrijving opgebouwd uit 25 cultureel belangrijke symbolen, zoals wilgen voor afscheid of de maan voor verlangen, elk met frequentie, emotionele lading en sterkte binnen een gedicht.
Hoe het model leert van hele gedichten
Deze drie informatiestromen verschillen in schaal, dus het systeem brengt ze eerst in een gemeenschappelijke ruimte en gebruikt een interne attentie-mechanisme om per gedicht te beslissen hoeveel gewicht betekenis, ritme en beeldspraak krijgen. De gefuseerde kenmerken worden vervolgens door twee lagen van een bidirectioneel recurrent netwerk geleid dat het gedicht zowel vooruit als achteruit leest en zo vastlegt hoe betekenis zich in de tijd ontvouwt. Een multi-head attention-module benadrukt verder de meest informatieve delen van deze representatie door er tegelijk vanuit meerdere invalshoeken naar te kijken. Ten slotte zetten een reeks volledig verbonden lagen dit rijke interne beeld om in een waarschijnlijkheidsverdeling over de zes thema’s en bepaalt welk onderwerp het beste bij het gedicht past.
Hoe goed het systeem presteert
Uitgebreide tests tonen aan dat BA-RILA duidelijk beter presteert dan meerdere sterke benchmarkmodellen die alleen op modern BERT, convolutionele netwerken of eenvoudigere recurrente ontwerpen leunen. Bij de zes-thema taak bereikt de nieuwe methode een nauwkeurigheid van ongeveer 97 procent, met stabiele prestaties zelfs bij minder voorkomende thema’s. Wanneer de auteurs afzonderlijke onderdelen van het systeem verwijderden, zoals de op oud-Chinees afgestemde BERT, de fusie van ritme en beeldspraak, de recurrente lagen of de attentie-module, daalde de prestatie merkbaar, wat aangeeft dat elk onderdeel een zinvolle bijdrage levert. Het model ging ook om met gedichten uit zowel de Tang- als Song-periode, hoewel het Song-poëzie wat moeilijker vond omdat de ritmes minder regelmatig zijn en de taal meer diffuus.
Wat dit betekent voor het verkennen van klassieke literatuur
Voor niet-specialisten is de belangrijkste conclusie dat het combineren van woordbetekenis met klank en symbolische beelden computers in staat stelt oude gedichten op thema te sorteren op een manier die beter aansluit bij traditionele leespraktijken. In plaats van poëzie als gewoon tekstmateriaal te behandelen, respecteert de BA-RILA-aanpak de muzikaliteit en culturele beeldtaal, wat leidt tot betrouwbaardere automatische labels. Zulke hulpmiddelen kunnen het zoeken in grote archieven vergemakkelijken, dichters tussen dynastieën vergelijken of bestuderen hoe thema’s zoals heimwee of oorlog in de loop der tijd evolueerden, en zo zowel academisch onderzoek als het publieke waarderen van de klassieke Chinese cultuur ondersteunen.
Bronvermelding: Zhang, X., Liu, Y. Multi-dimensional text feature fusion-based BA-RILA for ancient Chinese poetry theme recognition. Sci Rep 16, 16573 (2026). https://doi.org/10.1038/s41598-026-48986-2
Trefwoorden: oude Chinese poëzie, themaclassificatie, fusie van tekstkenmerken, poëtische beeldspraak, culturele NLP