Clear Sky Science · de
BA-RILA auf Basis multidimensionaler Textmerkmalsfusion zur Themenerkennung antiker chinesischer Dichtung
Warum es wichtig ist, Computern das Lesen alter Gedichte beizubringen
Alte chinesische Gedichte bewahren Jahrhunderte an Gefühlen, Geschichte und Alltagsleben, aber ihre Sprache unterscheidet sich so stark vom modernen Chinesisch, dass selbst Fachleute oft über die Bedeutung streiten. Da immer mehr Bibliotheken und Museen diese Werke digitalisieren, wächst der Bedarf an intelligenten Werkzeugen, die Gedichte schnell nach Themen sortieren können und damit Forschende, Studierende und die Öffentlichkeit beim Erschließen großer Bestände unterstützen. Diese Studie stellt einen neuen Weg vor, wie Computer erkennen können, worum es in einem antiken Gedicht geht — und zwar nicht nur anhand der Wortbedeutung, sondern auch unter Einbeziehung von Rhythmus und Bildsprache, um den Geist klassischer Lyrik besser zu erfassen.
Wie klassische Gedichte zu Daten werden
Um einem Computer Poesie beizubringen, mussten die Forschenden zunächst den passenden Datensatz erzeugen. Sie sammelten etwa 10.000 Gedichte aus wichtigen chinesischen Dynastien, vornehmlich Tang und Song, und etikettierten jedes sorgfältig mit sechs breiten Themen wie Freundschaft und Abschied, Geschichte und Nostalgie, Landschaft und Landleben, Liebe und Ehe, Heimweh sowie Grenzregionen und Krieg. Sie entfernten verrauschte oder unvollständige Texte, segmentierten das Klassisch‑Chinesische und filterten Funktionswörter heraus, die wenig semantischen Gehalt tragen. Wortwolkenanalysen zeigten, dass jedes Thema seinen charakteristischen Wortschatz besitzt, was die Übereinstimmung der Labels mit dem poetischen Inhalt bestätigte.
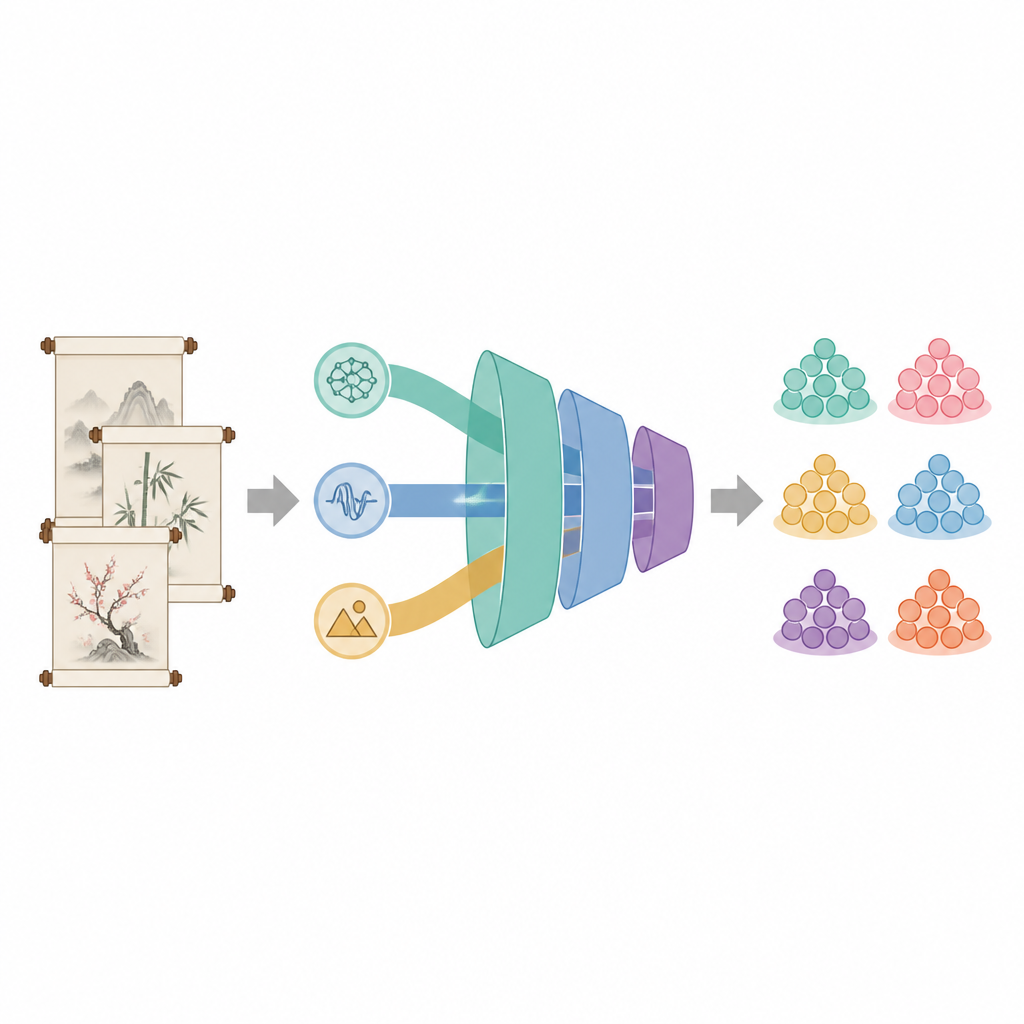
Bedeutung, Klang und Bildsprache verschmelzen
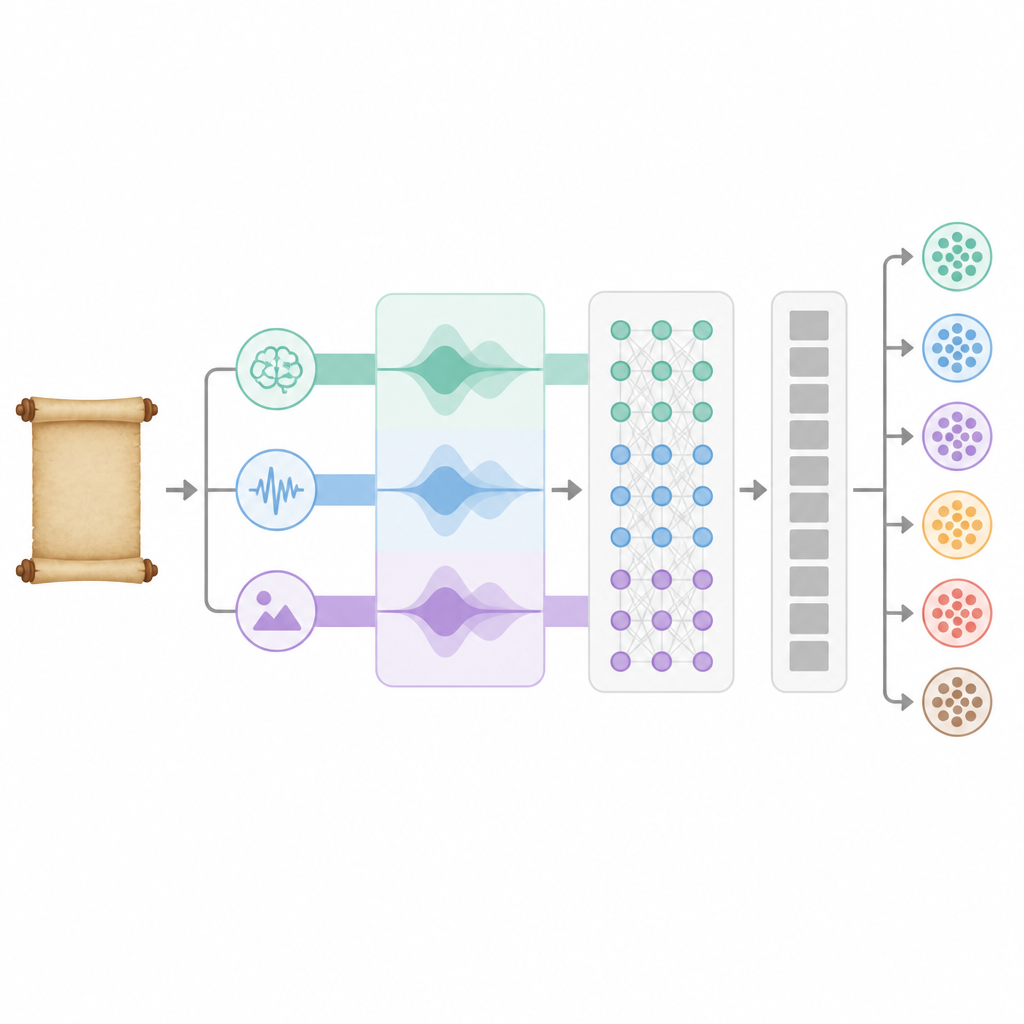
Die meisten Sprachtechnologien konzentrieren sich allein auf Wortbedeutung, doch die klassische chinesische Dichtung stützt sich stark auf Klangmuster und symbolische Bilder. Das neue BA‑RILA‑Modell kombiniert drei Informationsarten. Erstens nutzt es eine auf antikes Chinesisch nachtrainierte Variante des verbreiteten BERT‑Modells, sodass der Computer alte Grammatik und klassische Wendungen besser erfassen kann. Zweitens misst es Rhythmus mit elf numerischen Merkmalen, die Reime, Zeilenlängen, Tonschemata und Paarstruktur erfassen und damit Klang und Ausgewogenheit der Verse widerspiegeln. Drittens erfasst es poetische Bildsprache durch eine 75‑teilige Beschreibung, die aus 25 kulturell wichtigen Symbolen besteht — etwa Weiden als Zeichen des Abschieds oder der Mond für Sehnsucht — jeweils mit Häufigkeit, emotionaler Färbung und Stärkeerfassung innerhalb eines Gedichts.
Wie das Modell aus ganzen Gedichten lernt
Diese drei Informationsströme unterscheiden sich in ihrer Skala, daher führt das System sie zuerst in einen gemeinsamen Raum über und nutzt einen internen Aufmerksamkeitsmechanismus, um für jedes Gedicht zu entscheiden, wie viel Gewicht Semantik, Rhythmus und Bildsprache erhalten. Die fusionierten Merkmale durchlaufen dann zwei Schichten eines bidirektionalen rekurrenten Netzwerks, das das Gedicht vorwärts und rückwärts liest und so erfasst, wie sich Bedeutung im Verlauf entfaltet. Ein Multi‑Head‑Attention‑Modul hebt zusätzlich die informativsten Teile dieser Repräsentation hervor, indem es sie aus mehreren Blickwinkeln betrachtet. Schließlich wandelt eine Gruppe voll verbundener Schichten dieses reichhaltige innere Bild in Wahrscheinlichkeiten über die sechs Themen um und entscheidet, welches Thema am besten zum Gedicht passt.
Wie gut das System funktioniert
Umfangreiche Tests zeigen, dass BA‑RILA mehrere starke Benchmark‑Modelle deutlich übertrifft, die nur auf modernes BERT, auf Faltungsnetzwerke oder auf einfachere rekurrente Entwürfe setzen. Bei der Sechs‑Themen‑Aufgabe erreicht die neue Methode eine Genauigkeit von etwa 97 Prozent und zeigt auch bei selteneren Themen stabile Leistungen. Entfernten die Autoren einzelne Systemkomponenten — etwa das auf antikes Chinesisch angepasste BERT, die Fusion von Rhythmus und Bildsprache, die rekurrenten Schichten oder das Aufmerksamkeitsmodul —, sank die Leistung deutlich, was darauf hinweist, dass jede Komponente einen sinnvollen Beitrag leistet. Das Modell bewältigte Gedichte aus Tang‑ und Song‑Zeit, fand jedoch Song‑Poesie etwas schwieriger, da deren Rhythmik weniger regelmäßig und die Sprache diffuser ist.
Was das für die Erschließung klassischer Literatur bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass die Kombination von Wortbedeutung mit Klang und symbolischen Bildern es Computern erlaubt, antike Gedichte thematisch zu ordnen — und zwar auf eine Weise, die traditionelle Lesepraktiken besser widerspiegelt. Anstatt Poesie als reinen Text zu behandeln, respektiert der BA‑RILA‑Ansatz ihre Musikalität und kulturelle Bildsprache und liefert so verlässlichere automatische Etikettierungen. Solche Werkzeuge könnten das Durchsuchen großer Archive erleichtern, den Vergleich von Dichtern über Dynastien hinweg unterstützen oder untersuchen helfen, wie sich Themen wie Heimweh oder Krieg im Lauf der Zeit entwickelten — und damit sowohl die wissenschaftliche Forschung als auch die öffentliche Wertschätzung klassischer chinesischer Kultur fördern.
Zitation: Zhang, X., Liu, Y. Multi-dimensional text feature fusion-based BA-RILA for ancient Chinese poetry theme recognition. Sci Rep 16, 16573 (2026). https://doi.org/10.1038/s41598-026-48986-2
Schlüsselwörter: antike chinesische Dichtung, Themenklassifikation, Textmerkmalsfusion, poetische Bildsprache, kulturelles NLP