Clear Sky Science · zh
在数据稀缺下用于下一日冷负荷预测的可部署知识–数据混合模型:案例研究与性能验证
为何预测建筑冷负荷很重要
随着城市扩张和热浪愈加频繁,大型办公楼对空调的依赖显著提高。提前知道明天的制冷需求能帮助建筑运营者更合理地购电、提高冷机运行效率,并支持日益增加太阳能和风电的电网运行。然而,最新且高效的建筑在投入使用的最初几个月通常只有很少的数据,这使得标准的人工智能工具难以可靠地预测它们的制冷需求。
有限数据带来的挑战
许多现有预测工具将建筑视为黑箱,输入过去的能耗、天气和日程,让学习算法在其中寻找模式。这类数据饥渴的模型在拥有多年高质量记录时可以表现良好。但在新建或翻新的建筑中,仅存在短期历史数据。在这种条件下,纯数据驱动模型往往会纠缠于有限数据中的偶然特性,错过需求的突变,并产生日复一日波动较大的预测。这对下一日规划尤其成问题,因为运营者必须提前24小时安排制冷设备并参与电力市场。
将简单物理与现代学习方法结合
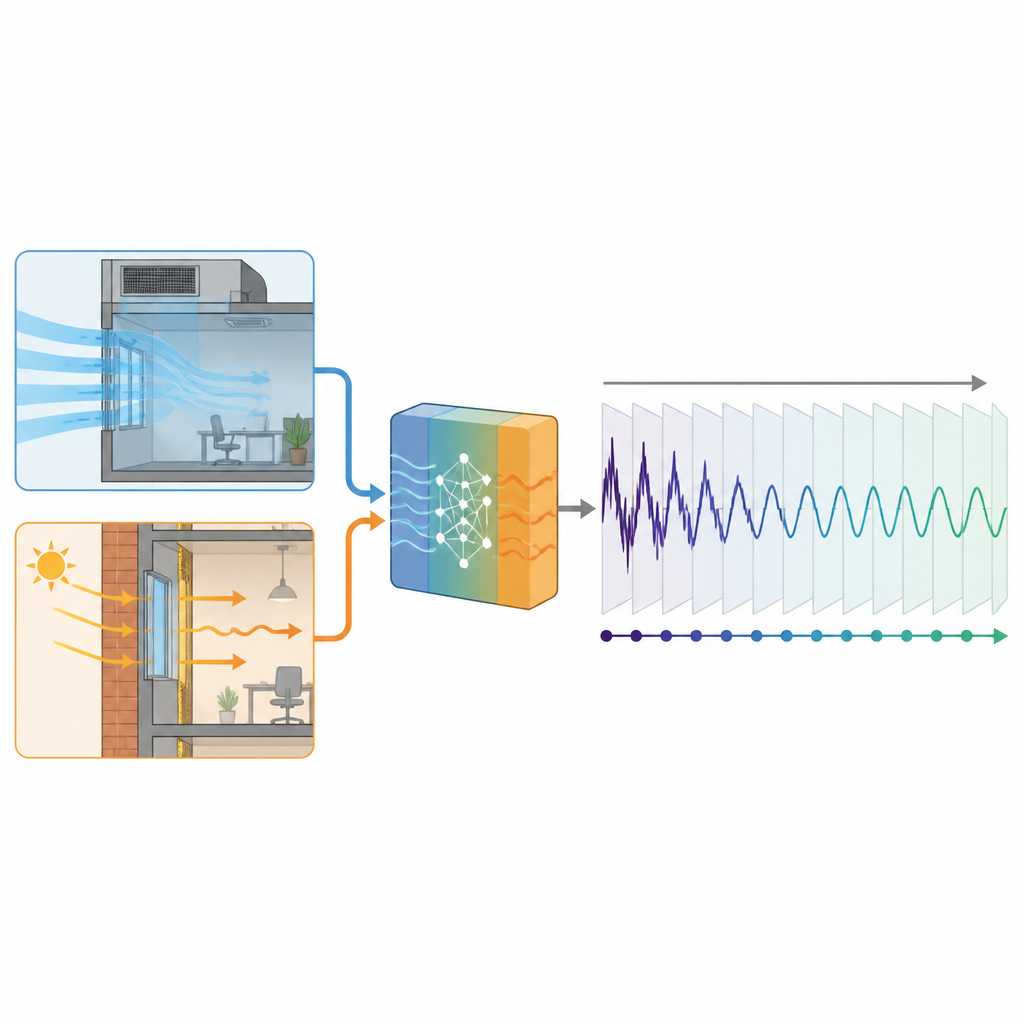
本研究提出了一条介于详尽物理仿真与纯数据挖掘之间的实用中间道路。作者并不试图模拟建筑中所有热源,而是集中于两类可由大多数建筑已有信息计算的贡献:随外部新风带入的热量以及通过墙体和窗户泄漏的热量。利用基本的传热公式,他们将天气预测、玻璃特性和通风日程转化为这些负荷的粗略、物理上合理的估计。这些估计并不取代测量到的制冷需求,而是作为额外输入加入,引导一个结合卷积层与循环层的深度学习模型。
在实际写字楼中的混合方法测试
该方法在中国杭州一栋23层的办公楼上进行了测试,该楼采用现代玻璃幕墙和集中制冷系统。研究者使用了一个制冷季的逐小时数据,总计约4300小时,然后在训练时人为限制各模型可见的历史数据量。在一些测试中,模型只能从10%的数据中学习,相当于仅两周多一点的记录。在四个预测器版本中,有三个使用了基于物理的新风或墙窗负荷作为引导信号,而第四个仅依赖过去的制冷和天气数据。所有模型均尝试逐小时预测下一日的制冷曲线。
更准确且更稳定的预测
在训练数据稀少时,各方法之间的差异非常明显。在仅有10%数据可用的情况下,纯数据驱动模型常常错过早晨工人到岗时制冷的急剧增长,并低估炎热午后的峰值。其误差随用于训练的天数不同而大幅波动。相比之下,所有三种混合版本在峰值的时序和高度上都追踪得更紧密,误差的离散程度也小得多。平均而言,混合模型将典型预测误差减少了约一半,并将误差分布的散度减少了近一个数量级,相较基线模型有显著改善。最简单的变体仅使用新风负荷作为额外信息,在精度、稳定性和部署便利性之间提供了特别吸引人的平衡。
对实际建筑的意义
对建筑业主与能效管理者而言,核心信息是:少量物理知识效果显著。通过将对新风和建筑围护结构如何增加制冷需求的简单且易计算的估计纳入学习模型,即便在运行初期历史数据仍然稀疏时,也能获得有用的下一日预测。研究表明,这种知识—数据混合方法能够抑制过拟合,维持适度的训练成本,并为冷机与储能的调度提供可靠指引。简单而言,将基础工程洞见与现代数据工具结合,有助于保持建筑舒适、减少浪费,并更顺畅地配合不断变化的电网。
引用: Chen, J., Sun, T., Zhang, Y. et al. Deployable knowledge–data hybrid models for day-ahead cooling load prediction under data scarcity: a case study and performance validation. Sci Rep 16, 15079 (2026). https://doi.org/10.1038/s41598-026-45325-3
关键词: 冷负荷预测, 建筑能效, 混合建模, 数据稀缺, 深度学习