Clear Sky Science · it
Modelli ibridi conoscenza-dati implementabili per la previsione del carico di raffreddamento giorno per giorno in condizioni di scarsità di dati: uno studio di caso e validazione delle prestazioni
Perché è importante prevedere il raffreddamento degli edifici
Con la crescita delle città e l’aumento delle ondate di calore, i grandi edifici per uffici dipendono fortemente dall’aria condizionata. Conoscere in anticipo la domanda di raffreddamento per il giorno successivo aiuta i gestori degli edifici a comprare elettricità in modo più oculato, a far funzionare i gruppi frigoriferi in modo efficiente e a supportare una rete elettrica sempre più integrata con solare ed eolico. Tuttavia gli edifici più nuovi ed efficienti spesso dispongono di pochissimi dati nei primi mesi di esercizio, il che rende difficile per gli strumenti standard di intelligenza artificiale prevedere in modo affidabile il loro fabbisogno di raffreddamento.
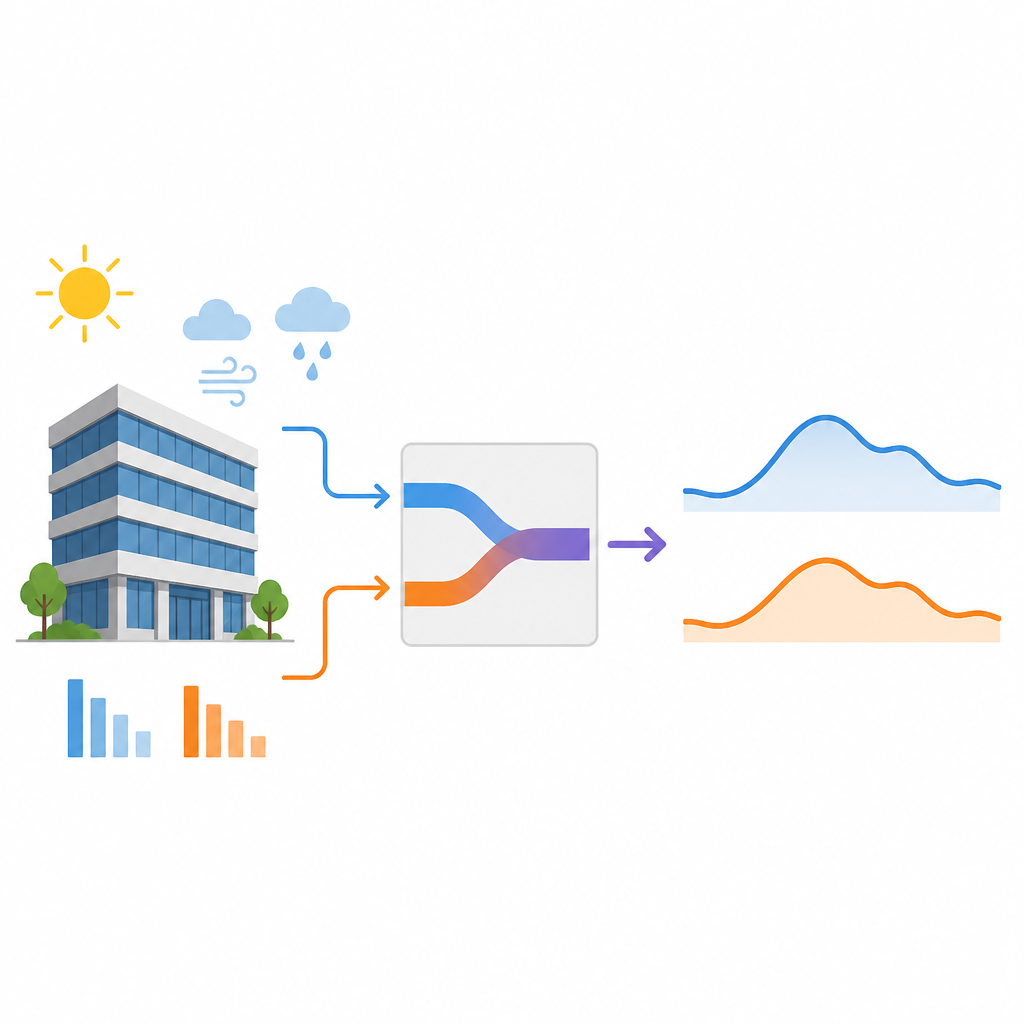
La sfida della scarsità di dati
Molti strumenti di previsione attuali trattano un edificio come una scatola nera. Inseriscono i consumi energetici passati, il meteo e gli orari di occupazione, e lasciano che un algoritmo di apprendimento cerchi pattern. Questi modelli, affamati di dati, possono funzionare bene quando sono disponibili anni di registrazioni di alta qualità. Ma in un edificio nuovo o rinnovato esiste solo una breve storia. In queste condizioni i modelli puramente basati sui dati tendono ad aggrapparsi ad anomalie presenti nel piccolo insieme di dati, a perdere salti improvvisi nella domanda e a fornire previsioni che oscillano molto da un giorno all’altro. Ciò è particolarmente problematico per la pianificazione giorno per giorno, quando gli operatori devono programmare gli impianti di raffreddamento e interagire con il mercato elettrico con 24 ore di anticipo.
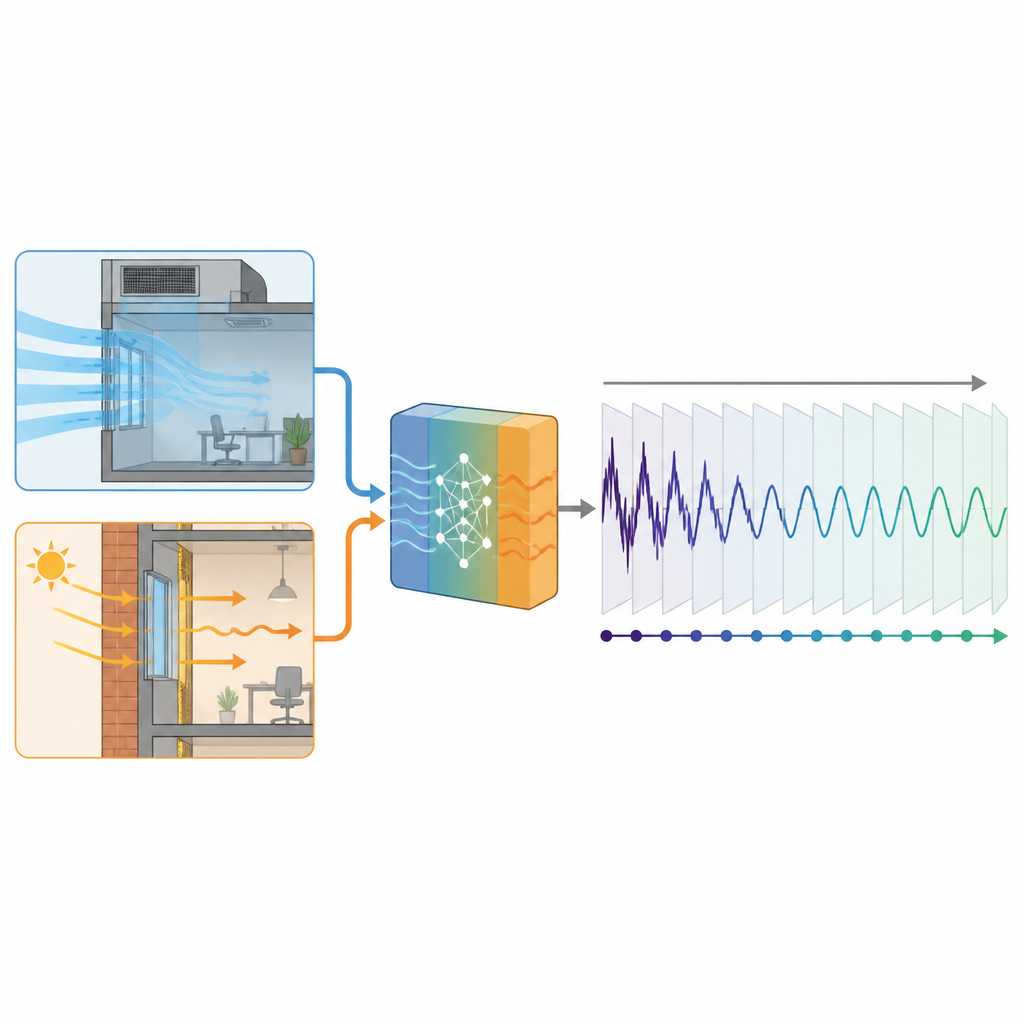
Fondere una fisica semplice con l’apprendimento moderno
Lo studio propone una via di mezzo pratica tra simulazioni fisiche dettagliate e puro data mining. Invece di cercare di modellare ogni sorgente di calore nell’edificio, gli autori si concentrano su due contributi che possono essere calcolati a partire da informazioni che la maggior parte degli edifici già possiede: il calore che entra con l’aria esterna di rinnovo e il calore che passa attraverso pareti e finestre. Usando formule elementari di trasmissione termica, trasformano previsioni meteo, proprietà dei vetri e programmi di ventilazione in stime approssimative e fisicamente sensate di questi carichi. Queste stime non sostituiscono la domanda di raffreddamento misurata ma vengono aggiunte come input supplementari che guidano un modello di deep learning che combina strati convoluzionali e ricorrenti.
Testare l’idea ibrida in una torre per uffici reale
L’approccio è stato testato su un edificio per uffici di 23 piani a Hangzhou, in Cina, con una facciata vetrata moderna e un sistema di raffreddamento centralizzato. I ricercatori hanno utilizzato una stagione di raffreddamento con dati orari, circa 4.300 ore in totale, poi hanno limitato artificialmente quanta di questa storia ogni modello poteva vedere durante l’addestramento. In alcuni test i modelli hanno potuto imparare da solo il 10% dei dati, equivalente a poco più di due settimane di registrazioni. Tra le quattro versioni del predittore, tre usavano carichi derivati dall’aria fresca o dalle pareti e finestre come segnali guida, mentre una quarta si basava esclusivamente su dati storici di raffreddamento e meteo. Tutti i modelli cercavano di prevedere il profilo orario del raffreddamento per il giorno successivo.
Previsioni più accurate e più stabili
Quando i dati di addestramento erano scarsi, le differenze tra gli approcci erano nette. Con solo il 10% dei dati disponibili, il modello puramente guidato dai dati spesso non coglieva la rapida crescita del fabbisogno mattutino di raffreddamento all’arrivo dei lavoratori e sottostimava i picchi nelle calde ore pomeridiane. I suoi errori variavano molto a seconda dei giorni usati per l’addestramento. Al contrario, tutte e tre le versioni ibride seguivano molto meglio il momento e l’entità dei picchi e mostravano una dispersione degli errori molto minore. In media, i modelli ibridi dimezzavano l’errore tipico di previsione e riducevano la dispersione degli errori di quasi un ordine di grandezza rispetto al modello di base. La variante più semplice, che usava solo il carico dovuto all’aria fresca come informazione aggiuntiva, offriva un equilibrio particolarmente interessante tra accuratezza, stabilità e facilità di implementazione.
Cosa significa per gli edifici reali
Per i proprietari e i gestori energetici degli edifici, il messaggio principale è che un po’ di fisica aiuta molto. Integrando stime semplici e facili da calcolare di come l’aria fresca e l’involucro edilizio contribuiscono al fabbisogno di raffreddamento all’interno di un modello di apprendimento, diventa possibile ottenere previsioni utili per il giorno successivo anche nei primi mesi di esercizio, quando i dati storici sono ancora scarsi. Lo studio mostra che questo approccio ibrido conoscenza-dati può contenere l’overfitting, mantenere i costi di addestramento modesti e fornire indicazioni affidabili per la programmazione dei gruppi frigoriferi e degli accumuli. In termini pratici, combinare una conoscenza ingegneristica di base con strumenti dati moderni aiuta gli edifici a restare confortevoli, ridurre gli sprechi e collaborare meglio con una rete elettrica in evoluzione.
Citazione: Chen, J., Sun, T., Zhang, Y. et al. Deployable knowledge–data hybrid models for day-ahead cooling load prediction under data scarcity: a case study and performance validation. Sci Rep 16, 15079 (2026). https://doi.org/10.1038/s41598-026-45325-3
Parole chiave: previsione del carico di raffreddamento, energia degli edifici, modellazione ibrida, scarsità di dati, deep learning