Clear Sky Science · nl
Inzetbare kennis–data hybride modellen voor voorspellng van koellast één dag vooruit bij beperkte data: een casestudy en prestatievalidatie
Waarom het voorspellen van gebouwkoeling ertoe doet
Naarmate steden groeien en hittegolven vaker voorkomen, zijn grote kantoorgebouwen sterk afhankelijk van airconditioning. Weten wat de koelingsvraag voor morgen zal zijn helpt gebouwbeheerders om elektriciteit verstandig in te kopen, chillers efficiënt te laten draaien en het elektriciteitsnet te ondersteunen dat steeds meer zon- en windenergie toevoegt. Toch beschikken de nieuwste en meest efficiënte gebouwen vaak over slechts weinig data uit hun eerste maanden van exploitatie, wat het moeilijk maakt voor standaard AI-tools om hun koelingsbehoefte betrouwbaar te voorspellen.
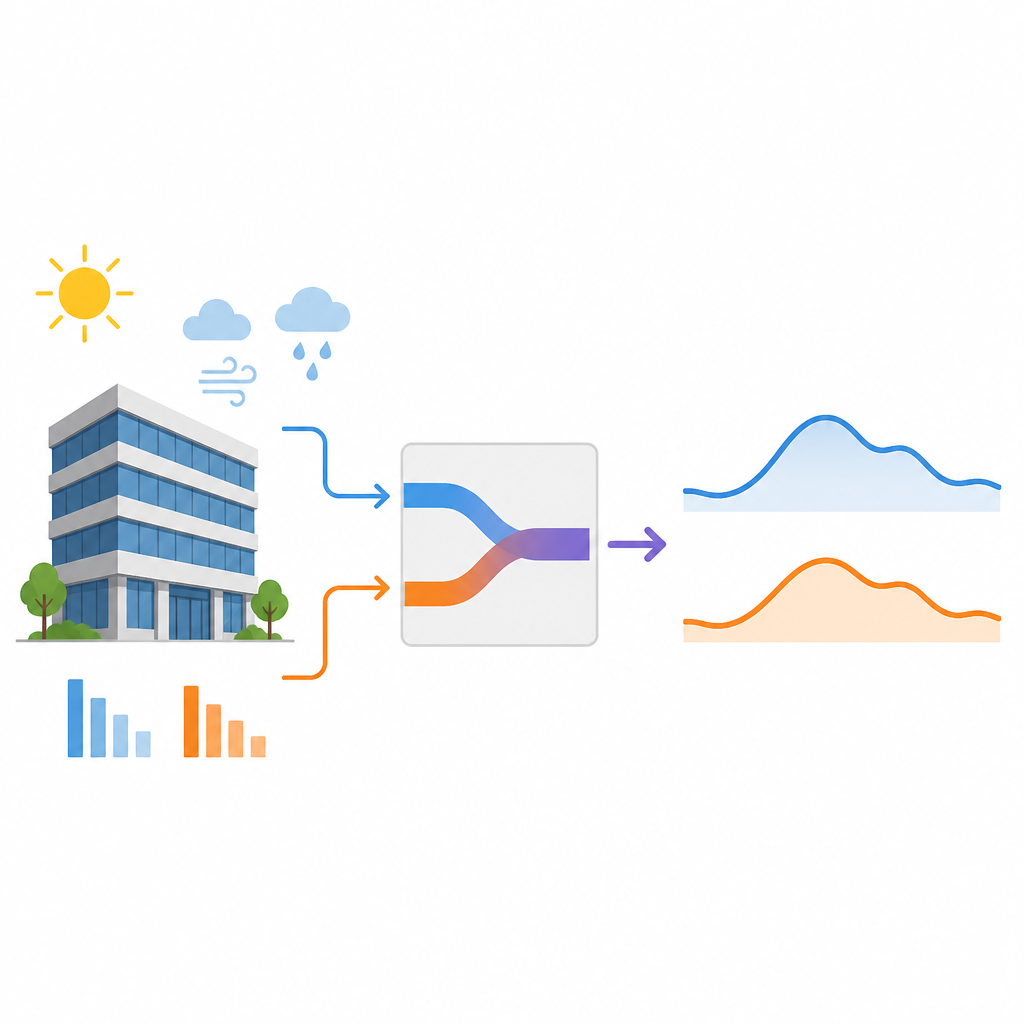
De uitdaging van beperkte data
Veel huidige voorspellingsinstrumenten behandelen een gebouw als een black box. Ze voeren verleden energiegebruik, weersgegevens en schema’s in, en laten een leeralgoritme naar patronen zoeken. Deze datahongerige modellen kunnen goed werken wanneer er jaren aan hoogwaardige gegevens beschikbaar zijn. In een nieuw of recent gerenoveerd gebouw bestaat echter slechts een korte historie. Onder deze omstandigheden hebben puur op data gebaseerde modellen de neiging om zich vast te klampen aan eigenaardigheden in de beperkte data, plotselinge sprongen in de vraag te missen en voorspellingen te geven die sterk schommelen van dag tot dag. Dit is vooral problematisch voor dag-vooruit planning, wanneer beheerders de koelingsapparatuur moeten inroosters en 24 uur van tevoren met de elektriciteitsmarkt moeten samenwerken.
Eenvoudige fysica combineren met moderne leermethoden
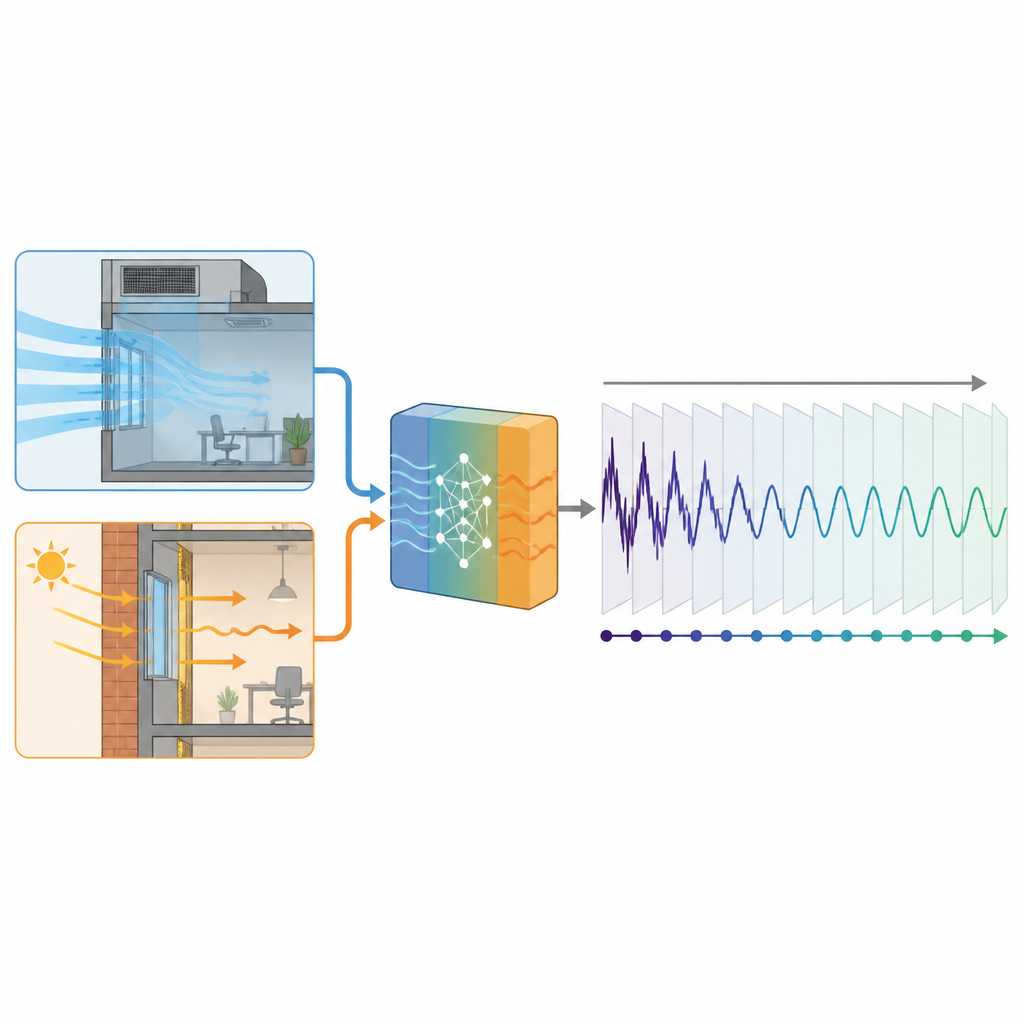
De studie introduceert een praktische tussenweg tussen gedetailleerde fysicasimulaties en puur datamining. In plaats van te proberen elke warmtebron in het gebouw te modelleren, richten de auteurs zich op twee bijdragen die berekend kunnen worden met informatie die de meeste gebouwen al hebben: de warmte die binnenkomt met buitenlucht en de warmte die door wanden en ramen lekt. Met basisformules voor warmtetransport zetten ze weersvoorspellingen, glas-eigenschappen en ventilatieschema’s om in ruwe, fysisch plausibele schattingen van deze belastingen. Deze schattingen vervangen de gemeten koelingsvraag niet, maar worden toegevoegd als extra invoer die een deep learning-model begeleidt dat convectieve en recurrente netwerklaagcombinaties gebruikt.
De hybride aanpak testen in een echt kantoorgebouw
De aanpak werd getest in een 23 verdiepingen tellend kantoorgebouw in Hangzhou, China, met een moderne glazen gevel en een centraal koelsysteem. De onderzoekers gebruikten één koelseizoen aan uurlijkse data, ongeveer 4.300 uur in totaal, en beperkten vervolgens kunstmatig hoeveel van deze historie elk model tijdens training mocht zien. In sommige tests konden de modellen leren van slechts 10 procent van de data, wat overeenkomt met iets meer dan twee weken aan gegevens. Over vier versies van de voorspeller gebruikten drie fysica-gebaseerde schattingen van ventilatielucht of wand- en raambilasten als begeleidende signalen, terwijl een vierde uitsluitend leunde op verleden koeling- en weerdata. Alle modellen probeerden het koelingsprofiel voor de volgende dag uur voor uur te voorspellen.
Nauwkeurigere en stabielere voorspellingen
Wanneer trainingsdata schaars waren, waren de verschillen tussen de benaderingen duidelijk. Met slechts 10 procent van de data beschikbaar, miste het puur data-gedreven model vaak de scherpe ochtendstijging in koeling wanneer medewerkers aankomen en onderschatte het hete middagpieken. De fouten varieerden sterk afhankelijk van welke dagen voor training werden gebruikt. In tegenstelling daarmee volgden alle drie hybride varianten de timing en hoogte van pieken veel nauwkeuriger en toonden ze veel minder spreiding in hun fouten. Gemiddeld halveerden de hybride modellen de typische voorspellingsfout en verminderden ze de foutspreiding bijna met een orde van grootte vergeleken met de basislijn. De eenvoudigste variant, die alleen de ventilatielast als extra informatie gebruikte, bood een bijzonder aantrekkelijke balans tussen nauwkeurigheid, stabiliteit en eenvoudige implementatie.
Wat dit betekent voor echte gebouwen
Voor gebouwbezitters en energiemanagers is de kernboodschap dat een beetje fysica veel oplevert. Door eenvoudige, makkelijk te berekenen schattingen van hoe buitenlucht en de gebouwschil bijdragen aan de koelingsbehoefte in een leermodel op te nemen, wordt het mogelijk om nuttige dag-vooruit voorspellingen te krijgen, zelfs in de vroege maanden van exploitatie wanneer historische data nog schaars zijn. De studie laat zien dat deze kennis-data hybride benadering overfitting kan temmen, de trainingskosten bescheiden houdt en betrouwbare aanwijzingen biedt voor het inroosteren van chillers en opslag. Simpel gezegd: het combineren van basis engineeringinzicht met moderne datatools helpt gebouwen comfortabel te houden, verspilling te verminderen en soepeler samen te werken met een veranderend elektriciteitsnet.
Bronvermelding: Chen, J., Sun, T., Zhang, Y. et al. Deployable knowledge–data hybrid models for day-ahead cooling load prediction under data scarcity: a case study and performance validation. Sci Rep 16, 15079 (2026). https://doi.org/10.1038/s41598-026-45325-3
Trefwoorden: voorspelling koellast, gebouwenergie, hybride modellering, datarschaarste, deep learning