Clear Sky Science · pl
Modele hybrydowe wiedzy i danych do prognozowania dobowego zapotrzebowania na chłodzenie przy niewielkich zasobach danych: studium przypadku i walidacja wydajności
Dlaczego prognozowanie chłodzenia budynków ma znaczenie
W miarę rozrastania się miast i nasilenia fal upałów, duże biurowce coraz bardziej polegają na klimatyzacji. Znajomość zapotrzebowania na chłodzenie na jutro pozwala operatorom budynków mądrze kupować energię elektryczną, efektywnie obsługiwać agregaty chłodnicze i wspierać sieć z rosnącym udziałem energii słonecznej i wiatrowej. Jednak najnowsze i najbardziej efektywne budynki często mają bardzo mało danych z pierwszych miesięcy eksploatacji, co utrudnia standardowym narzędziom sztucznej inteligencji wiarygodne prognozowanie ich potrzeb chłodniczych.
Problem ograniczonych danych
Wiele obecnych narzędzi prognostycznych traktuje budynek jak czarną skrzynkę. Do modelu podaje się zużycie energii z przeszłości, pogodę i harmonogramy, a algorytm uczy się wzorców. Te łakome na dane modele potrafią działać dobrze, gdy dostępne są wieloletnie, wysokiej jakości zapisy. Jednak w nowym lub właśnie wyremontowanym budynku istnieje tylko krótka historia pomiarów. W takich warunkach modele oparte wyłącznie na danych mają tendencję do dopasowywania się do przypadkowych cech ograniczonego zbioru, pomijają nagłe skoki zapotrzebowania i generują prognozy, które znacznie wahają się z dnia na dzień. Jest to szczególnie problematyczne przy planowaniu na dobę naprzód, gdy operatorzy muszą zaplanować pracę urządzeń chłodniczych i współpracę z rynkiem energii z pełnym 24‑godzinnym wyprzedzeniem.
Połączenie prostej fizyki z nowoczesnym uczeniem
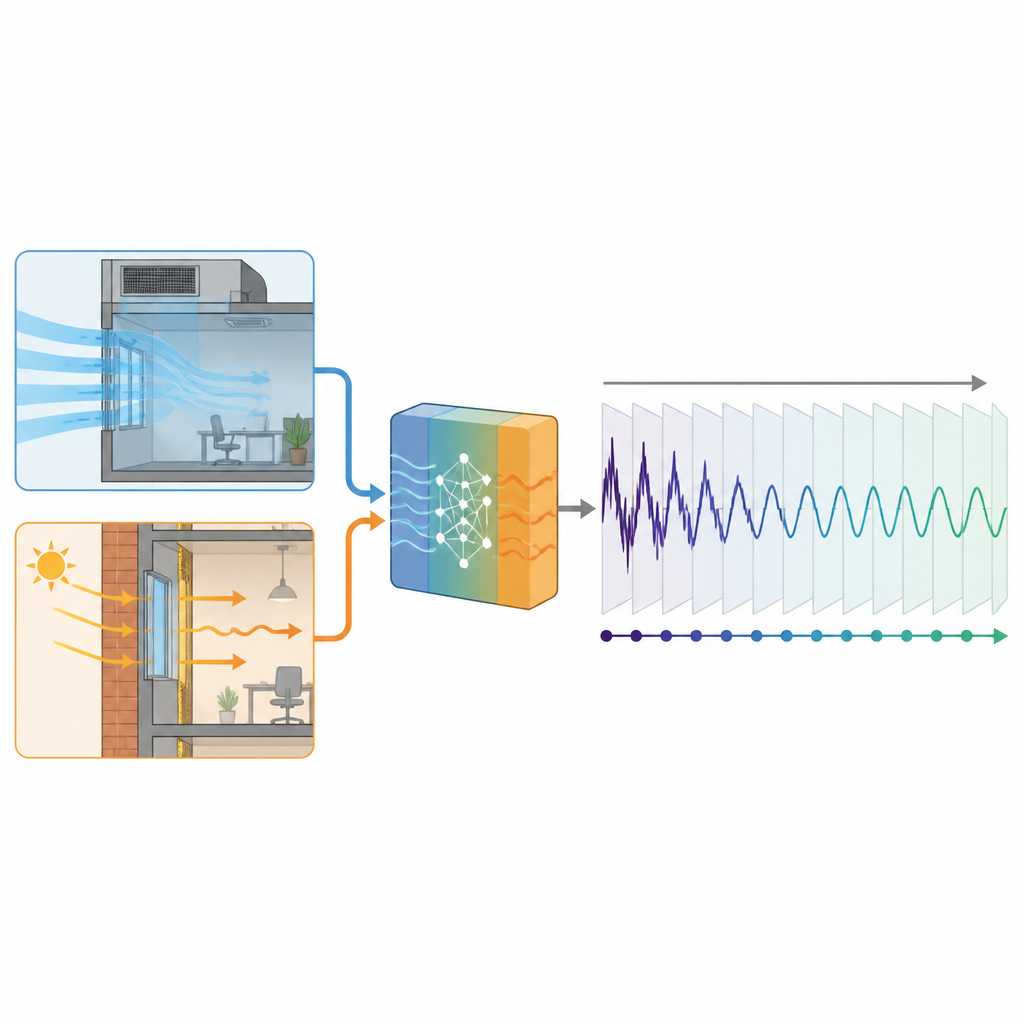
W badaniu zaproponowano praktyczny kompromis między szczegółowymi symulacjami fizycznymi a czystym wydobywaniem wzorców z danych. Zamiast modelować każdy źródło ciepła w budynku, autorzy skupili się na dwóch wkładach, które można obliczyć z informacji, jakie większość budynków już posiada: ciepło wnoszone przez świeże powietrze z zewnątrz oraz ciepło przenikające przez ściany i okna. Korzystając z podstawowych wzorów wymiany ciepła, zamieniają prognozy pogody, właściwości szyb i harmonogramy wentylacji na przybliżone, fizycznie sensowne estymaty tych obciążeń. Te estymaty nie zastępują mierzonego zapotrzebowania na chłodzenie, lecz są dodawane jako dodatkowe wejścia, które ukierunkowują model głębokiego uczenia łączący warstwy konwolucyjne i rekurencyjne.
Testowanie pomysłu hybrydowego na prawdziwym wieżowcu biurowym
Metodę przetestowano w 23‑piętrowym biurowcu w Hangzhou w Chinach, z nowoczesną szklaną elewacją i centralnym systemem chłodzenia. Badacze wykorzystali jeden sezon chłodniczy danych godzinowych, około 4300 godzin łącznie, a następnie sztucznie ograniczyli, jak dużą część tej historii każdy model mógł widzieć podczas treningu. W niektórych testach modele uczyły się tylko na 10% danych, co odpowiada nieco ponad dwóm tygodniom zapisu. W czterech wersjach predyktora trzy używały fizycznie obliczonych obciążeń związanych ze świeżym powietrzem lub ze ścianami i oknami jako sygnałów pomocniczych, podczas gdy czwarta polegała wyłącznie na przeszłym zapotrzebowaniu na chłodzenie i danych pogodowych. Wszystkie modele próbowały prognozować profil chłodzenia na następny dzień godzinę po godzinie.
Dokładniejsze i bardziej stabilne prognozy
Gdy danych treningowych było mało, różnice między podejściami były wyraźne. Przy dostępności jedynie 10% danych model czysto oparty na danych często nie wychwytywał ostrego porannego wzrostu chłodzenia związany z przybyciem pracowników i niedoszacowywał gorących szczytów popołudniowych. Jego błędy znacznie się różniły w zależności od tego, które dni posłużyły do treningu. W przeciwieństwie do tego wszystkie trzy wersje hybrydowe znacznie lepiej odwzorowywały czas i wysokość szczytów oraz wykazywały znacznie mniejsze rozproszenie błędów. Średnio modele hybrydowe zredukowały typowy błąd prognozy o około połowę i zmniejszyły rozrzut błędów prawie o rząd wielkości w porównaniu z modelem bazowym. Najprostszy wariant, który wykorzystywał wyłącznie obciążenie ze świeżego powietrza jako dodatkową informację, oferował szczególnie atrakcyjny kompromis między dokładnością, stabilnością i łatwością wdrożenia.
Co to oznacza dla rzeczywistych budynków
Dla właścicieli budynków i menedżerów energetyki główne przesłanie jest takie: trochę fizyki robi wielką różnicę. Włączając proste, łatwe do obliczenia estymaty tego, jak świeże powietrze i przegroda budynku wpływają na potrzeby chłodzenia, do modelu uczącego się, można uzyskać użyteczne prognozy na dobę naprzód nawet w pierwszych miesiącach eksploatacji, gdy dane historyczne są wciąż skąpe. Badanie pokazuje, że podejście hybrydowe wiedzy i danych może okiełznać przeuczanie, utrzymać umiarkowane koszty treningu i dostarczać wiarygodnych wskazówek do planowania pracy agregatów chłodniczych i magazynów. Mówiąc prościej, połączenie podstawowej wiedzy inżynierskiej z nowoczesnymi narzędziami analitycznymi pomaga utrzymać komfort, ograniczać straty i lepiej współpracować z ewoluującą siecią energetyczną.
Cytowanie: Chen, J., Sun, T., Zhang, Y. et al. Deployable knowledge–data hybrid models for day-ahead cooling load prediction under data scarcity: a case study and performance validation. Sci Rep 16, 15079 (2026). https://doi.org/10.1038/s41598-026-45325-3
Słowa kluczowe: prognozowanie zapotrzebowania na chłodzenie, energia budynku, modelowanie hybrydowe, niedobór danych, głębokie uczenie