Clear Sky Science · zh
使用渐进堆叠伪逆学习的古建筑图像分类
为何古建筑遇上现代算法
在中国各地,带有飞檐和复杂木栱的寺庙与宫殿正被大量拍摄。档案员与保护工作者需要快速整理这些图像,但人工目视分类既缓慢又带有主观性。本文提出了一种新的方法,教计算机更准确、更高效地识别和分类古建筑照片,助力在数字时代保护文化遗产。
这些建筑为何难以区分
中国古建筑充满重复的图式:弧形屋脊、檐下层叠的栱架、雕刻梁枋以及色彩斑斓的表面装饰。许多建筑在布局上相似,仅在屋脊弧度或栱形细节上有微妙差异。标准的图像识别系统通过逐步调整内部权重来学习,往往会被这些微妙差别或墙面颜色、光照等干扰因素所迷惑。当一次性用大批量图像训练时,它们也容易对某一区域或风格过拟合,从而降低对其他场所建筑的泛化能力。
更聪明地观察关键细节
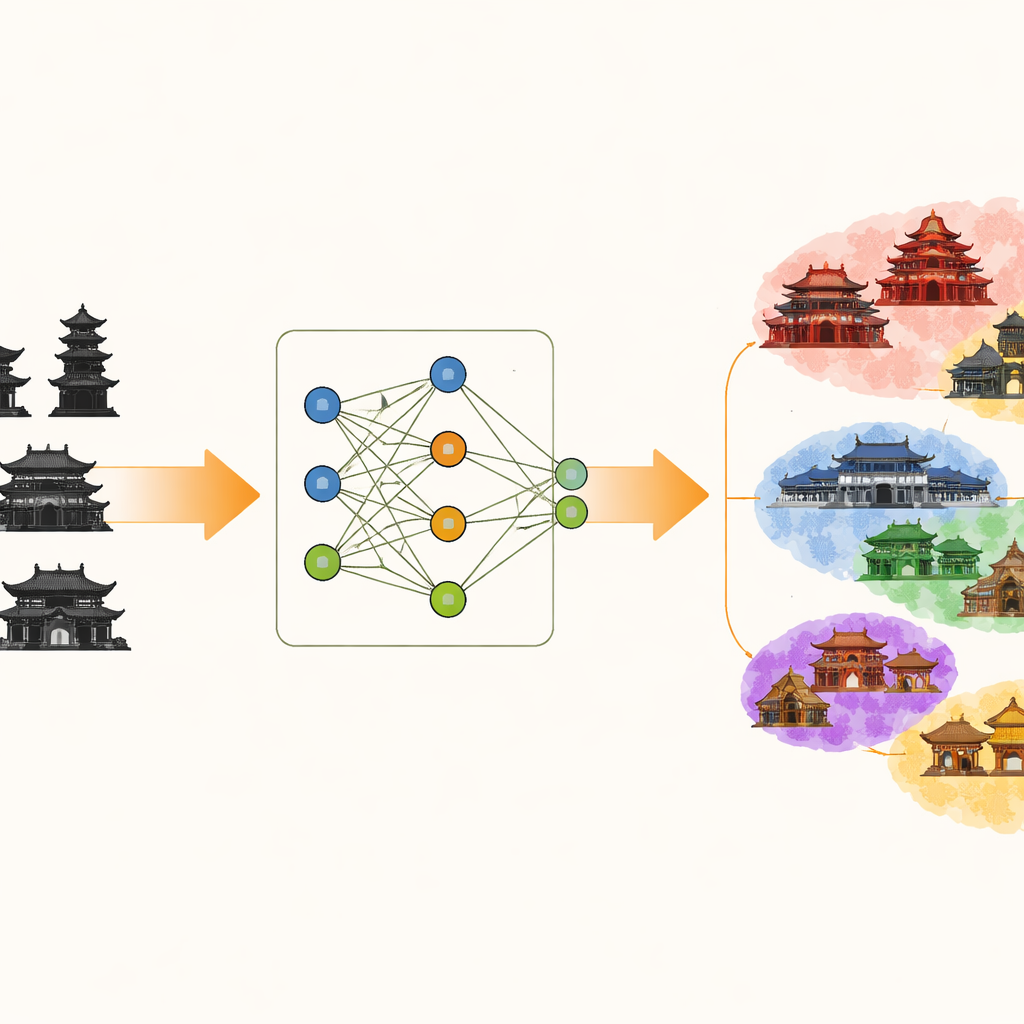
作者提出了一个名为“渐进堆叠伪逆学习的古建筑图像分类”(AAPSP)的框架。其核心是一个称为关键特征堆叠伪逆学习(KFSP)的模块。KFSP并非从完全随机的设置开始,而是构建了若干并行的“基学习器”,每个学习器以旨在匹配特定视觉特征的权重模式初始化。两个分支被调优为对连续、平滑的结构(如屋脊轮廓)尤其敏感,第三个分支则更擅长捕捉分散的纹理(如装饰图案)。一种称为伪逆学习的数学捷径使得这些分支基本上可以一次性训练完成,避免了传统深度学习那种缓慢的逐步权重更新。
让模型把注意力放在重要之处
仅有多个分支还不够;系统还必须决定哪个分支对每次判断最有帮助。为此,KFSP使用了一种注意力机制,衡量每个分支输出与真实建筑标签之间的匹配程度。更能捕捉典型要素的分支——例如斗拱的形状或脊饰的轮廓——在其输出合成时会自动获得更大影响力。这样堆叠形成的表征空间更贴近古建筑的“形态逻辑”,使得具有相似结构组件的建筑聚为一类,而风格不同的建筑则更清晰地分离开来。
从最有信息量的照片中学习
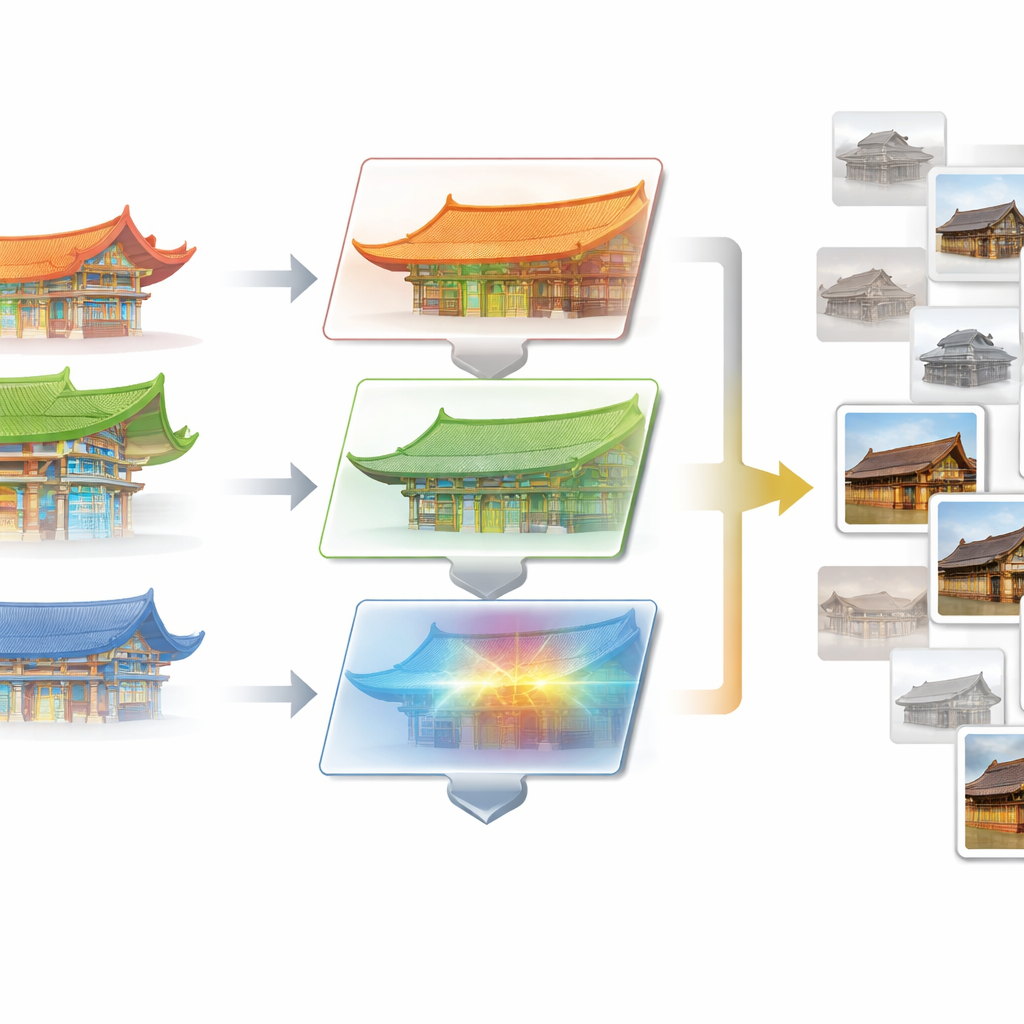
第二个核心模块渐进优化学习(POL)解决的是另一个问题:冗余的训练图像。数据集中许多照片展示了同一立面的几乎相同视角,提供的新信息很少。POL首先将数据分为初始训练集和更大的候选池。借鉴主动学习的思想,它分析当前模型对每张候选图像的分类置信度以及其特征的异常程度。那些既不确定又具区分性的照片——例如罕见的栱架组合或不寻常的屋顶搭配——会逐步被移入训练集。该循环重复进行,在不增加总图像数量的前提下,稳步丰富训练数据,加入具有挑战性和多样性的示例。
实际效果如何
作者在一个包含来自六座著名寺庙与宫殿的2,269张公开图像集合上测试了该方法。仅应用KFSP时,系统就已优于依赖完全随机投影的可比较方法。加入POL的渐进样本选择后,分类准确率进一步提升,精确率、召回率与F1值均有所上升。换言之,模型在正确判断上的可靠性增强,同时对不常见类别的识别能力也更强。研究还指出了一个尚存的难点:样本极少的类别仍然具有挑战性,因为即便是智能的学习器,在可供学习的多样性太少时也难以取得好表现。
这对文化遗产为何重要
通过有针对性地引导模型关注点与选择训练图像,AAPSP为整理和研究历史建筑照片提供了更精确的工具。对遗产工作者而言,这意味着更快地建立数字档案、更有力地支持建筑风格的定年与比较,以及更稳健地监测分布在不同区域的遗址。尽管该方法针对中国古建筑进行了定制,其核心思想——突出关键结构细节并渐进地聚焦于罕见但富信息的样本——也可推广到其他类型的文化对象,从雕塑到历史街景皆可借鉴。
引用: Cai, Z., Sun, X., Zhang, S. et al. Ancient architecture image classification with progressive stacking pseudoinverse learning. Sci Rep 16, 14626 (2026). https://doi.org/10.1038/s41598-026-44876-9
关键词: 古建筑, 图像分类, 文化遗产, 机器学习, 主动学习