Clear Sky Science · de
Bildklassifikation alter Architektur mit progressiv gestapeltem Pseudoinvers-Lernen
Warum alte Gebäude auf moderne Algorithmen treffen
In ganz China werden Tempel und Paläste mit geschwungenen Dächern und filigranen Holzkonsolelementen in großer Zahl fotografiert. Archivare und Denkmalpfleger müssen diese Bilder schnell sortieren, doch die manuelle Bewertung ist zeitaufwendig und subjektiv. Dieser Beitrag stellt einen neuen Ansatz vor, Computern beizubringen, Fotos antiker Gebäude genauer und effizienter zu erkennen und zu klassifizieren, und leistet damit einen Beitrag zum Schutz des Kulturerbes im digitalen Zeitalter.
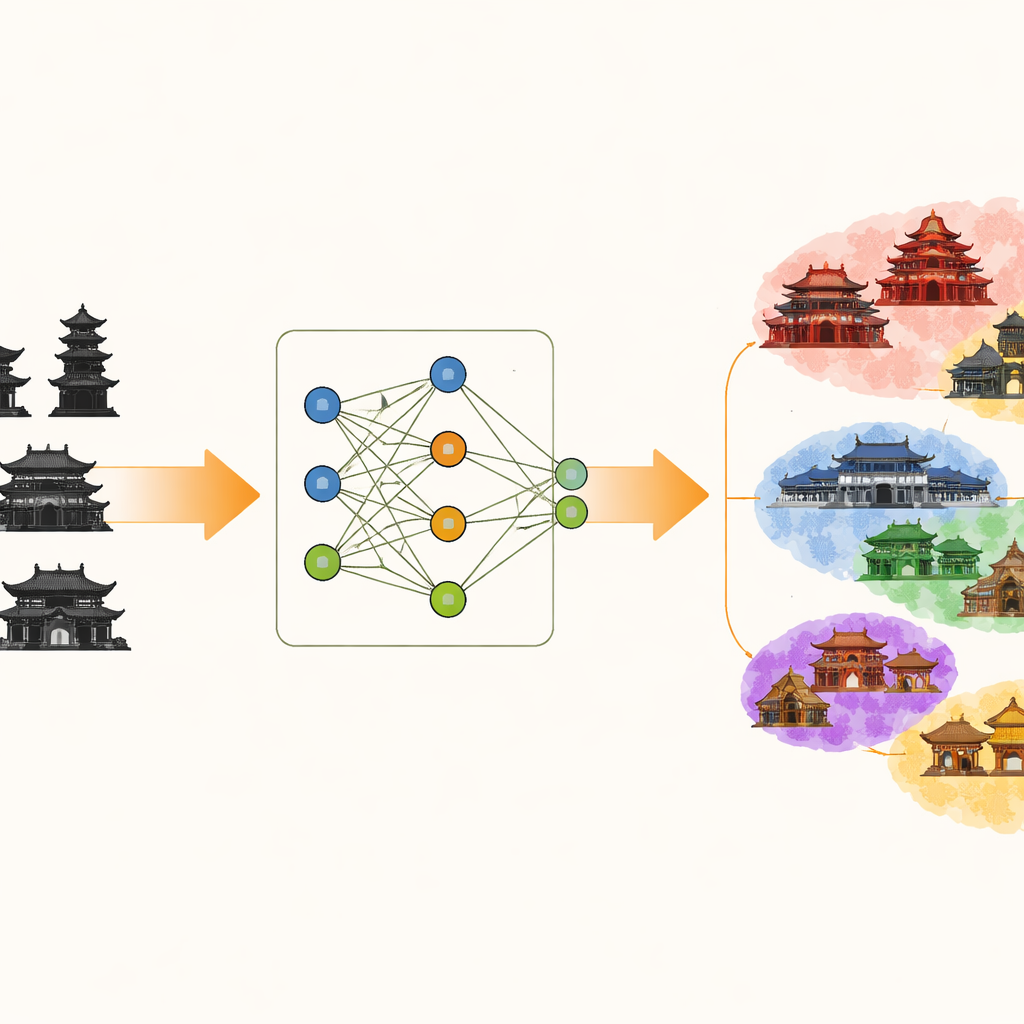
Was es schwierig macht, diese Gebäude auseinanderzuhalten
Die alte chinesische Architektur ist reich an wiederkehrenden Mustern: geschwungene Dachlinien, geschichtete Konsolen unter den Traufen, geschnitzte Balken und farbenfrohe Oberflächendekorationen. Viele Gebäude folgen ähnlichen Grundrissen und unterscheiden sich nur durch feine Variationen der Dachkrümmung oder Konsolenform. Standarderkennungsmodelle, die durch schrittweise Anpassung interner Gewichte lernen, können von diesen feingliedrigen Unterschieden sowie von ablenkenden Merkmalen wie Wandfarbe oder Beleuchtung irritiert werden. Trainiert man sie auf einmal mit großen Bildmengen, neigen sie außerdem zur Überanpassung an eine Region oder einen Stil, was ihre Fähigkeit verringert, auf Gebäude anderer Orte zu verallgemeinern.
Eine schlauere Betrachtung der Schlüsseldetails
Die Autorinnen und Autoren stellen ein Rahmenkonzept vor, genannt Ancient Architecture Image Classification with Progressive Stacking Pseudoinverse Learning (AAPSP). Im Zentrum steht ein Modul namens Key Features Stacking Pseudoinverse Learning (KFSP). Statt bei völlig zufälligen Anfangswerten zu starten, baut KFSP mehrere parallele „Basislernende“ auf, die jeweils mit Gewichtsmustern initialisiert sind, die auf bestimmte visuelle Merkmale zugeschnitten sind. Zwei Zweige werden besonders empfindlich für glatte, zusammenhängende Strukturen wie Dachkonturen eingestellt, ein dritter erfasst stärker verstreute Texturen wie dekorative Motive. Ein mathematischer Kurzbefehl, das Pseudoinvers-Lernen, ermöglicht es, diese Zweige im Wesentlichen in einem einzigen Schritt zu trainieren und so die langsamen, schrittweisen Gewichtsaktualisierungen traditioneller tiefen Lernverfahren zu vermeiden.
Das Modell dort aufmerksam sein lassen, wo es zählt
Mehrere Zweige allein reichen nicht aus; das System muss auch entscheiden, welcher Zweig für eine bestimmte Entscheidung am hilfreichsten ist. Dazu nutzt KFSP einen Aufmerksamkeitsmechanismus, der misst, wie gut die Ausgaben jedes Zweigs mit den tatsächlichen Gebäudelabels übereinstimmen. Zweige, die markante Merkmale besser erfassen – etwa die Form eines Kragbogens oder die Kontur eines Firstschmucks – erhalten automatisch mehr Gewicht, wenn ihre Ausgaben kombiniert werden. Diese gestapelte Repräsentation bildet einen Merkmalsraum, der enger der zugrunde liegenden „Logik der Form“ in der alten Architektur folgt, sodass Gebäude mit ähnlichen Bauelementen zusammenclustern und unterschiedliche Stile deutlicher separiert werden.
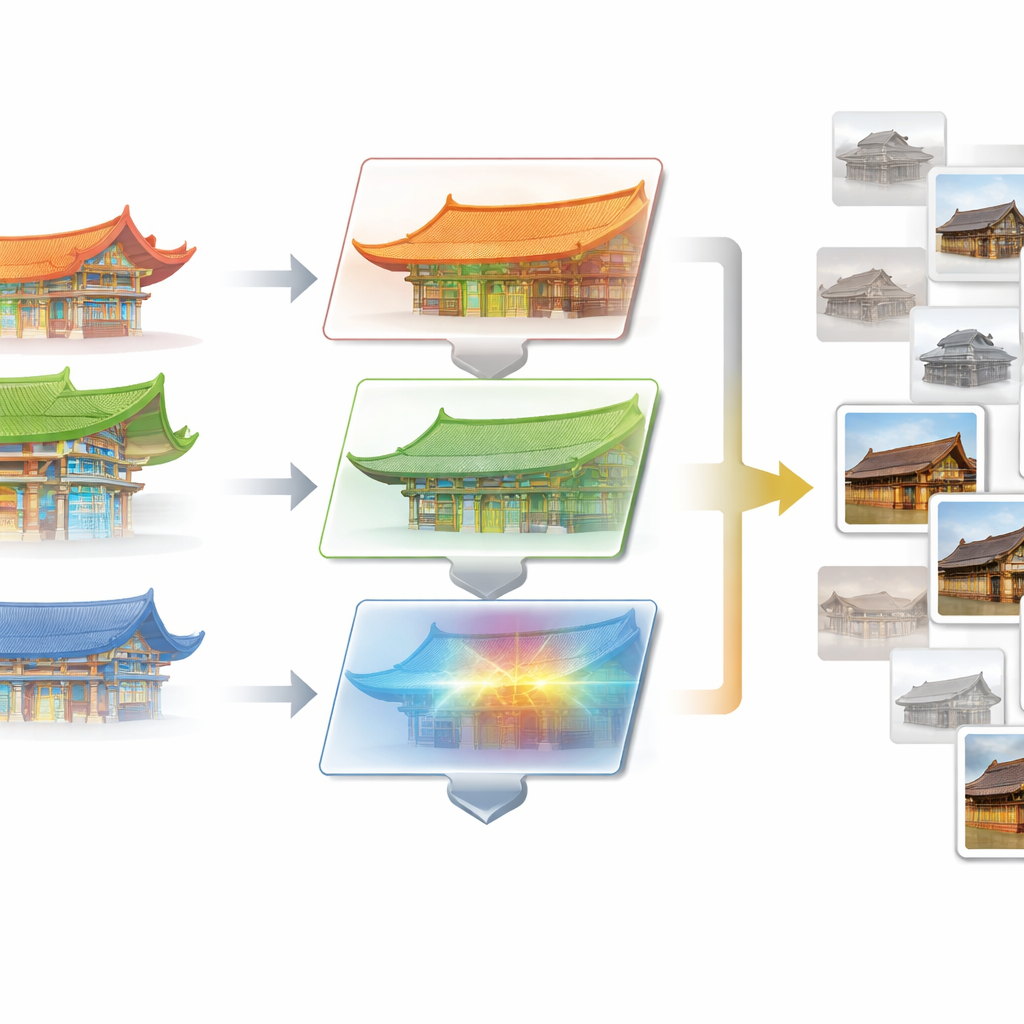
Vom informativsten Bild lernen
Das zweite Kernmodul, Progressive Optimization Learning (POL), greift ein anderes Problem an: redundante Trainingsbilder. Viele Fotos im Datensatz zeigen nahezu identische Ansichten derselben Fassade und liefern kaum neue Informationen. POL beginnt damit, die Daten in eine anfängliche Trainingsmenge und einen größeren Kandidatenpool aufzuteilen. Nach dem Prinzip des aktiven Lernens analysiert es, wie sicher das aktuelle Modell jedes Kandidatenbild klassifiziert und wie ungewöhnlich seine Merkmale sind. Bilder, die sowohl unsicher als auch auffällig sind – etwa seltene Konsolenanordnungen oder ungewöhnliche Dachkombinationen – werden schrittweise in die Trainingsmenge übernommen. Dieser Zyklus wiederholt sich und bereichert die Trainingsdaten stetig mit herausfordernden und vielfältigen Beispielen, ohne die Gesamtzahl der verwendeten Bilder zu erhöhen.
Wie gut funktioniert das in der Praxis
Die Autorinnen und Autoren testeten ihren Ansatz an einer öffentlichen Sammlung von 2.269 Bildern aus sechs bekannten Tempeln und Palästen. Nach Anwendung von KFSP allein übertraf das System bereits eine vergleichbare Methode, die auf völlig zufällige Projektionen setzte. Mit der ergänzten, progressiven Stichprobenwahl durch POL verbesserte sich die Klassifikationsgenauigkeit weiter; auch Präzision, Recall und F1-Score stiegen. Anders ausgedrückt: Das Modell wurde verlässlicher bei korrekten Vorhersagen und besser darin, seltener vorkommende Kategorien zu erkennen. Die Studie machte jedoch eine verbleibende Schwierigkeit deutlich: Klassen mit sehr wenigen Bildern bleiben problematisch, weil selbst ein ausgeklügelter Lernansatz an seine Grenzen stößt, wenn zu wenig Vielfalt zum Lernen vorhanden ist.
Warum das für das Kulturerbe wichtig ist
Indem AAPSP sowohl gezielt steuert, worauf das Modell seine Aufmerksamkeit richtet, als auch welche Bilder es lernt, bietet es ein präziseres Werkzeug zum Sortieren und Analysieren historischer Bauaufnahmen. Für Fachleute im Bereich Denkmalpflege bedeutet das schnellere Erstellung digitaler Archive, bessere Unterstützung bei Datierung und Vergleich architektonischer Stile sowie robustere Überwachung von Stätten in verschiedenen Regionen. Obwohl die Methode auf die chinesische alte Architektur zugeschnitten ist, ließen sich die zentralen Ideen – Hervorhebung wichtiger Strukturdetails und progressive Konzentration auf seltene, informative Beispiele – auf andere Arten von Kulturobjekten übertragen, von Skulpturen bis zu historischen Straßenzügen.
Zitation: Cai, Z., Sun, X., Zhang, S. et al. Ancient architecture image classification with progressive stacking pseudoinverse learning. Sci Rep 16, 14626 (2026). https://doi.org/10.1038/s41598-026-44876-9
Schlüsselwörter: alte Architektur, Bildklassifikation, Kulturerbe, maschinelles Lernen, aktives Lernen