Clear Sky Science · it
Classificazione di immagini di architettura antica con apprendimento progressivo a pseudoinverso a impilamento
Perché gli edifici antichi incontrano gli algoritmi moderni
In tutta la Cina, templi e palazzi con tetti spioventi e complessi supporti lignei vengono fotografati in grandi quantità. Archivisti e conservatori devono classificare rapidamente queste immagini, ma farlo a occhio è lento e soggettivo. Questo articolo presenta un nuovo modo per insegnare ai computer a riconoscere e classificare le foto di edifici antichi in modo più accurato ed efficiente, contribuendo a proteggere il patrimonio culturale nell’era digitale.
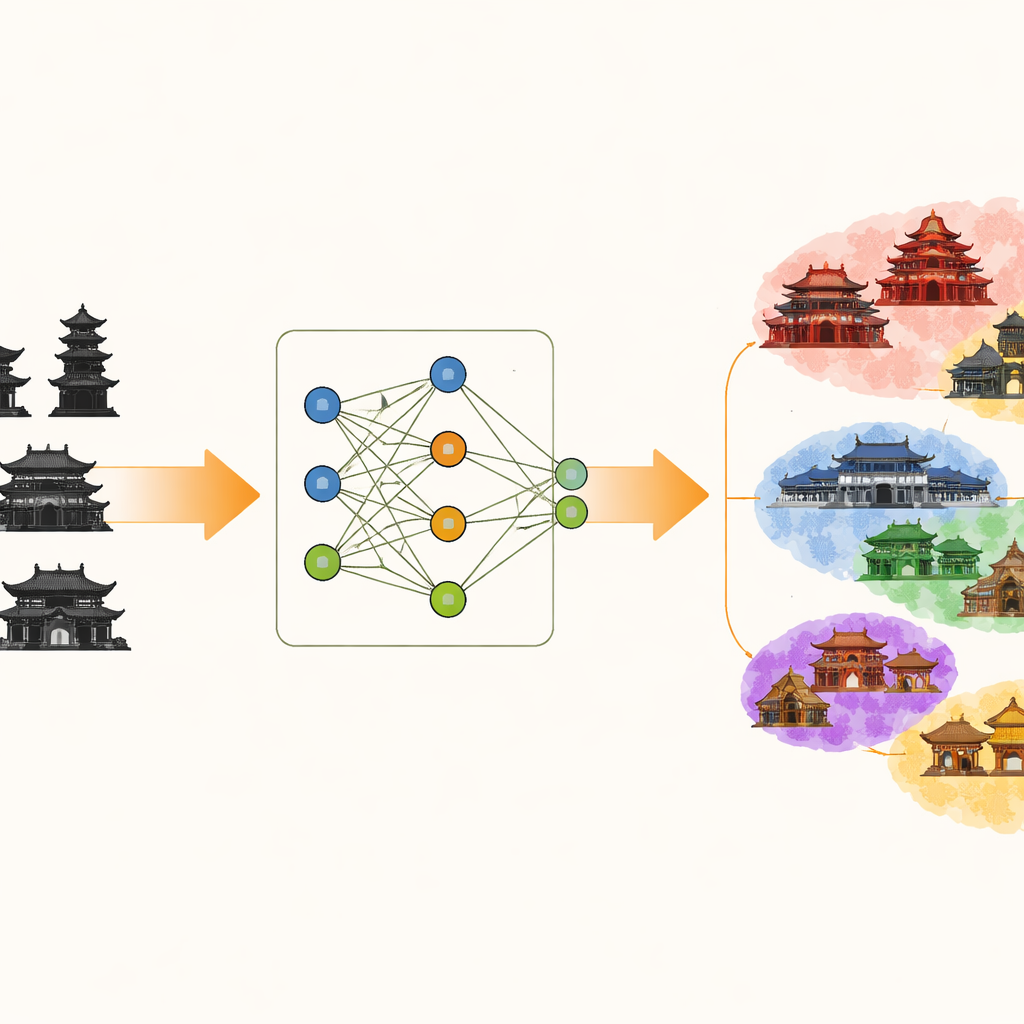
Perché è difficile distinguere questi edifici
L’architettura cinese antica è ricca di motivi ripetuti: linee di colmo curve, file di supporti sotto le grondaie, travi scolpite e decorazioni policrome. Molti edifici condividono planimetrie simili, differendo solo per sottili variazioni nella curvatura del tetto o nella forma dei supporti. I sistemi standard di riconoscimento delle immagini, che apprendono regolando gradualmente pesi interni, possono essere confusi da queste differenze fini e da elementi distraenti come il colore delle pareti o l’illuminazione. Tendono inoltre a sovraadattarsi a una regione o a uno stile quando vengono addestrati tutti insieme su un grande lotto di immagini, riducendo la capacità di generalizzare ad edifici di altri siti.
Un modo più intelligente per osservare i dettagli chiave
Gli autori introducono un framework chiamato classificazione di immagini di architettura antica con apprendimento progressivo a pseudoinverso a impilamento (AAPSP). Al suo centro c’è un modulo denominato apprendimento a pseudoinverso per impilamento delle caratteristiche chiave (KFSP). Invece di partire da impostazioni completamente casuali, KFSP costruisce diversi “base learner” paralleli, ciascuno inizializzato con schemi di pesi progettati per corrispondere a particolari tratti visivi. Due rami sono congegnati per essere particolarmente sensibili a strutture lisce e continue come i profili dei tetti, mentre un terzo è tarato per captare texture più diffuse come i motivi decorativi. Una scorciatoia matematica nota come apprendimento per pseudoinversa permette di addestrare questi rami in sostanza in un’unica soluzione, evitando i lenti aggiornamenti passo dopo passo dei pesi tipici del deep learning tradizionale.
Lasciare che il modello presti attenzione dove conta
Avere più rami non basta; il sistema deve anche decidere quale ramo è più utile per ciascuna decisione. Per questo KFSP utilizza un meccanismo di attenzione che misura quanto l’output di ciascun ramo corrisponde alle etichette reali degli edifici. I rami che catturano meglio elementi caratteristici — come la forma di un arco a secchio o il profilo di un ornamento di colmo — ricevono automaticamente maggiore influenza quando i loro output vengono combinati. Questa rappresentazione impilata forma uno spazio delle caratteristiche che segue più da vicino la “logica della forma” propria dell’architettura antica, così che edifici con componenti strutturali simili si raggruppano e quelli con stili diversi si separano più chiaramente.
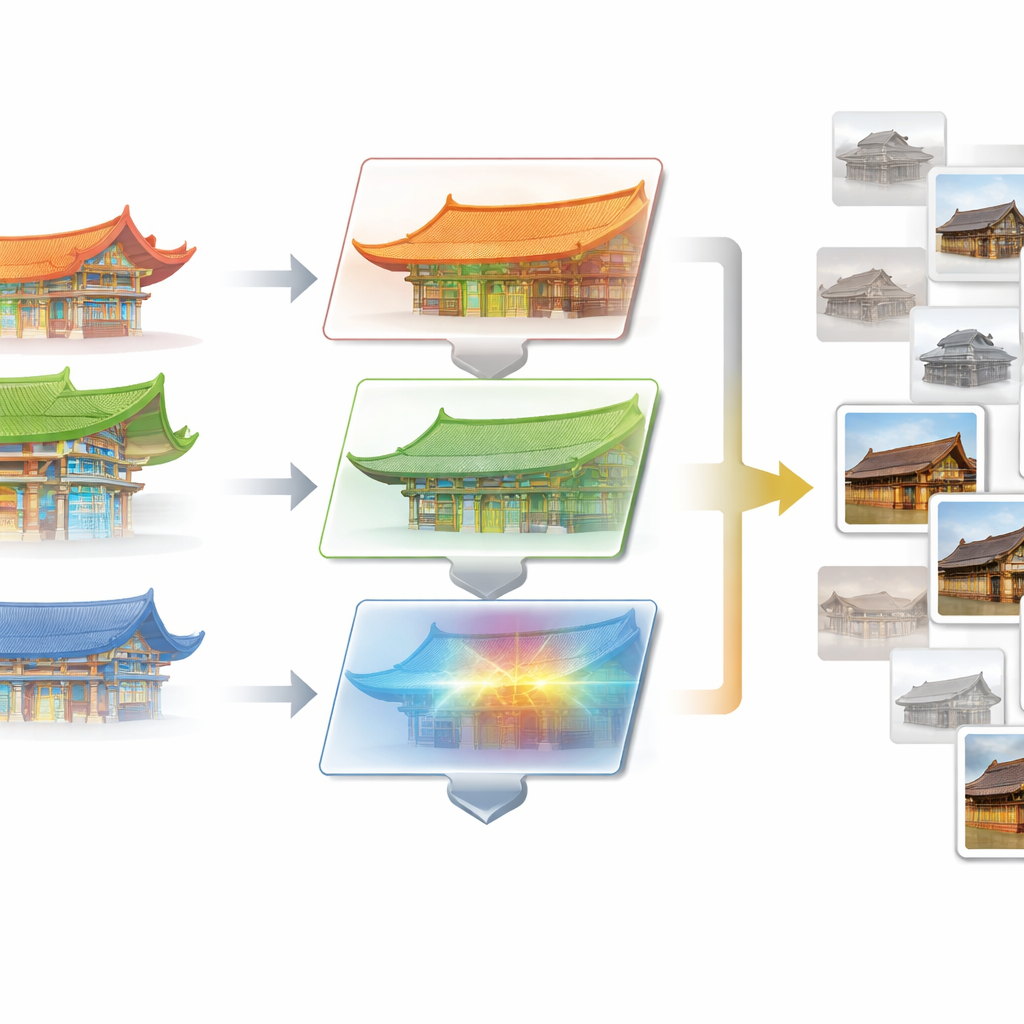
Imparare dalle foto più informative
Il secondo modulo principale, apprendimento di ottimizzazione progressiva (POL), affronta un problema diverso: le immagini di addestramento ridondanti. Molte foto nel dataset mostrano viste quasi identiche della stessa facciata, offrendo poche informazioni nuove. POL inizia suddividendo i dati in un set di addestramento iniziale e in un pool di candidati più ampio. Utilizzando idee dall’apprendimento attivo, analizza con quanta sicurezza il modello corrente classifica ciascuna immagine candidata e quanto insolite appaiono le sue caratteristiche. Le foto che sono sia incerte sia distintive — come rare disposizioni di supporti o combinazioni di tetto inconsuete — vengono gradualmente spostate nel set di addestramento. Questo ciclo si ripete, arricchendo costantemente i dati di addestramento con esempi impegnativi e diversi senza aumentare il numero totale di immagini utilizzate.
Quanto funziona nella pratica
Gli autori hanno testato il loro approccio su una raccolta pubblica di 2.269 immagini provenienti da sei templi e palazzi famosi. Applicando solo KFSP, il sistema ha già superato un metodo comparabile basato su proiezioni completamente casuali. Quando è stata aggiunta la selezione progressiva dei campioni di POL, l’accuratezza di classificazione è migliorata ulteriormente e sono aumentate le misure di precisione, richiamo e F1 score. In altre parole, il modello è diventato sia più affidabile nelle predizioni corrette sia più efficace nell’individuare categorie meno comuni. Lo studio ha inoltre messo in luce una difficoltà residua: le classi con pochissime immagini restano problematiche, perché anche un apprendimento sofisticato fatica quando manca varietà su cui basarsi.
Perché questo è importante per il patrimonio culturale
Guidando con cura sia ciò a cui il modello presta attenzione sia quali immagini apprende, AAPSP offre uno strumento più preciso per ordinare e studiare le foto di edifici storici. Per i professionisti del patrimonio ciò significa creare archivi digitali più rapidamente, supportare meglio la datazione e il confronto degli stili architettonici e monitorare in modo più robusto siti diffusi su diverse regioni. Pur essendo il metodo tarato sull’architettura antica cinese, le idee di base — mettere in evidenza dettagli strutturali chiave e concentrarsi progressivamente su esempi rari ma informativi — potrebbero essere adattate ad altri tipi di oggetti culturali, dalle sculture ai paesaggi urbani storici.
Citazione: Cai, Z., Sun, X., Zhang, S. et al. Ancient architecture image classification with progressive stacking pseudoinverse learning. Sci Rep 16, 14626 (2026). https://doi.org/10.1038/s41598-026-44876-9
Parole chiave: architettura antica, classificazione di immagini, patrimonio culturale, apprendimento automatico, apprendimento attivo