Clear Sky Science · es
Clasificación de imágenes de arquitectura antigua con aprendizaje por pseudoinversa y apilamiento progresivo
Por qué los edificios antiguos se encuentran con algoritmos modernos
En toda China, templos y palacios con tejados curvos y ménsulas de madera intrincadas están siendo fotografiados en grandes cantidades. Archivistas y conservadores necesitan clasificar estas imágenes rápidamente, pero hacerlo a simple vista es lento y subjetivo. Este artículo presenta una nueva forma de enseñar a las máquinas a reconocer y clasificar fotos de edificios antiguos con mayor precisión y eficiencia, ayudando a proteger el patrimonio cultural en la era digital.
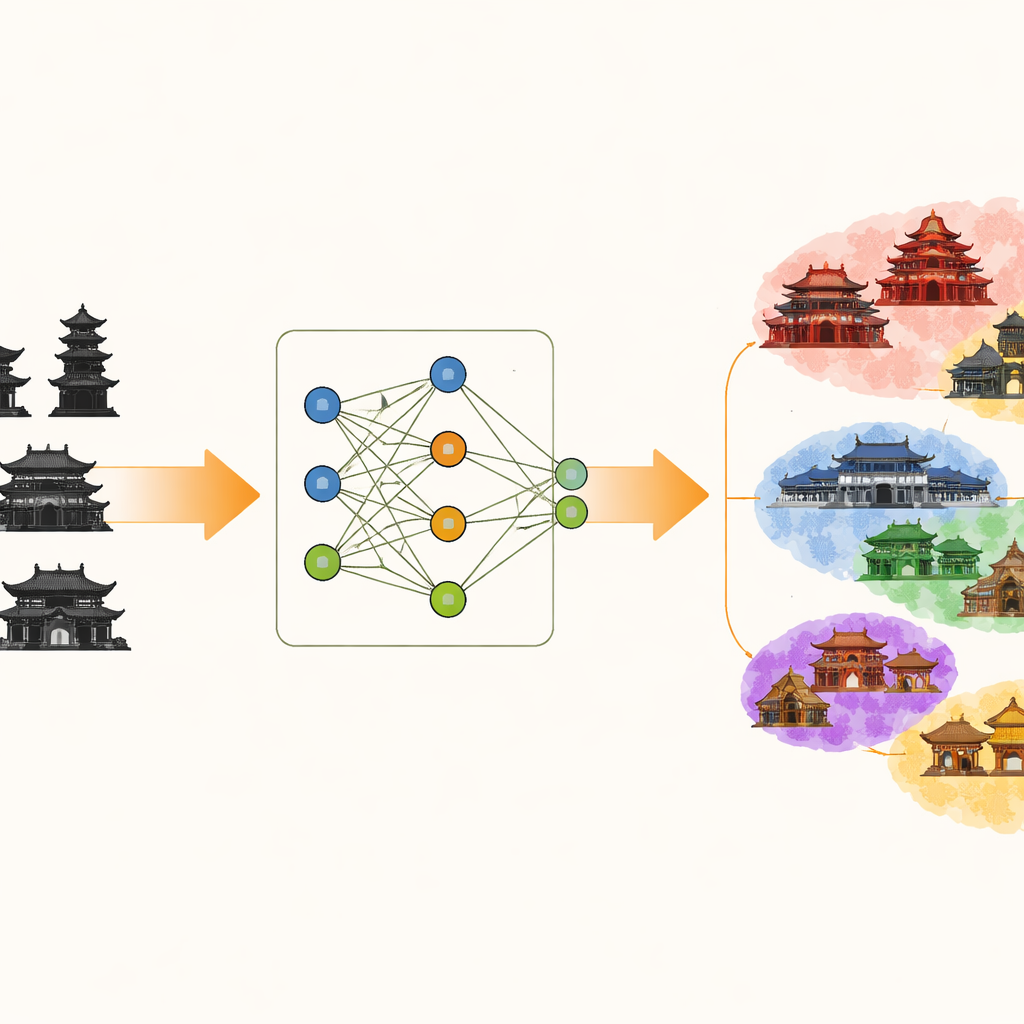
Qué hace que estos edificios sean difíciles de distinguir
La arquitectura china antigua está llena de patrones repetitivos: líneas de techo curvas, conjuntos de ménsulas estratificadas bajo los aleros, vigas talladas y decoración superficial colorida. Muchos edificios comparten disposiciones similares, que solo difieren en sutiles variaciones en la curvatura del tejado o la forma de las ménsulas. Los sistemas estándar de reconocimiento de imágenes, que aprenden ajustando gradualmente pesos internos, pueden verse confundidos por estas diferencias de detalle y por señales distractoras como el color de las paredes o la iluminación. También tienden a sobreajustarse a una región o estilo cuando se entrenan a la vez con un gran lote de imágenes, reduciendo su capacidad de generalizar a edificios de otros lugares.
Una forma más inteligente de fijarse en los detalles clave
Los autores presentan un marco llamado clasificación de imágenes de arquitectura antigua con aprendizaje por pseudoinversa y apilamiento progresivo (AAPSP). En su núcleo está un módulo denominado aprendizaje por pseudoinversa con apilamiento de características clave (KFSP). En lugar de comenzar desde configuraciones completamente aleatorias, KFSP construye varios “aprendices base” paralelos, cada uno inicializado con patrones de peso diseñados para captar rasgos visuales determinados. Dos ramas se ajustan para ser especialmente sensibles a estructuras suaves y continuas, como los contornos de los tejados, mientras que una tercera se orienta a captar texturas más dispersas, como motivos decorativos. Un atajo matemático conocido como aprendizaje por pseudoinversa permite entrenar estas ramas prácticamente de una sola vez, evitando las lentas actualizaciones paso a paso de los pesos propias del aprendizaje profundo tradicional.
Permitir que el modelo atienda donde importa
Tener múltiples ramas no es suficiente; el sistema también debe decidir qué rama es la más útil para cada decisión. Para ello, KFSP emplea un mecanismo de atención que mide cuán estrechamente la salida de cada rama coincide con las etiquetas reales de los edificios. Las ramas que capturan mejor los elementos distintivos —como la forma de un arco de cubeta o el contorno de un adorno de cumbrera— reciben automáticamente más peso cuando se combinan sus salidas. Esta representación apilada constituye un espacio de características que sigue más de cerca la “lógica de la forma” subyacente en la arquitectura antigua, de modo que los edificios con componentes estructurales similares se agrupan entre sí y los de estilos distintos se separan con mayor claridad.
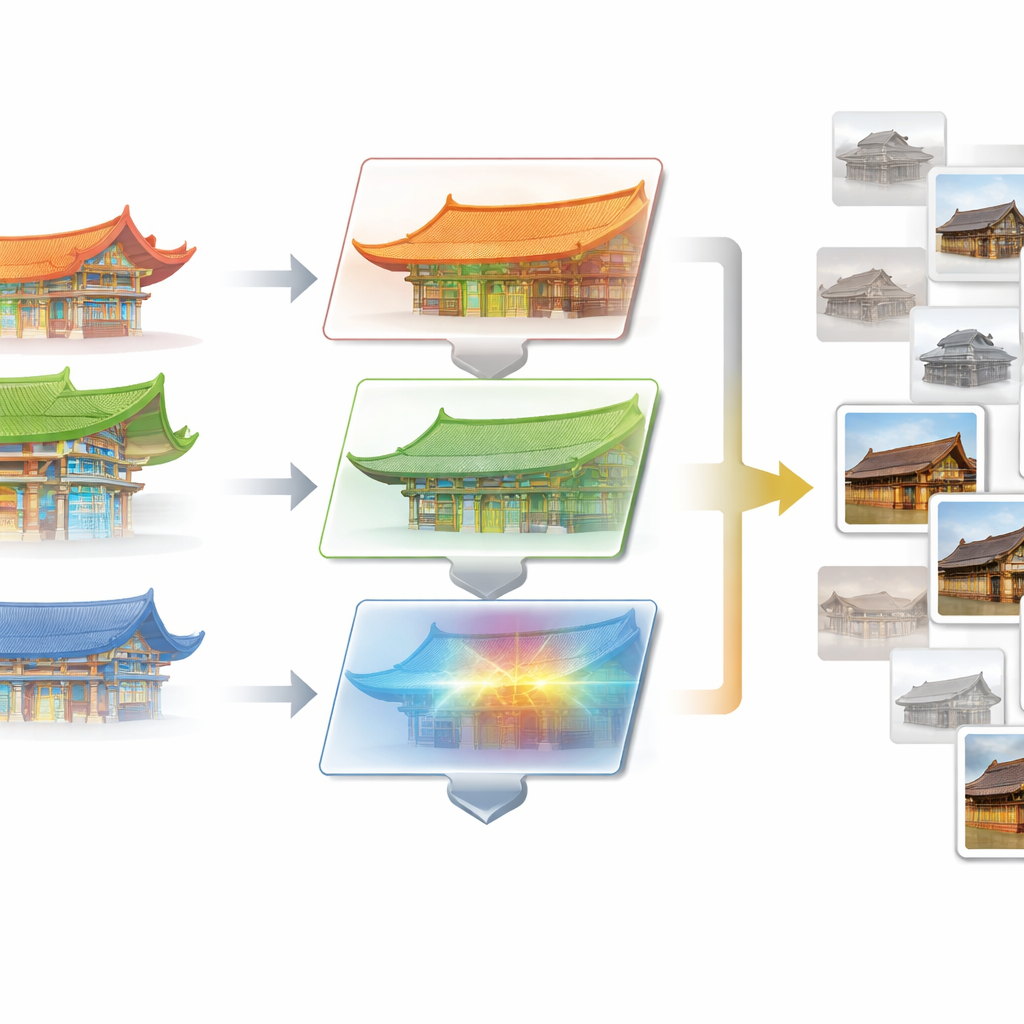
Aprender a partir de las fotos más informativas
El segundo módulo central, aprendizaje de optimización progresiva (POL), aborda un problema distinto: imágenes de entrenamiento redundantes. Muchas fotos del conjunto muestran vistas casi idénticas de la misma fachada y aportan poca información nueva. POL comienza dividiendo los datos en un conjunto de entrenamiento inicial y una pool de candidatos más grande. Utilizando ideas del aprendizaje activo, analiza con qué confianza el modelo actual clasifica cada imagen candidata y cuán inusuales resultan sus características. Las fotos que son a la vez inciertas y distintivas —como arreglos raros de ménsulas o combinaciones de tejado poco comunes— se van incorporando gradualmente al conjunto de entrenamiento. Este ciclo se repite, enriqueciendo de forma sostenida los datos de entrenamiento con ejemplos desafiantes y diversos sin aumentar el número total de imágenes usadas.
Qué tan bien funciona en la práctica
Los autores probaron su enfoque en una colección pública de 2.269 imágenes de seis templos y palacios famosos. Tras aplicar solo KFSP, el sistema ya superó a un método comparable que se basaba en proyecciones completamente aleatorias. Cuando se añadió la selección progresiva de muestras de POL, la precisión de la clasificación mejoró aún más, y también aumentaron las medidas de precisión, recall y F1. En otras palabras, el modelo se volvió tanto más fiable en sus aciertos como mejor en detectar categorías menos comunes. El estudio también puso de manifiesto una dificultad restante: las clases con muy pocas imágenes siguen siendo un reto, porque incluso un aprendiz inteligente tiene problemas cuando hay muy poca variedad de la que aprender.
Por qué esto importa para el patrimonio cultural
Al dirigir con cuidado tanto aquello a lo que el modelo presta atención como qué imágenes aprende, AAPSP ofrece una herramienta más precisa para ordenar y estudiar fotos de edificios históricos. Para los profesionales del patrimonio, esto significa crear archivos digitales más rápidos, mejor apoyo para datar y comparar estilos arquitectónicos y un seguimiento más robusto de bienes repartidos por distintas regiones. Aunque el método está diseñado para la arquitectura china antigua, sus ideas centrales —resaltar detalles estructurales clave y centrarse progresivamente en ejemplos raros pero informativos— podrían adaptarse a otros tipos de objetos culturales, desde esculturas hasta paisajes urbanos históricos.
Cita: Cai, Z., Sun, X., Zhang, S. et al. Ancient architecture image classification with progressive stacking pseudoinverse learning. Sci Rep 16, 14626 (2026). https://doi.org/10.1038/s41598-026-44876-9
Palabras clave: arquitectura antigua, clasificación de imágenes, patrimonio cultural, aprendizaje automático, aprendizaje activo