Clear Sky Science · zh
用于工业物联网(IIoT)系统预测性维护的自适应机器学习模型
在机器故障前实现更聪明的修复
现代工厂充斥着不断每秒传输数据的联网设备。在这些数据流中隐含着某些即将出问题的早期信号。本文探讨了一类更新的“自适应”人工智能如何像经验丰富的技师而非僵化的检查清单那样读取这些信号,帮助行业在问题演变成昂贵的故障和停机之前加以修复。
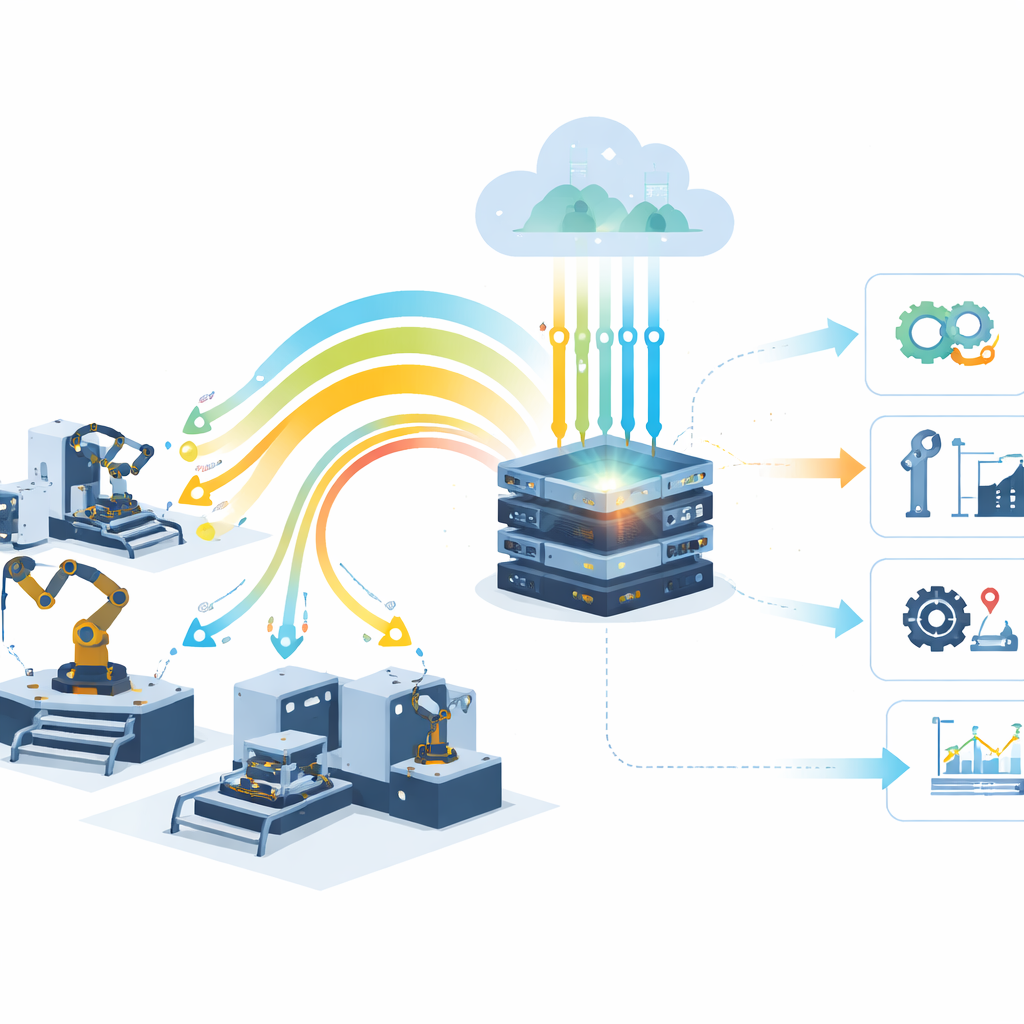
从定期检修走向数据驱动的保养
传统维护常像汽车的固定保养计划:在设定的工时后检查或更换部件,无论是否真正需要。即使工厂采用了机器学习,许多模型也是训练一次后就不再更新,尽管机器在老化、负载变化且传感器可能发生漂移。作者认为这种“静止不变”的方法与不断变化的工业环境不相匹配。因此他们关注于能够持续从新数据中学习并可在运行时切换到当前表现最佳模型的自适应模型。
自适应模型如何在工作中学习
该研究设计了一个完整的预测性维护流水线,模拟真实的工业物联网(IIoT)部署。发动机和轴承上的传感器记录振动、温度、压力和转速,数据来自知名的NASA和PRONOSTIA数据集。由于原始信号嘈杂且混乱,系统首先对其平滑、去除异常峰值,并通过统计摘要和降维将大量传感器读数压缩为少量信息性特征。清洗后的数据随后流入一组机器学习模型池,这些模型随着新信息的到来在线更新。“动态模型选择”策略对它们在滑动时间窗口内的近期表现进行持续监控,并自动部署当前预测最可靠的模型。
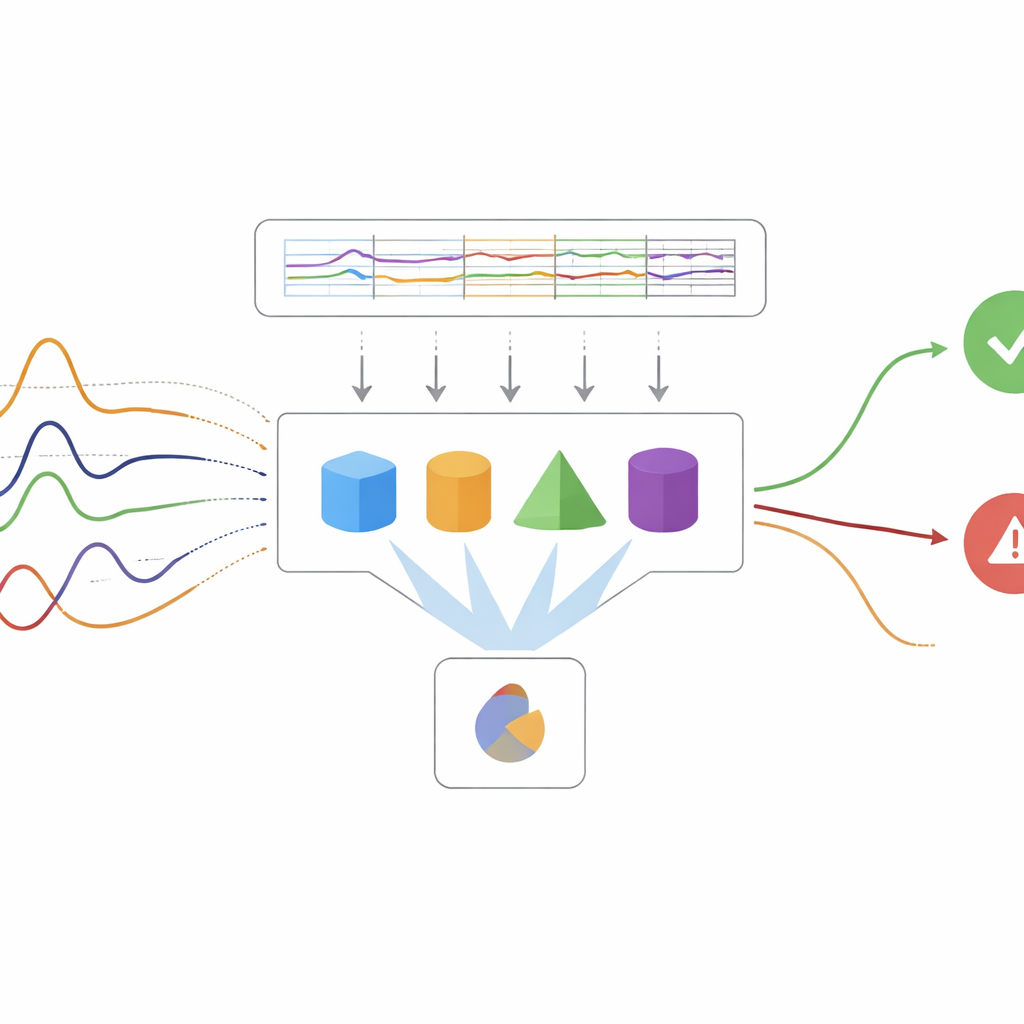
监测漂移与罕见故障
真实工厂面临的一个关键挑战是数据本身随时间改变。机器会磨损,操作人员会调整流程,新的故障类型也会出现。作者通过专门的检测器来监控性能下降,以应对这种“概念漂移”。当检测到漂移时,系统只对需要更新的模型部分进行再训练或调整,而不是从头重建全部模型。为处理罕见但关键的故障,研究强调召回率和F1分数等指标,这些指标侧重于在不过度产生误报的前提下捕获故障。研究将提升方法、增量决策树和自适应梯度方法等技术组合成一个“自适应集成”,兼顾模型多样性和持续调整的优势。
显著提升准确率并减少漏检
研究者将自适应模型与支持向量机、随机森林等标准非自适应方法进行了比较。在多次测试运行和严格统计检验下,自适应方法始终占优。最佳配置——自适应集成——达到约93%的准确率,并具有很强的区分健康与故障状态的能力。与传统模型相比,它将召回率提高了约11个百分点、精确率提高了约10个百分点,这意味着它既减少了真实故障的漏检,也降低了误报。对假阳性和假阴性的分析表明,自适应系统可将不必要的维护和未被发现的故障减少数十个百分点,估算可带来约38%–60%的维护成本降低。
这对未来工厂意味着什么
对非专业读者来说,核心信息很直接:与依赖僵化规则或一次性AI模型不同,工厂可以部署随着机器和条件变化持续学习的预测系统。通过结合实时传感器数据、快速的边缘计算和基于云的分析,自适应方法能更早更可靠地发现问题,同时保持日常工业使用所需的速度。实际上,这意味着更少的意外故障、更少的浪费性维护以及昂贵设备更高的运行时间。随着这些自适应技术成熟并更深度地整合到IIoT平台中,它们有望成为更智能、更具弹性的工业操作的基石。
引用: Subashree, S., Rajakumaran, M., Pushpa, G. et al. Adaptive machine learning models for predictive maintenance in industrial internet of things (IIoT) systems. Sci Rep 16, 12451 (2026). https://doi.org/10.1038/s41598-026-42666-x
关键词: 预测性维护, 工业物联网, 自适应机器学习, 故障检测, 边缘与云计算