Clear Sky Science · nl
Aanpasbare machine learning-modellen voor voorspellend onderhoud in industriële internet-of-things (IIoT)-systemen
Slimmere reparaties voordat machines falen
Moderne fabrieken zitten vol verbonden machines die elke seconde stilletjes data streamen. Verborgen in die stromen zitten vroege aanwijzingen dat er iets mis zal gaan. Dit artikel onderzoekt hoe een nieuwere generatie “aanpasbare” kunstmatige intelligentie die signalen meer kan lezen als een ervaren monteur dan als een starre checklist, en zo industrieën helpt problemen te verhelpen voordat ze in kostbare storingen en stilleggingen uitmonden.
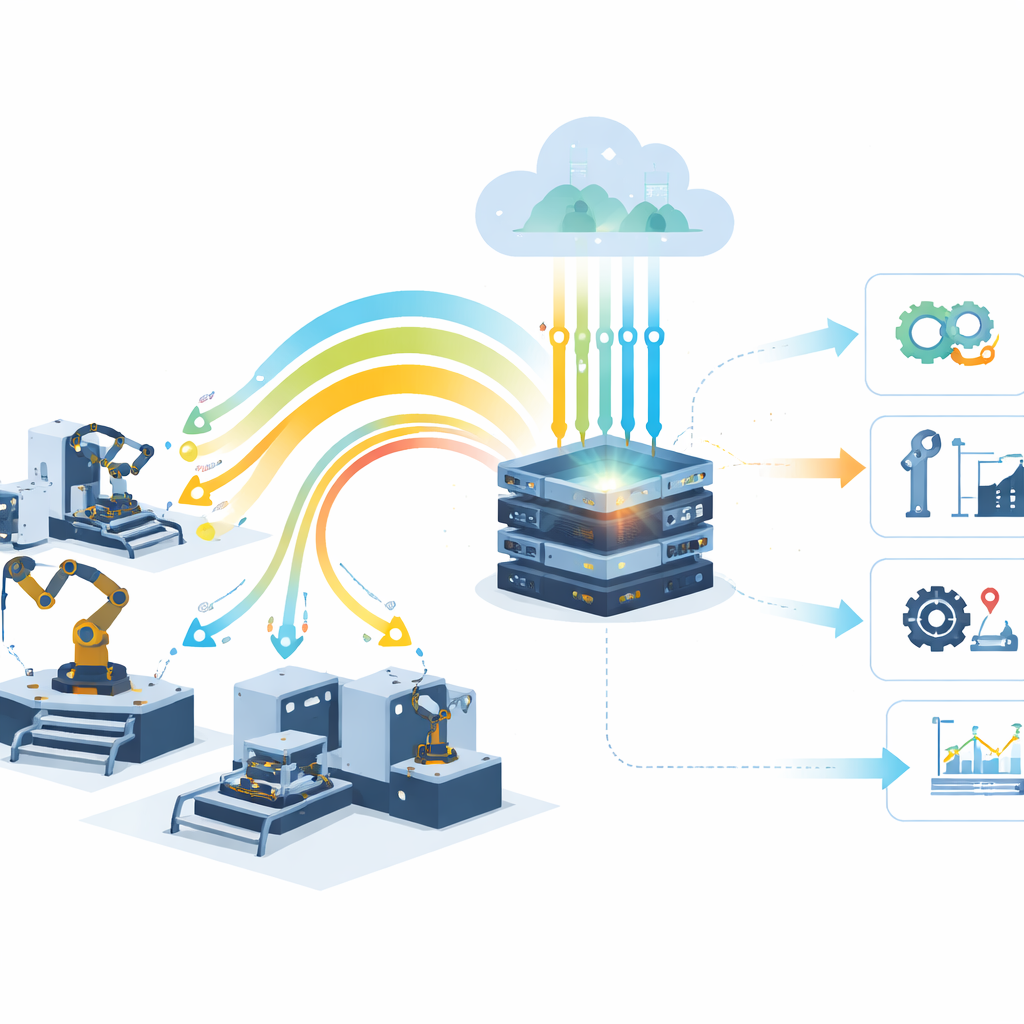
Van geplande controles naar datagedreven zorg
Traditioneel onderhoud werkt vaak als het vaste onderhoudsschema van een auto: onderdelen controleren of vervangen na een vast aantal draaiuren, of ze het nu nodig hebben of niet. Zelfs wanneer fabrieken machine learning gebruiken, worden veel modellen eenmaal getraind en daarna onaangeroerd achtergelaten, terwijl machines verouderen, werkbelastingen verschuiven en sensoren uit kalibratie raken. De auteurs stellen dat deze “bevroren in de tijd” aanpak slecht past bij industriële omgevingen, waar omstandigheden voortdurend veranderen. Zij richten zich in plaats daarvan op aanpasbare modellen die blijven leren van nieuwe data en kunnen schakelen naar het model dat op dat moment het beste presteert.
Hoe aanpasbare modellen on the job leren
De studie ontwerpt een volledige voorspellend-onderhoudspijplijn die een echte Industrial Internet of Things (IIoT)-opstelling imiteert. Sensoren op motoren en lagers registreren trillingen, temperatuur, druk en snelheid, met gegevens uit bekende NASA- en PRONOSTIA-datasets. Omdat ruwe signalen lawaaierig en rommelig zijn, effent het systeem ze eerst, verwijdert vreemde pieken en comprimeert veel sensorlezingen tot een kleinere set informatieve kenmerken met behulp van statistische samenvattingen en dimensionaliteitsreductie. De schoongemaakte data stroomt vervolgens naar een pool van machine learning-modellen die online worden bijgewerkt zodra nieuwe informatie binnenkomt. Een “dynamische modelselectie”-strategie bewaakt continu hun recente prestaties over schuivende tijdvensters en zet automatisch het model in dat op dat moment de meest betrouwbare voorspellingen doet.
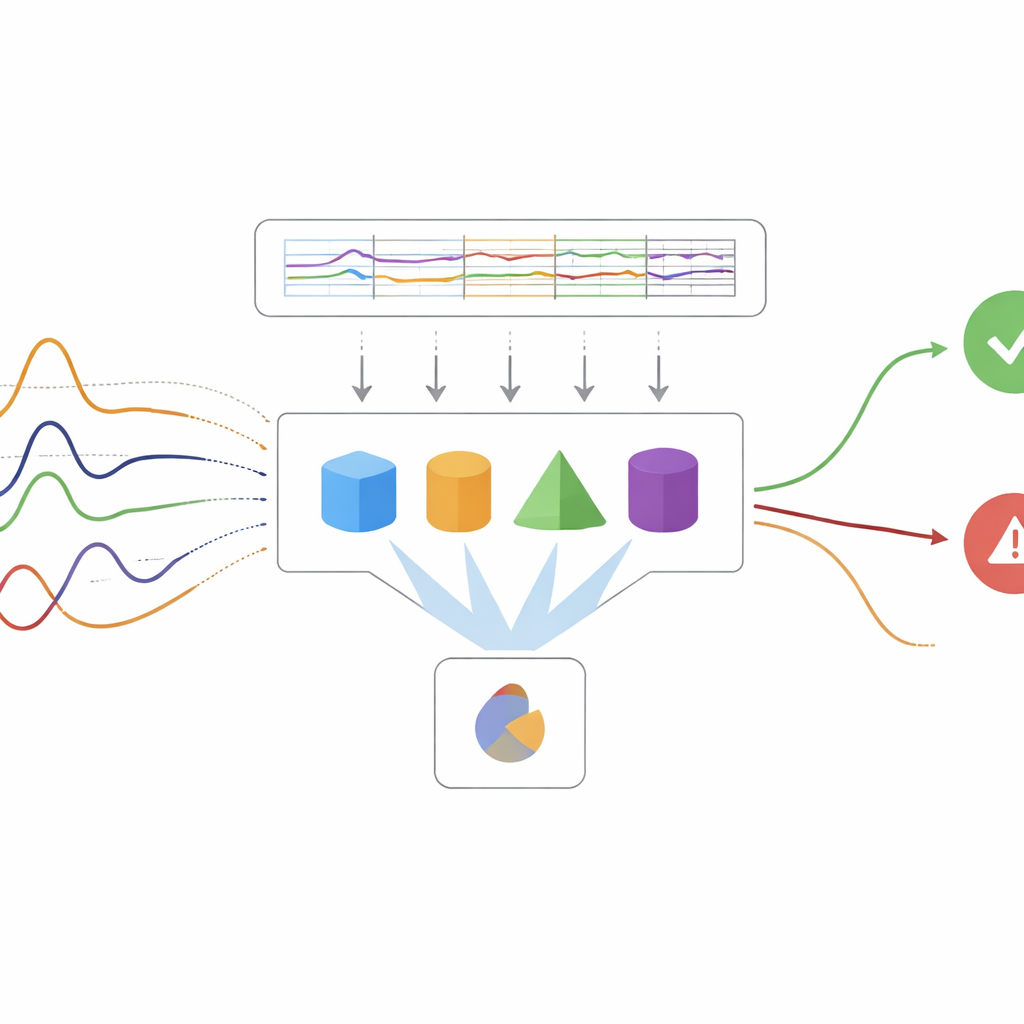
Letten op drift en zeldzame problemen
Een belangrijke uitdaging in echte fabrieken is dat de data zelf in de loop van de tijd verandert. Machines slijten, operators passen processen aan en nieuwe fouttypes verschijnen. De auteurs pakken deze “concept drift” aan met speciale detectoren die letten op prestatieverlies. Wanneer drift wordt gedetecteerd, traint het systeem alleen de onderdelen van het model opnieuw of past die aan die bijgewerkt moeten worden, in plaats van alles van de grond af opnieuw op te bouwen. Om zeldzame maar kritieke storingen te behandelen, benadrukt de studie maatstaven zoals recall en F1-score, die gericht zijn op het oppakken van fouten zonder het personeel te overstelpen met valse alarmen. Technieken zoals boosting, incrementele beslisbomen en adaptieve gradientmethoden worden gecombineerd in een “Adaptive Ensemble” dat profiteert van zowel variëteit als voortdurende aanpassing.
Grote winst in nauwkeurigheid en minder gemiste fouten
De onderzoekers vergelijken aanpasbare modellen met standaard, niet-aanpasbare benaderingen zoals support vector machines en random forests. Over meerdere testruns en strikte statistische controles komen adaptieve methoden consequent als winnaar uit de bus. De beste configuratie, het Adaptive Ensemble, bereikt ongeveer 93% nauwkeurigheid en een zeer sterke capaciteit om gezonde van falende toestanden te onderscheiden. Vergeleken met traditionele modellen verbetert het de recall met tot ongeveer 11 procentpunten en de precisie met ongeveer 10 punten, wat betekent dat het zowel minder echte fouten mist als minder valse alarmen afgeeft. Analyses van false positives en false negatives tonen aan dat het adaptieve systeem onnodig onderhoud en onopgemerkte storingen met tientallen procenten kan terugdringen, wat zich vertaalt in geraamde onderhoudskostenbesparingen van ongeveer 38–60%.
Wat dit betekent voor toekomstige fabrieken
Voor niet-specialisten is de kernboodschap helder: in plaats van te vertrouwen op starre regels of eenmalige AI-modellen, kunnen fabrieken voorspellende systemen inzetten die blijven leren naarmate machines en omstandigheden veranderen. Door realtime sensordata, snelle edgecomputing en cloudgebaseerde analyse te combineren, signaleert de adaptieve benadering problemen eerder en betrouwbaarder, terwijl ze snel genoeg blijft voor dagelijks industrieel gebruik. In de praktijk betekent dat minder onverwachte storingen, minder verspild onderhoud en meer uptime van dure apparatuur. Naarmate deze adaptieve technieken rijpen en dieper in IIoT-platforms worden geïntegreerd, zouden ze een hoeksteen kunnen worden van slimmer en weerbaarder industrieel handelen.
Bronvermelding: Subashree, S., Rajakumaran, M., Pushpa, G. et al. Adaptive machine learning models for predictive maintenance in industrial internet of things (IIoT) systems. Sci Rep 16, 12451 (2026). https://doi.org/10.1038/s41598-026-42666-x
Trefwoorden: voorspellend onderhoud, industrieel internet der dingen, aanpasbare machine learning, foutdetectie, edge- en cloudcomputing