Clear Sky Science · fr
Modèles d’apprentissage automatique adaptatifs pour la maintenance prédictive dans les systèmes d’internet industriel des objets (IIoT)
Des réparations plus intelligentes avant la panne des machines
Les usines modernes regorgent de machines connectées qui diffusent silencieusement des données chaque seconde. Dans ces flux se cachent des signaux précoces indiquant qu’un problème est sur le point d’apparaître. Cet article explore comment une nouvelle génération d’intelligence artificielle « adaptative » peut lire ces signaux davantage comme un mécanicien expérimenté que comme une liste rigide, aidant les industriels à résoudre les problèmes avant qu’ils ne dégénèrent en pannes coûteuses et en arrêts de production.
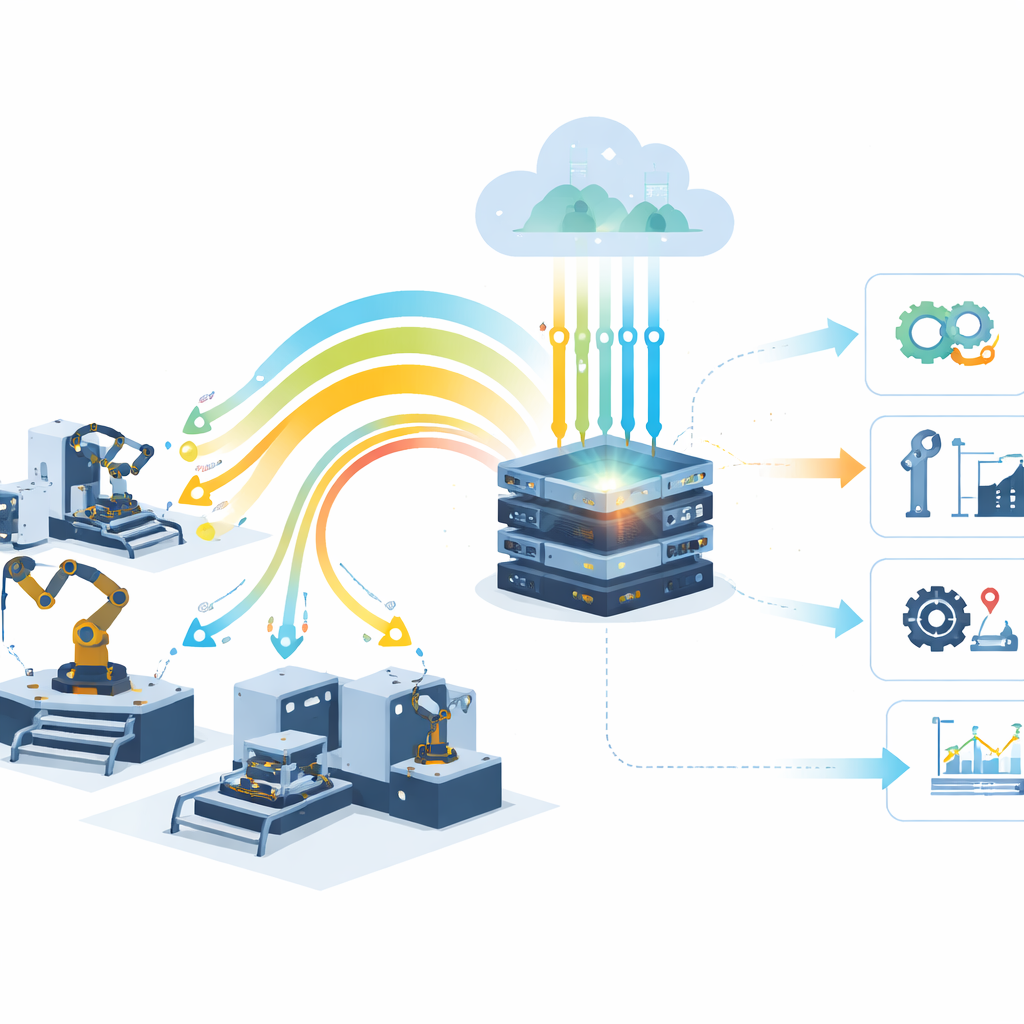
Des contrôles programmés aux soins pilotés par les données
La maintenance traditionnelle fonctionne souvent comme l’entretien périodique d’une voiture : vérifier ou remplacer des pièces après un certain nombre d’heures, qu’elles en aient besoin ou non. Même lorsque les usines utilisent l’apprentissage automatique, de nombreux modèles sont entraînés une fois puis laissés inchangés, alors que les machines vieillissent, les charges de travail évoluent et les capteurs se dérèglent. Les auteurs soutiennent que cette approche « figée dans le temps » est mal adaptée aux environnements industriels, où les conditions changent en permanence. Ils privilégient des modèles adaptatifs qui continuent d’apprendre à partir des nouvelles données et peuvent basculer vers le modèle qui offre actuellement les meilleures performances.
Comment les modèles adaptatifs apprennent en conditions réelles
L’étude conçoit une pipeline complète de maintenance prédictive qui imite un véritable dispositif IIoT industriel. Des capteurs sur moteurs et roulements enregistrent vibrations, température, pression et vitesse, issus de jeux de données bien connus comme ceux de la NASA et de PRONOSTIA. Parce que les signaux bruts sont bruyants et désordonnés, le système les lisse d’abord, supprime les pics anormaux et compresse de nombreuses mesures en un ensemble réduit de caractéristiques informatives via des résumés statistiques et une réduction de dimension. Les données nettoyées alimentent ensuite un pool de modèles d’apprentissage automatique mis à jour en ligne à mesure que de nouvelles informations arrivent. Une stratégie de « sélection dynamique de modèle » surveille en continu leurs performances récentes sur des fenêtres temporelles glissantes et déploie automatiquement le modèle qui fournit actuellement les prédictions les plus fiables.
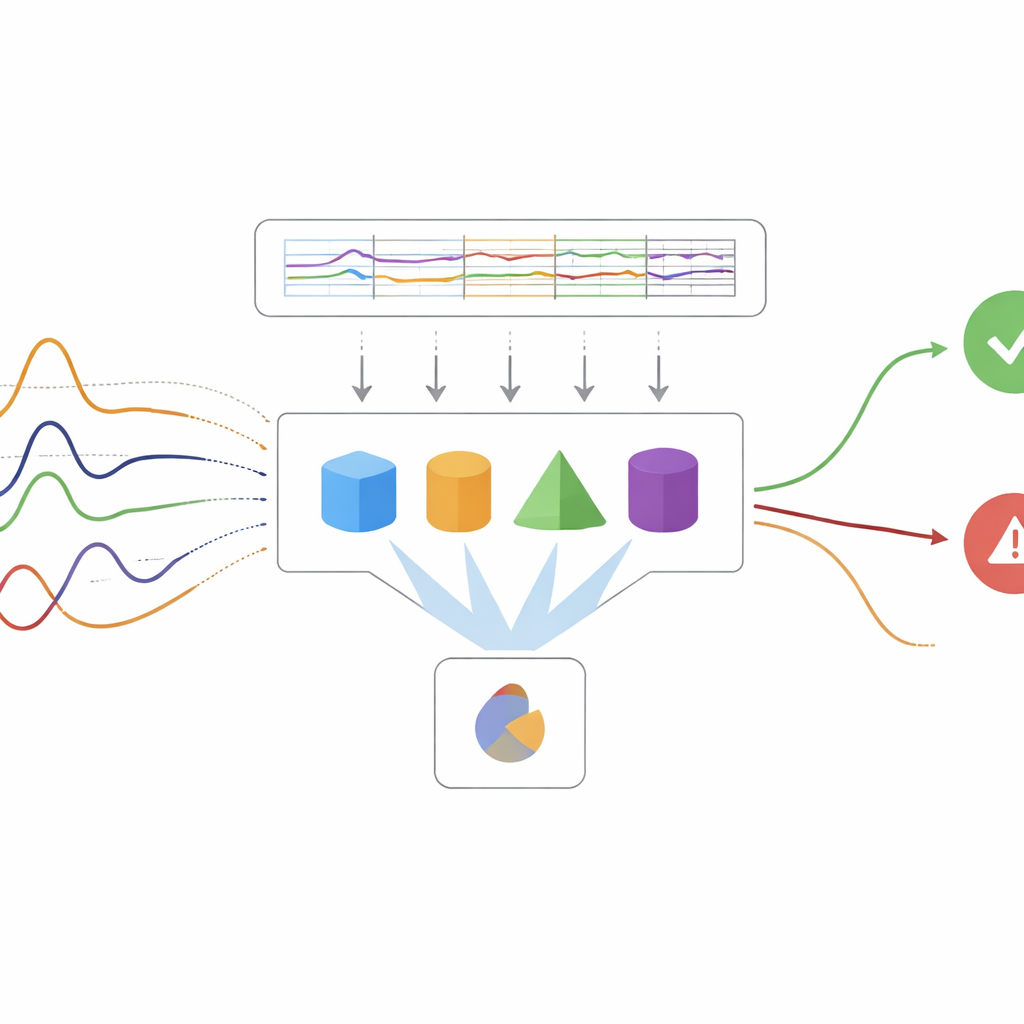
Surveiller les dérives et les problèmes rares
Un défi majeur dans les usines réelles est que les données elles‑mêmes évoluent dans le temps. Les machines s’usent, les opérateurs ajustent les processus et de nouveaux types de défauts apparaissent. Les auteurs traitent cette « dérive de concept » avec des détecteurs dédiés qui surveillent les baisses de performance. Lorsqu’une dérive est détectée, le système réentraîne ou ajuste uniquement les parties du modèle nécessitant une mise à jour, au lieu de tout reconstruire. Pour gérer des défaillances rares mais critiques, l’étude met l’accent sur des mesures comme le rappel et le score F1, qui visent à détecter les défauts sans submerger le personnel de fausses alertes. Des techniques telles que le boosting, les arbres de décision incrémentaux et les méthodes de gradient adaptatif sont combinées dans un « Ensemble Adaptatif » tirant parti à la fois de la diversité et de l’ajustement continu.
Gains importants de précision et moins de défauts manqués
Les chercheurs comparent les modèles adaptatifs aux approches standard non adaptatives comme les machines à vecteurs de support et les forêts aléatoires. Sur plusieurs séries de tests et des contrôles statistiques stricts, les méthodes adaptatives arrivent systématiquement en tête. La meilleure configuration, l’Ensemble Adaptatif, atteint environ 93 % de précision et une forte capacité à distinguer états sains et états défaillants. Par rapport aux modèles traditionnels, il améliore le rappel d’environ 11 points de pourcentage et la précision d’environ 10 points, ce qui signifie qu’il manque moins de défauts réels et émet moins de fausses alertes. Les analyses des faux positifs et faux négatifs montrent que le système adaptatif peut réduire les maintenances inutiles et les défaillances non détectées de plusieurs dizaines de pour cent, se traduisant par des réductions estimées des coûts de maintenance de l’ordre de 38 à 60 %.
Ce que cela signifie pour les usines de demain
Pour les non‑spécialistes, le message principal est simple : au lieu de s’en remettre à des règles rigides ou à des modèles d’IA ponctuels, les usines peuvent déployer des systèmes prédictifs qui continuent d’apprendre à mesure que les machines et les conditions évoluent. En combinant données capteurs en temps réel, calcul en périphérie (edge) réactif et analyse dans le cloud, l’approche adaptative repère les problèmes plus tôt et de façon plus fiable, tout en restant suffisamment rapide pour l’usage industriel quotidien. En pratique, cela se traduit par moins de pannes surprises, moins de maintenances gaspillées et davantage de disponibilité des équipements coûteux. À mesure que ces techniques adaptatives mûrissent et sont intégrées plus profondément aux plateformes IIoT, elles pourraient devenir une pierre angulaire d’opérations industrielles plus intelligentes et résilientes.
Citation: Subashree, S., Rajakumaran, M., Pushpa, G. et al. Adaptive machine learning models for predictive maintenance in industrial internet of things (IIoT) systems. Sci Rep 16, 12451 (2026). https://doi.org/10.1038/s41598-026-42666-x
Mots-clés: maintenance prédictive, internet industriel des objets, apprentissage automatique adaptatif, détection de défauts, edge et cloud computing