Clear Sky Science · zh
具有差异化策略整合的双层图注意力范式用于异质多智能体强化学习
为什么许多人工智能需要学会协作
从机器人团队和自动驾驶汽车,到无人机群和策略游戏中的虚拟玩家,许多现代系统依赖大量人工智能代理共同工作。然而,让这些数字队友协调一致比看起来要困难,尤其是当每个代理具有不同能力且只能部分观测环境时。本文提出了一种组织此类团队的新方法,使它们能够共享恰到好处的信息、做出更好的集体决策,并比以往更好地扩展到更大、更复杂的任务。
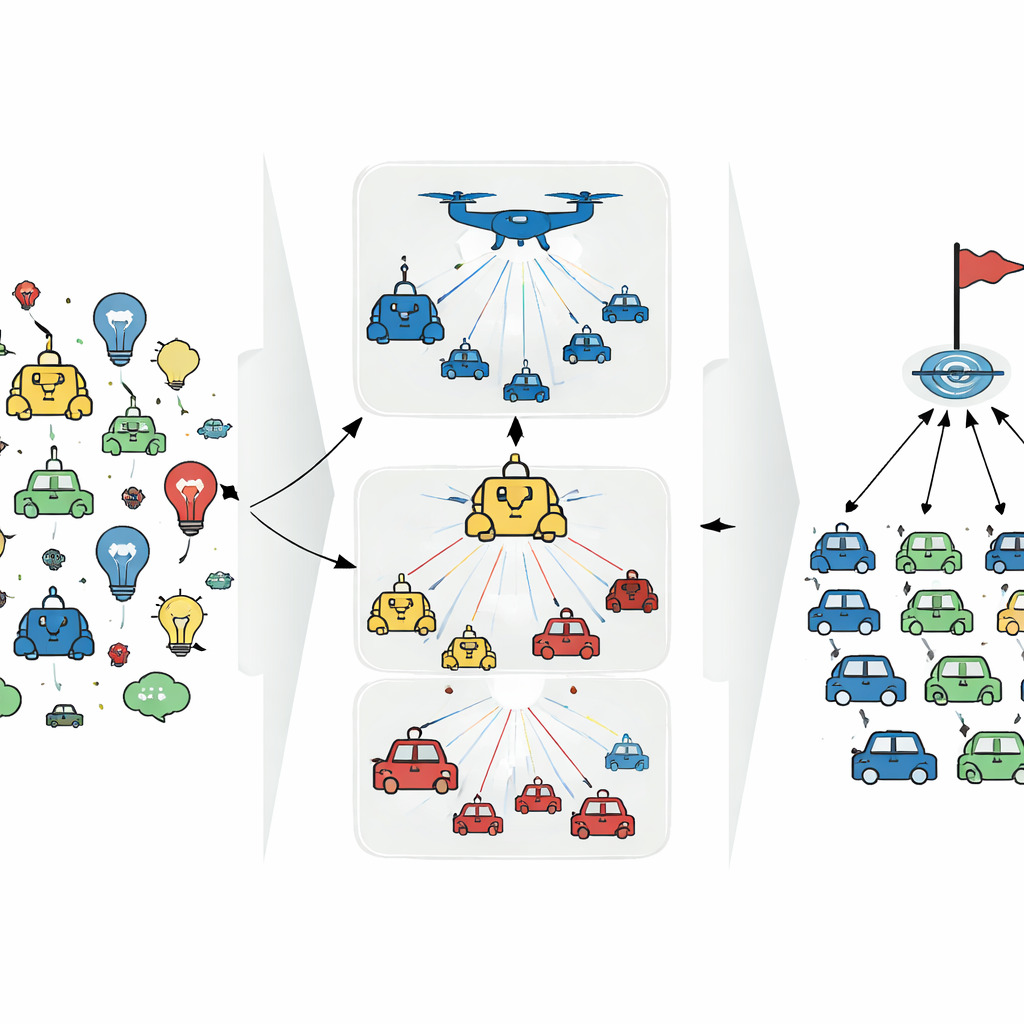
分组、引导与日常协作
作者以一个简单的想法为出发点,这一想法反映了人类和动物的协作方式:将团队划分为角色与小组。在一个办公室项目中,市场、工程和财务的成员各自带来不同技能,每个小组由一位经理协调本地决策并与其他经理沟通。受此启发,所提出的方法称为双层图注意力范式(Bi-GAP),它按类型将人工代理聚类。在每个组内,若干“成员”代理在环境中实际采取行动,而一个虚拟的“引导”代理则收集更广泛的视角并提供战略方向,但不直接执行动作。
组内与组间的智能交流
Bi-GAP 的核心创新在于这些代理之间的通信方式。与其让每个代理与所有其他代理通信——这会随着团队规模增长而迅速不堪负荷——该方法在图上实施了两层注意力机制。在第一层,同类型的成员代理选择性地共享信息,聚焦于与当前情境最相关的队友。该组的引导代理监听所有成员,权衡它们的输入以形成信息浓缩摘要。在第二层,只有来自不同组的引导代理彼此交流,同样使用注意力机制聚焦最重要的伙伴。这个两步结构减少了信息过载,过滤噪声,并使整体系统对缺失或误导信息更有鲁棒性。

将大局建议与局部直觉融合
良好的协作不仅需要通信,还需要将不同视角融为单一决策的方式。Bi-GAP 通过为每个执行动作的代理提供两类指导来应对这一点:其自身的局部推理以及由引导代理生成的建议。该方法并非始终将两者视为等重,而是对两种策略进行比较。当它们大体一致时,成员代理更依赖自身的细粒度视角,从而保留快速的局部反应;当两者分歧显著时,则更重视引导代理的广阔视角,引导代理促使成员朝更符合整体计划的行动方向调整。这种自适应融合有助于在快速的局部反应与稳定的团队级协调之间取得平衡。
在虚拟战斗与追逃游戏中的测试
为了验证 Bi-GAP 是否带来实际优势,研究者在两个具有挑战性的测试环境中进行了评估。第一个是在即时战略游戏星际争霸 II 基础上构建的战斗模拟器,混合编队的单位必须协调移动与攻击以对抗强大的内置对手。第二个是捕食者—猎物环境,速度快慢不同且具备不同能力的代理在连续运动中相互追赶或躲避。在两种设置中,并在全可见与部分可见条件下,将该方法与若干领先的多智能体强化学习技术进行了比较。Bi-GAP 不仅取得了更高的胜率与奖励,还更快学会有效行为,并且随着代理数量和多样性增加仍保持稳定。
这对未来人工智能团队意味着什么
简而言之,这项研究表明,给予大型异质智能体团队一个轻量但结构良好的层次可以显著提升协作表现。通过按相似性分组、让引导代理在组间协调、以及将全局建议与局部判断融合,Bi-GAP 比那些过于集中或过于分散的早期方法更高效地处理复杂任务。随着多智能体系统在机器人、交通控制、虚拟游戏和其他现实应用中越来越常见,此类通信与决策机制有助于确保不断增长的数字群体更像训练有素的团队,而不是混乱的人群。
引用: Li, Y., Zhang, Z. & Wang, J. Bi-level graph attention paradigm with differential strategy integration for heterogeneous multi-agent reinforcement learning. Sci Rep 16, 12156 (2026). https://doi.org/10.1038/s41598-026-41722-w
关键词: 多智能体强化学习, 异质智能体, 图注意力, 协同, 分层控制