Clear Sky Science · nl
Bi-level graf-attentieparadigma met differentiële strategie-integratie voor heterogene multi-agent reinforcement learning
Waarom veel AIs moeten leren samenwerken
Van robotteams en zelfrijdende auto’s tot zwermen drones en virtuele spelers in strategiespellen: veel moderne systemen vertrouwen op grote aantallen kunstmatige agenten die samenwerken. Maar deze digitale teamgenoten laten coördineren is lastiger dan het klinkt, vooral wanneer iedere agent andere vaardigheden heeft en slechts een gedeeltelijk beeld van de situatie. Dit artikel introduceert een nieuwe manier om zulke teams te organiseren zodat ze precies de juiste informatie delen, betere groepsbeslissingen nemen en opschalen naar veel grotere en meer gevarieerde problemen dan voorheen.
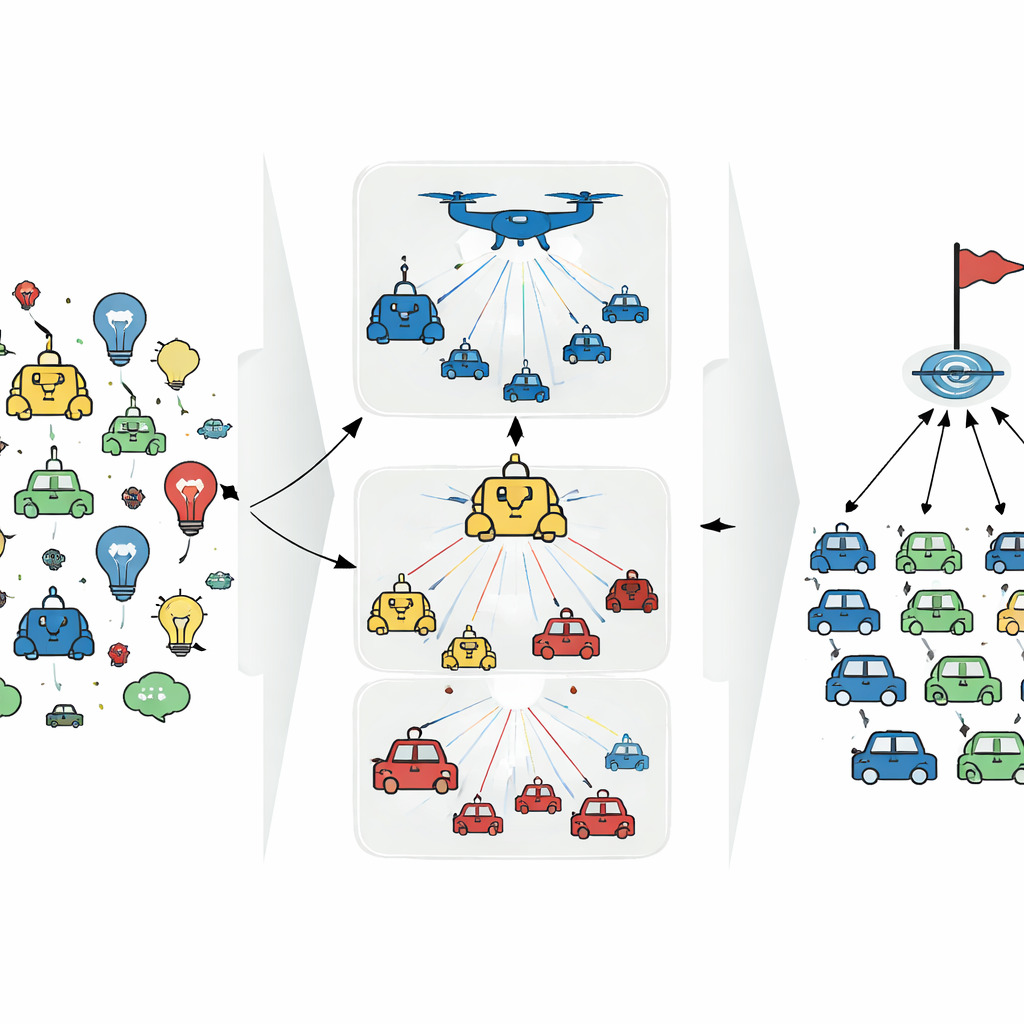
Groepen, gidsen en alledaagse samenwerking
De auteurs vertrekken van een eenvoudig idee dat weerspiegelt hoe mensen en dieren samenwerken: verdeel het team in rollen en groepen. In een kantoorsituatie brengen leden van marketing, engineering en financiën elk hun eigen vaardigheden in, en een manager binnen elke groep coördineert lokale keuzes terwijl hij met andere managers communiceert. Geïnspireerd door dit principe clustert de voorgestelde methode, genaamd Bi-level Graph Attention Paradigm (Bi-GAP), kunstmatige agenten op type. Binnen elke groep voeren meerdere "lid"-agenten daadwerkelijk acties uit in de omgeving, terwijl een virtuele "gids"-agent een breder overzicht verzamelt en strategische richting biedt zonder zelf direct acties te ondernemen.
Slimme gesprekken binnen en tussen groepen
De kerninnovatie van Bi-GAP zit in hoe deze agenten communiceren. In plaats van elke agent met elke andere te laten praten — wat snel onhoudbaar wordt naarmate het team groeit — gebruikt de methode een tweelaags aandachtmechanisme, geïmplementeerd op een graaf. In de eerste laag delen lid-agenten van hetzelfde type selectief informatie en richten ze zich op de teamgenoten die het meest relevant zijn voor hun huidige situatie. De gids-agent van die groep luistert naar al zijn leden en weegt hun input om een weloverwogen samenvatting te vormen. In de tweede laag communiceren alleen de gids-agents van verschillende groepen met elkaar, opnieuw gebruikmakend van attentie om zich te concentreren op de belangrijkste partners. Deze twee-stapsstructuur vermindert berichtenoverload, filtert ruis en maakt het systeem robuuster tegen ontbrekende of misleidende informatie.

Het mengen van grootbeeldadvies met lokale instincten
Goede coördinatie vereist meer dan communicatie; het vereist ook een manier om verschillende gezichtspunten tot één beslissing te smelten. Bi-GAP pakt dit aan door elke handelende agent twee bronnen van sturing te geven: het eigen lokale redeneren en het advies dat door zijn gids-agent wordt gegenereerd. In plaats van deze altijd gelijk te behandelen, vergelijkt de methode de twee voorgestelde strategieën. Wanneer ze grotendeels overeenkomen, vertrouwt de lid-agent meer op zijn eigen gedetailleerde kijk en behoudt zo fijnmazige reacties. Wanneer ze sterk uiteenlopen, krijgt het bredere perspectief van de gids zwaarder gewicht, waardoor de agent in de richting van een actie wordt geduwd die beter past bij het groepsbrede plan. Deze adaptieve menging helpt het evenwicht te bewaren tussen snelle lokale reacties en stabiele teamniveauregulering.
Testen in virtuele gevechten en achtervolgingsspellen
Om te onderzoeken of Bi-GAP echte voordelen biedt, evalueerden de onderzoekers het in twee veeleisende testomgevingen. De eerste is een gevechtssimulator gebouwd op het real-time strategiespel StarCraft II, waar gemengde pelotons van eenheden beweging en aanvallen moeten coördineren tegen een sterke ingebouwde tegenstander. De tweede is een predator–prey-omgeving, waar snellere en langzamere agenten met verschillende capaciteiten elkaar achtervolgen of ontwijken in continue beweging. In beide omgevingen, en zowel bij volledige als gedeeltelijke zichtbaarheid, werd de nieuwe methode vergeleken met meerdere toonaangevende multi-agent reinforcement learning-technieken. Bi-GAP behaalde niet alleen hogere winstpercentages en beloningen, maar leerde ook sneller effectieve gedragingen en bleef stabiel naarmate het aantal agenten en hun diversiteit toenamen.
Wat dit betekent voor toekomstige AI-samenwerking
Kort gezegd laat de studie zien dat het aanbrengen van een lichte maar goed gestructureerde hiërarchie in grote, gemengde teams van AI-agenten hen veel betere samenwerkers kan maken. Door soortgelijke agenten te groeperen, gids-agents groepen te laten coördineren en globaal advies te mengen met lokale oordelen, beheert Bi-GAP complexe taken efficiënter dan eerdere benaderingen die ofwel te gecentraliseerd of te gefragmenteerd waren. Naarmate multi-agent systemen vaker voorkomen in robotica, verkeersbeheer, virtuele spellen en andere toepassingen in de echte wereld, kunnen dergelijke communicatie- en beslissingsschema’s helpen ervoor te zorgen dat groeiende digitale menigten zich minder gedragen als een verwarde massa en meer als een goed ingespeeld team.
Bronvermelding: Li, Y., Zhang, Z. & Wang, J. Bi-level graph attention paradigm with differential strategy integration for heterogeneous multi-agent reinforcement learning. Sci Rep 16, 12156 (2026). https://doi.org/10.1038/s41598-026-41722-w
Trefwoorden: multi-agent reinforcement learning, heterogene agenten, graf-attentie, coördinatie, hiërarchische besturing