Clear Sky Science · ar
نمط انتباه رسومي ثنائي المستويات مع دمج استراتيجي تفريقي لتعلّم التعزيز متعدد العملاء غير المتجانسين
لماذا يحتاج الكثير من الذكاءات الاصطناعية إلى التعلّم على التعاون
من فرق الروبوتات والسيارات ذاتية القيادة إلى أسراب الطائرات المسيرة واللاعبين الافتراضيين في ألعاب الاستراتيجية، تعتمد العديد من الأنظمة الحديثة على أعداد كبيرة من الوكلاء الاصطناعيين الذين يعملون معًا. لكن جعل هؤلاء الزملاء الرقميين يتنسيقون أصعب مما يبدو، خصوصًا عندما يمتلك كل منهم قدرات مختلفة ورؤية جزئية عما يحدث. تقدم هذه الورقة طريقة جديدة لتنظيم مثل هذه الفرق بحيث يمكنها مشاركة المعلومات اللازمة فقط، اتخاذ قرارات جماعية أفضل، والتوسع إلى مشكلات أكبر وأكثر تنوعًا مما كان ممكنًا سابقًا.
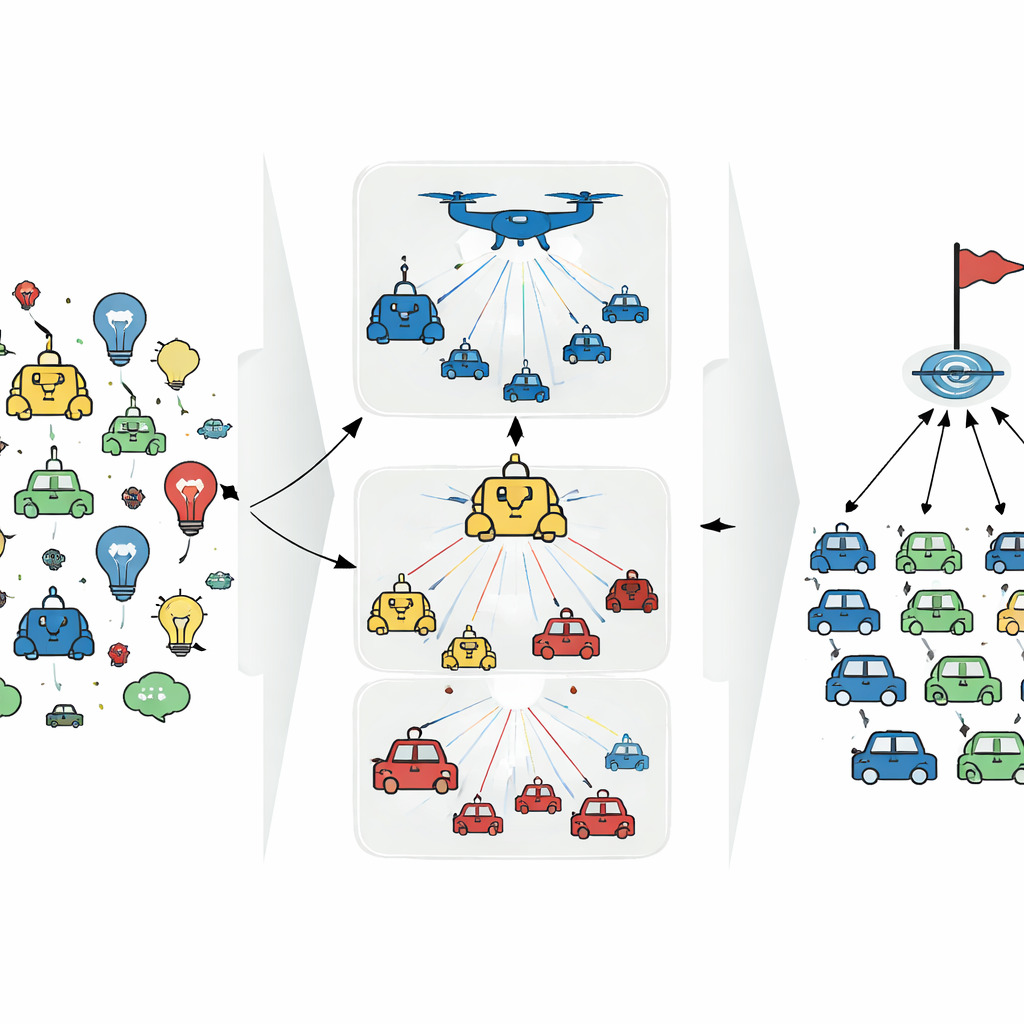
المجموعات والمرشدون والعمل الجماعي اليومي
ينطلق المؤلفون من فكرة بسيطة تعكس كيفية تعاون البشر والحيوانات: تقسيم الفريق إلى أدوار ومجموعات. في مشروع مكتبي، يجلب أعضاء التسويق والهندسة والمالية كلٌ مهاراته، ومنسق في كل مجموعة ينسق الخيارات المحلية ويتواصل مع منسقين آخرين. مستوحاة من ذلك، تُجمّع الطريقة المقترحة، المسماة نمط الانتباه الرسومي ثنائي المستويات (Bi-GAP)، الوكلاء الاصطناعيين حسب النوع. داخل كل مجموعة، يتصرف عدد من الوكلاء «الأعضاء» فعليًا في البيئة، بينما يجمع وكيل «المرشد» الافتراضي نظرة أوسع ويقدّم توجيهًا استراتيجيًا دون أن يتخذ إجراءات مباشرة بنفسه.
حوارات ذكية داخل المجموعات وعبرها
يكمن الابتكار الأساسي في Bi-GAP في طريقة تواصل هؤلاء الوكلاء. بدلاً من السماح لكل وكيل بالتحدث مع كل آخر—ما يتحول سريعًا إلى عبء مع تزايد حجم الفريق—تستخدم الطريقة آلية انتباه مكوّنة من طبقتين، مُنفذة على شكل رسم بياني. في الطبقة الأولى، يتشارك الوكلاء «الأعضاء» من نفس النوع المعلومات بشكل انتقائي، مع التركيز على زملائهم الأكثر صلة بوضعهم الحالي. يستمع وكيل المرشد لتلك المجموعة إلى جميع أعضائه، مثقلًا مداخلهم لتشكيل ملخّص مستنير. في الطبقة الثانية، تتواصل فقط وكلاء المرشد من المجموعات المختلفة مع بعضهم البعض، مستخدمين الانتباه مرة أخرى للتركيز على الشركاء الأكثر أهمية. تقلل هذه البنية ذات المرحلتين من فيضان الرسائل، تُنقّي الضوضاء، وتجعل النظام العام أكثر متانة تجاه المعلومات المفقودة أو المضللة.

مزاوجة نصائح الصورة الكلية مع الغرائز المحلية
التنسيق الجيد يتطلب أكثر من التواصل؛ يحتاج أيضًا إلى طريقة لدمج وجهات نظر مختلفة في قرار واحد. يتعامل Bi-GAP مع هذا بمنح كل وكيل فاعل مصدرين للتوجيه: تفكيره المحلي الخاص ونصيحة منتجة من وكيل مرشده. بدلًا من معاملة هذين المصدرين على قدم المساواة دائمًا، تقارن الطريقة بين الاستراتيجيتين المقترحتين. عندما يتوافقان إلى حد كبير، يعتمد الوكيل العضو أكثر على رؤيته المفصّلة المحلية، محافظًا على ردود فعل دقيقة. وعندما يختلفان اختلافًا كبيرًا، يُعطى منظور المرشد الأوسع وزنًا أكبر، موجهًا الوكيل نحو مسار عمل يتناسب أكثر مع خطة المجموعة الشاملة. تساعد هذه المزج التكيفية على موازنة الاستجابات المحلية السريعة مع التنسيق المستقر على مستوى الفريق.
اختبارات في معارك افتراضية وألعاب مطاردة
لفحص ما إذا كان Bi-GAP يقدم فوائد حقيقية، قيّم الباحثون الطريقة في بيئتين تجريبيتين متطلباتين. الأولى محاكٍ قتالي مبني على لعبة الاستراتيجية الزمنية الحقيقية StarCraft II، حيث يجب على فرق مختلطة من الوحدات تنسيق الحركة والهجمات ضد خصم قوي مدمج. والثانية بيئة مفترس–فريسة، حيث يطارد أو يتهرب وكلاء أسرع وأبطأ بقدرات مختلفة من بعضهم البعض في حركة مستمرة. في كلتا الحالتين، وتحت رؤى كاملة وجزئية، قورنت الطريقة الجديدة بعدة تقنيات رائدة في تعلّم التعزيز متعدد العملاء. لم يكتفِ Bi-GAP بتحقيق معدلات فوز ومكافآت أعلى، بل تعلّم سلوكيات فعالة أسرع وظلّ مستقرًا حتى مع زيادة عدد الوكلاء وتنوّعهم.
ما الذي يعنيه هذا لتعاون الذكاء الاصطناعي المستقبلي
بعبارات بسيطة، تُظهر الدراسة أن إعطاء فرق كبيرة ومختلطة من الوكلاء الاصطناعيين تسلسلًا هرميًا خفيفًا لكنه منظمًا جيدًا يمكن أن يجعلهم متعاونين أفضل بكثير. من خلال تجميع الوكلاء المتشابهين، والسماح لوكلاء المرشد بالتنسيق عبر المجموعات، ودمج النصيحة العالمية مع الحكم المحلي، يدير Bi-GAP المهام المعقدة بكفاءة أكبر من النهج السابقة التي كانت إما مركزية جدًا أو مجزأة للغاية. مع تزايد انتشار أنظمة متعددة العملاء في الروبوتات، والتحكم في المرور، والألعاب الافتراضية، وتطبيقات العالم الواقعي الأخرى، قد تساعد مثل هذه مخططات التواصل واتخاذ القرار على ضمان أن تتحرك الحشود الرقمية المتنامية أقل شبهًا بجماعة مشوشة وأكثر شبهًا بفريق مدرّب جيدًا.
الاستشهاد: Li, Y., Zhang, Z. & Wang, J. Bi-level graph attention paradigm with differential strategy integration for heterogeneous multi-agent reinforcement learning. Sci Rep 16, 12156 (2026). https://doi.org/10.1038/s41598-026-41722-w
الكلمات المفتاحية: تعلّم التعزيز متعدد العملاء, عملاء غير متجانسون, انتباه رسومي, تنسيق, تحكم هرمي