Clear Sky Science · zh
伪相关中群体到个体概括性的缺失
为何我们的食物信念可能具有误导性
许多人觉得最美味的食物往往最不健康,尽管有大量菜肴既营养又美味。本文探讨了这种顽固信念如何产生,以及更关键的一点:不同人依赖这些捷径的程度为何可能截然不同。通过剖析我们如何从日常食物经历中学习,作者们展示了一个简单的心理规则如何塑造我们对世界的看法——并且在对人群取平均值时,可能掩盖了我们思维的多样性。
我们如何在未直接看到关联时做出推断
人类不断地推断关系:乌云意味着下雨,高发表量意味着学术成功,对许多人来说,不健康的食物意味着更美味。通常,我们并不会追踪事物真正共同出现的频率;相反,我们依赖各自独立的出现频率。作者关注这一捷径,称为伪相关推断:人们观察到周围环境中“健康”和“美味”各自的基准出现率,并把这些基准率当作直接揭示健康与口味之间联系的证据。当信息稀缺时,这种策略可能高效,但在环境失衡时很容易产生错觉——例如,当市面上有大量不健康但诱人的食物时。
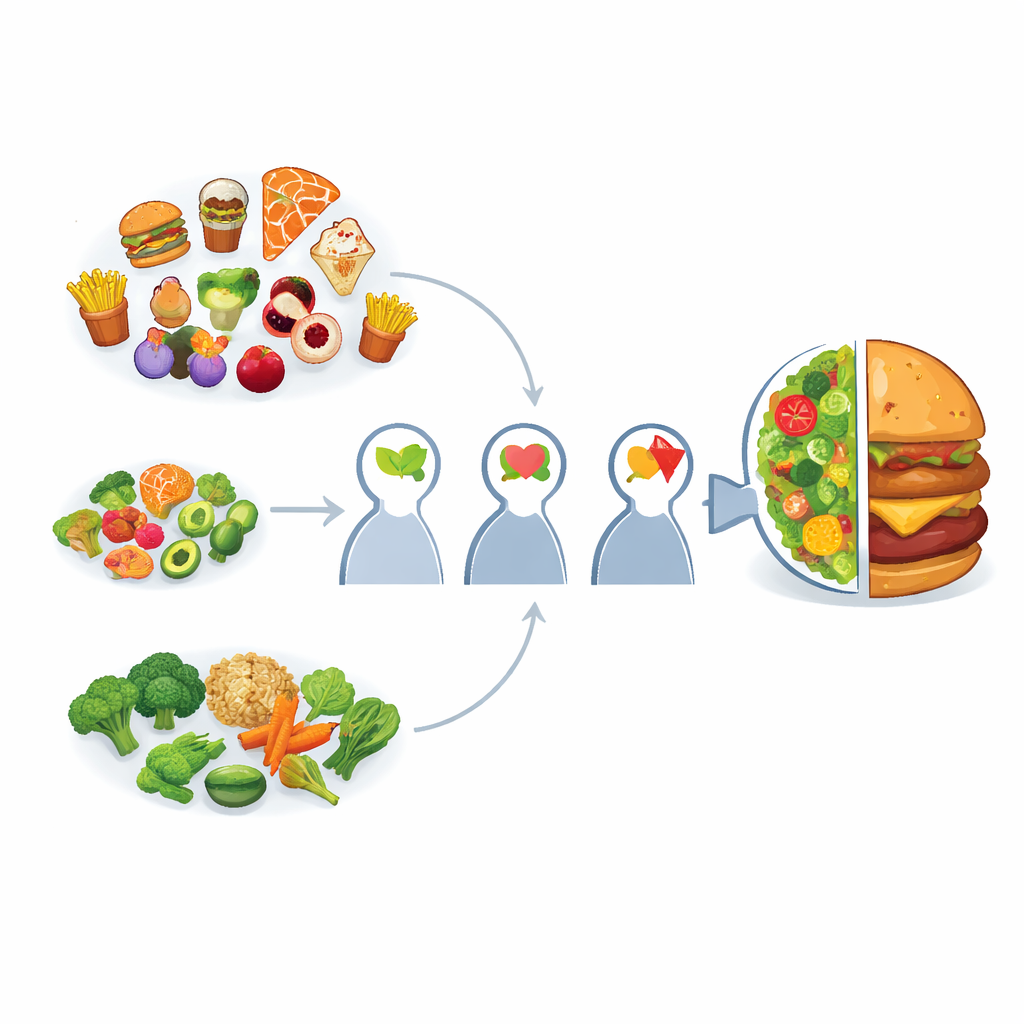
一个基于食物环境的学习计算模型
为研究这一过程,研究者们搭建了一个基于主体的计算模型,模拟个体在不同环境中逐一遇到食物。对于每一种食物,主体记录其是否健康以及是否美味。基于这些经历,主体可以计算两类信息:健康与口味的真实配对(它们共同出现的频率)以及基准率(每一项总体出现的频率)。模型假设每个主体将这两种信息混合为单一信念,受一个偏向强度参数控制。在一个极端,信念仅遵循真实配对;在另一个极端,则仅遵循基准率。随着主体见到更多食物,他们不断更新信念,模仿人们如何逐步形成有关健康—美味关联的印象。
人们依赖捷径——但程度不一
随后,作者将该模型拟合到现有实验室数据,实验中参与者观看了许多在健康与美味上各异的餐食。实验环境巧妙设计,使得基准率与真实配对有时指向相反方向。当模型为所有人使用单一共享的偏向强度时,它重现了在基准率偏斜环境中人们信念向“不健康更美味”观念倾斜的平均变化。然而,该群体水平的设定未能匹配实验显示出的个体反应广泛差异。当研究者允许每个人拥有自己的偏向强度时,他们发现强有力的证据表明多数人倾向于使用基准率,但程度差异很大。平均而言,个体依赖伪相关的程度低于群体级模型所显示的,而个体值则从很低到很高不等。
何时简单模型比复杂模型更能泛化
研究组又进一步测试这些拟合参数是否能预测在第二个略有不同食物环境的独立实验中的结果。有趣的是,一刀切的群体参数在预测该新研究中的平均信念方面表现优于更精细的个体参数。更丰富的个体特定模型能捕捉原始数据集内的变异,但似乎拟合了在新情境中不再出现的噪声。这揭示了许多领域都熟悉的紧张关系:紧密追踪个体的模型能在一项研究中解释更多细节,但可能比更简洁、更节制的描述更难以泛化。
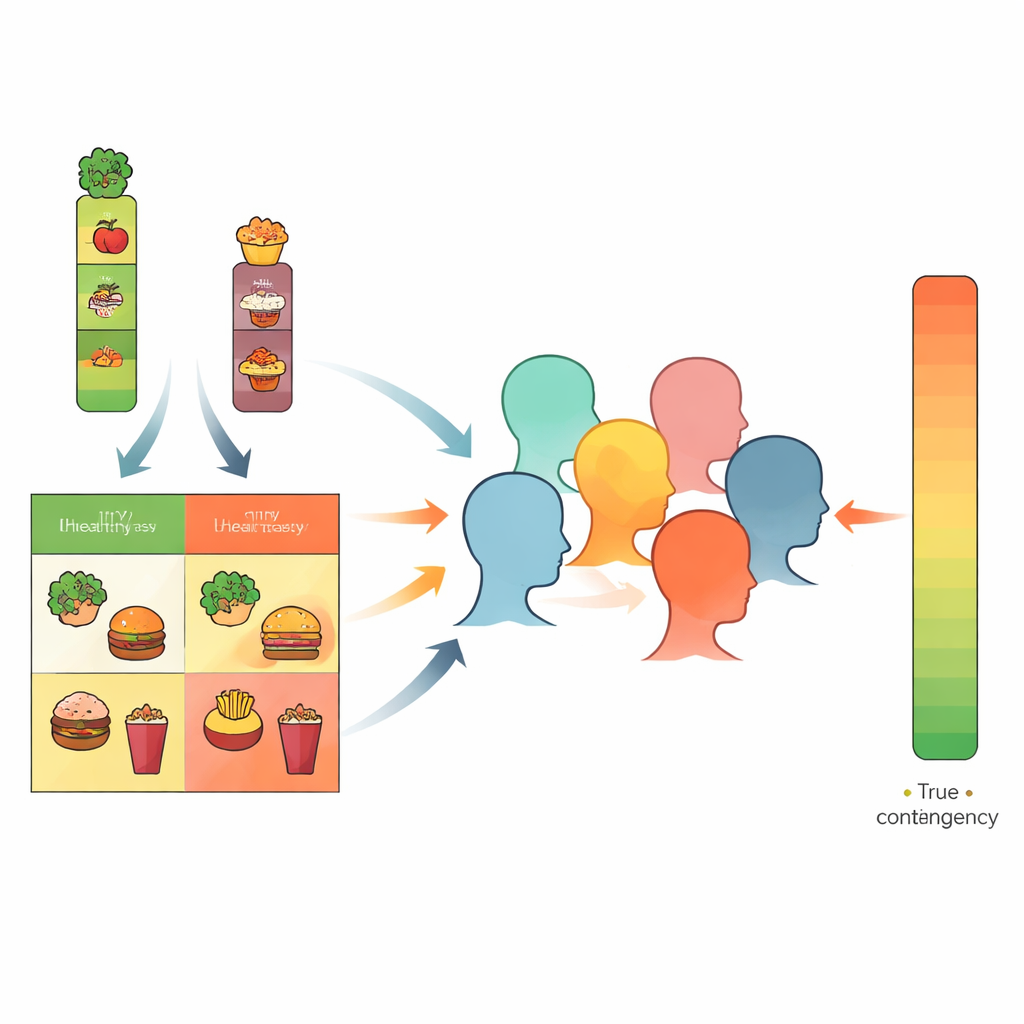
这对理解与改变信念有何意义
这些发现表明,我们许多关于事物如何搭配的日常信念——例如“不健康等于美味”——可能源自我们解读环境结构的简单方式,而非事物之间的真实内在关系。然而,人们在多大程度上依赖这一捷径存在显著差异,且对个体求平均的模型可能高估这种依赖。对于设计健康信息、消费政策或社会干预的人来说,该研究提供了两点启示:改变我们周围事物的常见程度可以系统性地改变信念;在针对行为改变或解释健康不平等时,关注个体差异可能至关重要。
引用: Kaan, J., Kunz, S., Moore, S. et al. Lack of group-to-individual generalizability in pseudocontingencies. Sci Rep 16, 10459 (2026). https://doi.org/10.1038/s41598-026-41585-1
关键词: 信念形成, 饮食习惯, 认知偏差, 计算建模, 健康感知