Clear Sky Science · zh
基于数据驱动的可解释慢性肾脏病检测:基于随机森林的数据插补与元集成学习
这对日常健康为何重要
慢性肾脏病常常悄无声息地进展,在出现明显症状之前就已对身体造成损害。对于许多人,尤其是在资源有限的地区,虽然可以做简单的血液和尿液检测,但医生并不总有工具能充分利用这些信息。本研究展示了一种经过精心设计的人工智能(AI)系统如何将常规化验数据转化为肾脏问题的早期预警信号,同时仍让临床医生理解计算机为何对某位患者发出警示。
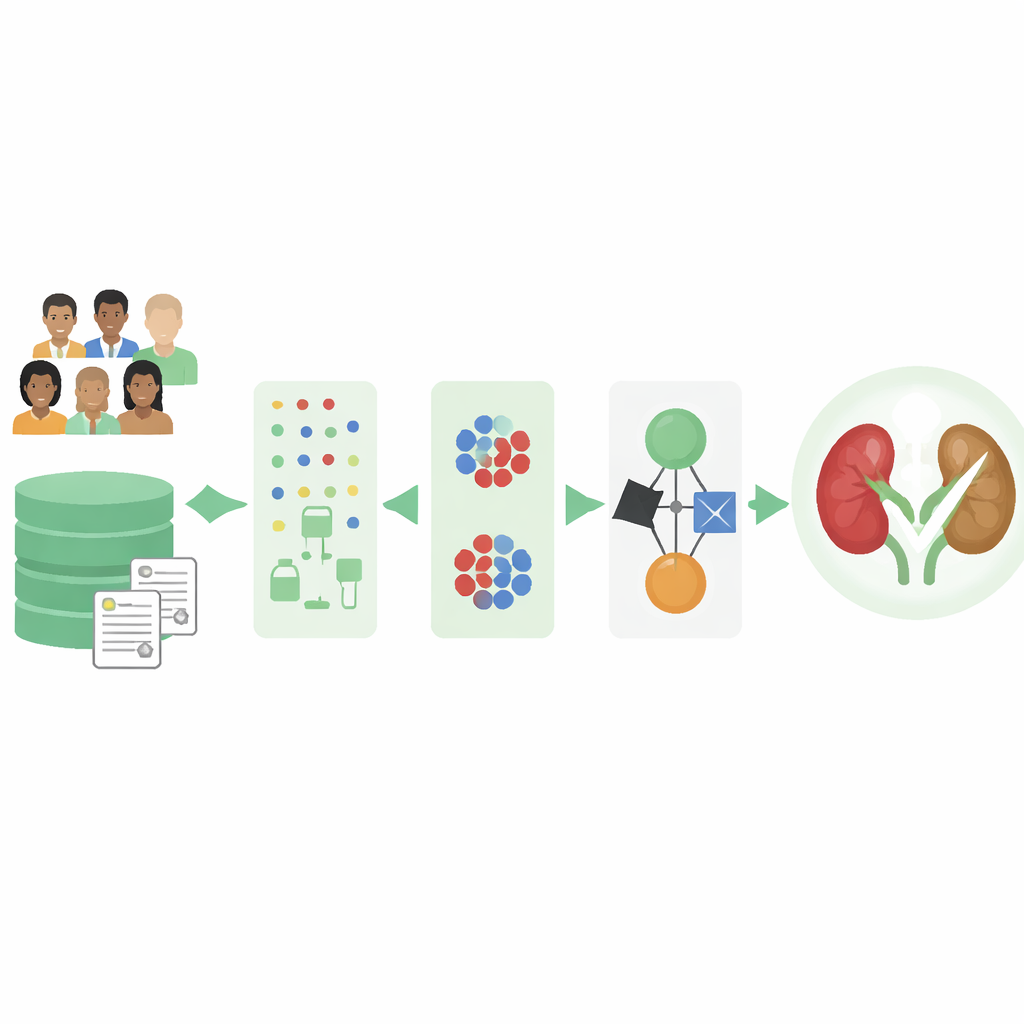
把杂乱的门诊记录变成可用线索
现实世界的病历很少是完整的。化验结果可能缺失,且某些类型的患者记录频次远高于其他类型。作者使用了一个知名的公开数据集,包含400名个体,每人由25项基本测量描述,如年龄、血压、血球计数和与肾脏相关的化学指标。许多条目存在缺失,且无肾病者人数多于有肾病者,这会使计算模型产生偏差。为了解决这些问题,团队首先构建了一个智能清洗步骤,从已有数据中学习模式来填补缺失值,而不是简单地丢弃不完整记录或采用粗糙的均值替代。
在病与非病之间平衡权重
由于数据集中非肾病病例更多,若直接训练模型,模型可能会学会保守地多数预测“健康”,从而获得看似很高的分数。为对抗这种不平衡,研究者采用了一种方法来生成代表性较强的、欠代表组的合成样本。本质上该方法研究确诊有慢性肾脏病的患者,并生成新的、略有变动但与其相似的病例。经过此步骤,计算机看到的病人与健康个体比例更为平衡,有助于它关注那些早期且易被忽视的预警信号。
多位“简单模型”协同工作
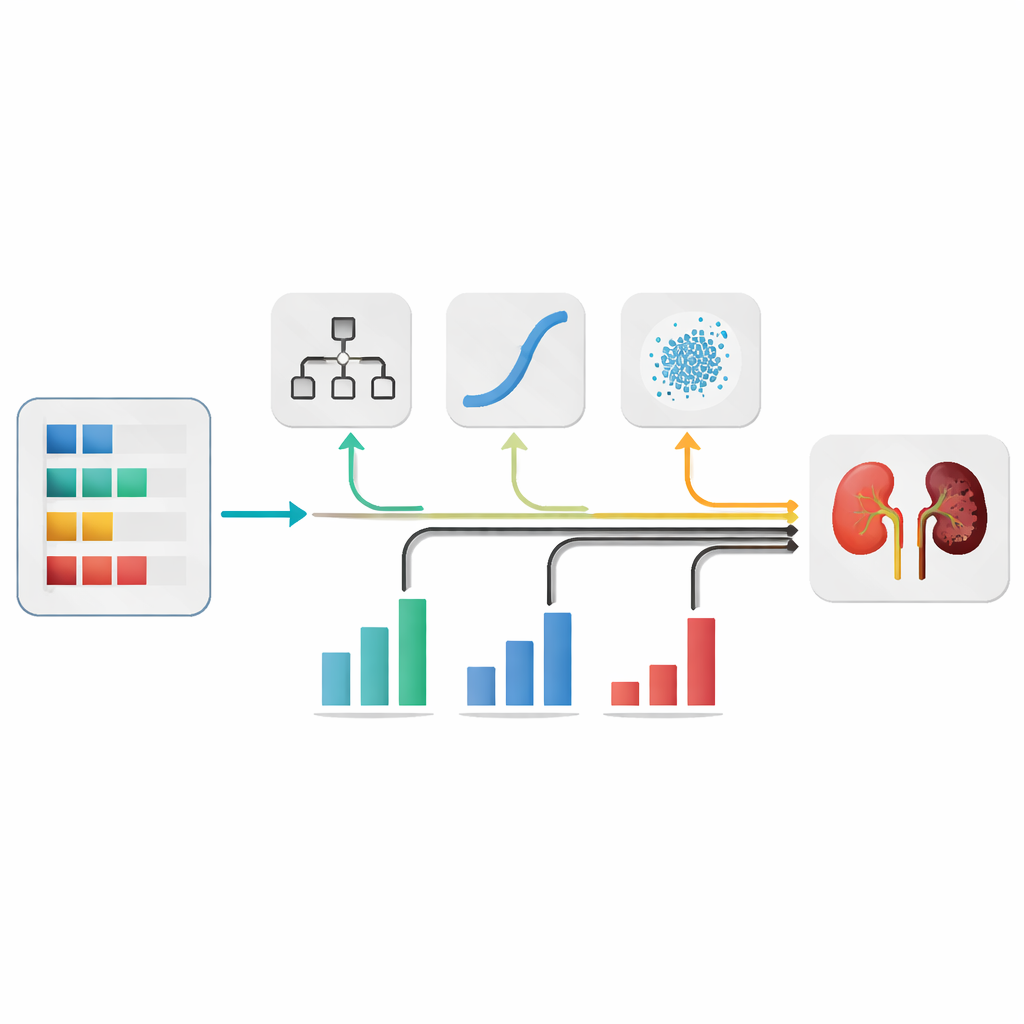
作者没有押注于单一算法,而是组合了若干常见的机器学习模型,让它们以不同方式审视相同的患者数据。他们评估了五个候选模型并选出表现最好的三种:决策树、逻辑回归模型和一种简单的概率分类器。这些模型随后被组合成一个“集成”,每个模型都给出关于患者是否可能患有肾病的判断。最终决策是它们输出的加权混合,类似于咨询多位医生,但各自意见按其可靠性加权计算。
让数字“灰狼”群体挑选最佳配比
决定在集成中信任各模型多少至关重要。作者没有凭空猜测,而是使用了一种受灰狼捕猎行为启发的优化技术。该算法探索多种权重组合,并逐步朝着在保留数据上表现最好的混合方式移动。经过调优的组合在交叉验证中将近99%的病例分类正确,并且保持了极低的漏诊率——这在筛查场景中尤其重要。
为临床医生打开黑盒
医学领域对AI的一个主要顾虑是其决策可能显得不透明。为了解决这一点,研究者使用了可解释性工具,展示了哪些化验特征在每位患者的预测中将判断推向或远离肾脏病。他们发现如尿白蛋白、红细胞计数、血压、糖尿病状态和与肾脏相关的血液标志物等测量值对模型判断有强烈影响。这些模式与医学知识一致,表明该系统学习到的是临床上合理的规则,而不是晦涩的统计巧合。
这对患者可能意味着什么
简单来说,这项工作表明,经过精心准备并具备解释性的AI助手能够将常规化验数据转化为高度可靠的慢性肾脏病早期检测工具。通过清理缺失信息、纠正数据不平衡、融合多种简单模型并揭示决策过程,该框架在保持高准确度的同时避免成为神秘的黑盒。虽然在床旁临床使用前仍需在更大、更具多样性的患者群体上进行验证,但这一研究指向了这样一种未来:廉价的化验结合透明的AI,能帮助医生更早发现肾脏问题并更自信地制定个性化护理方案。
引用: Gupta, R., Gambhir, S., Krejcar, O. et al. Data-driven explainable chronic kidney disease detection using RF based data imputation and meta-ensemble learning. Sci Rep 16, 12679 (2026). https://doi.org/10.1038/s41598-026-41425-2
关键词: 慢性肾脏病, 医学人工智能, 集成学习, 健康数据预处理, 可解释人工智能