Clear Sky Science · zh
CLWD:用于肺腺癌亚型分类的中国组织病理学数据集
为何需要新的肺癌影像集
肺癌仍然是全球最致命的癌症之一,在中国的发病人数高于世界其他任何地方。医生现在了解到,一种常见类型——肺腺癌,并非单一疾病,而是由具有不同预后风险的多种生长模式拼凑而成。在显微镜下区分这些模式非常困难,即便对专家来说也耗时。本文介绍了一个来自中国患者的高质量开放肺组织图像数据集,旨在帮助研究人员建立能够更一致识别这些细微模式的计算工具,并最终支持更准确的诊断与治疗决策。
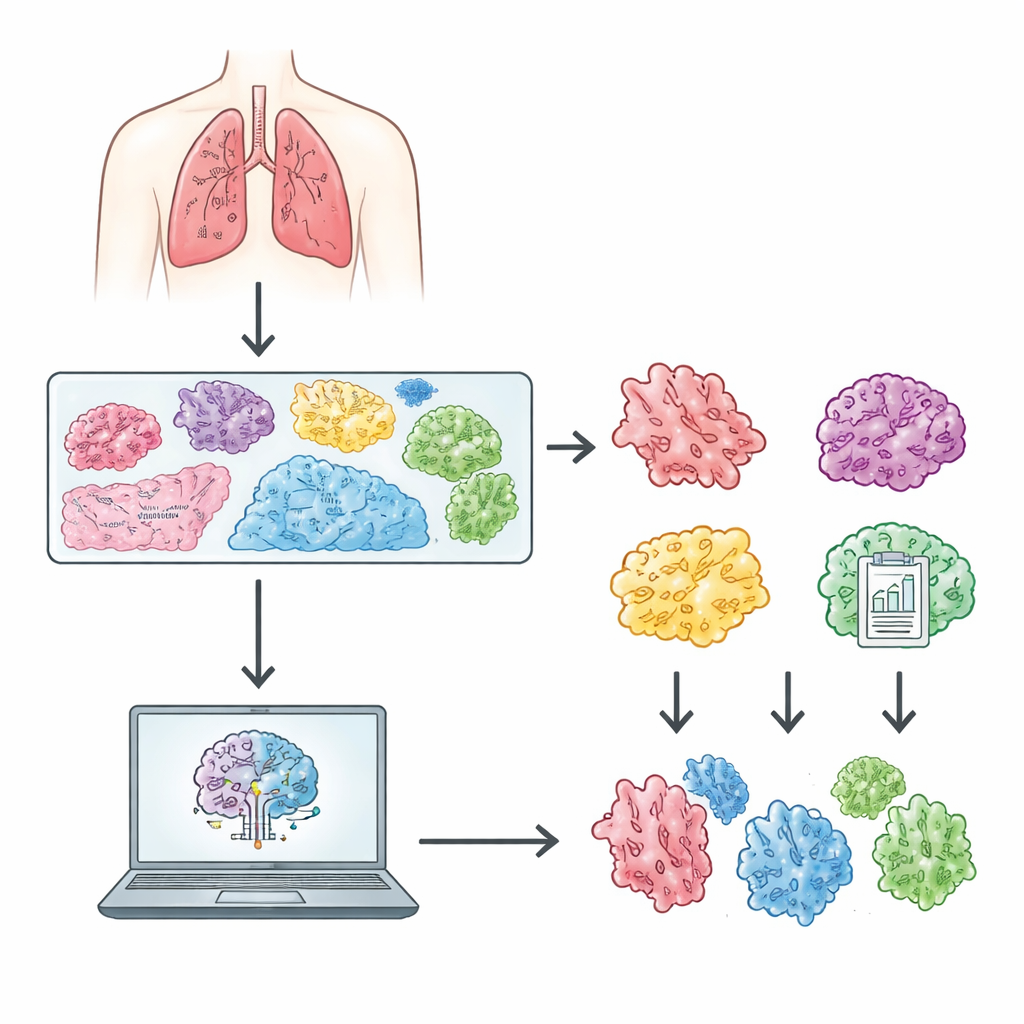
肺内的挑战
当患者的肺肿瘤被切除后,病理科医生会将组织切成薄片、染色并在显微镜下观察。在肺腺癌的切片中,可以看到肿瘤细胞生长和侵袭的几种不同方式:有些模式相对温和,预后较好;而另一些则侵袭性强,复发风险更高。现行国际指南将这些模式归为原位、腺泡型(acinar)、乳头状(papillary)、臀层样(lepidic)、微乳头型(micropapillary)、实性(solid)和筛状(cribriform)等类别。正确识别肿瘤中占优势的模式有助于医生评估风险并决定随访或治疗的强度。然而,这一过程劳动强度大,且易在专家之间产生分歧。
把玻片变成数字数据
数字扫描仪的进步现在能够将整张显微镜玻片捕捉为极大且细节丰富的图像,供计算机分析。然而,要构建可靠的人工智能工具,需要反映真实临床实践的大型、精心标注的数据集。作者通过收集来自云南省一家大型医院在2020年至2023年间治疗的210名患者的408张染色玻片,构建了中国肺腺癌全片图像数据集(CLWD)。每张玻片以很高的放大倍数扫描,细节水平可与病理学家在显微镜下观察到的相媲美。经验丰富的肺癌病理学家挑选代表性切片,核验染色质量和组织完整性,排除了任何模糊或可能被误读的玻片。除图像外,团队还整理了去标识化的信息,如患者年龄、性别、诊断类别,以及与2015年和2021年世界卫生组织分类兼容的详细生长模式标签。
计算机如何从玻片中学习
CLWD 中的图像过于庞大,无法一次性输入神经网络。相反,每张全片图像会被自动切割成许多仅包含组织的小正方形补丁,同时滤除空白背景和扫描伪影。研究采用一种称为多实例学习(multiple-instance learning)的方法,将来自一张玻片的所有补丁视为一个组。预训练神经网络先从每个补丁提取视觉特征,然后专门的模型学习如何将这些特征组合起来,以判断哪种亚型标签最适合整张玻片。作者评估了三种基于注意力的现代方法——CLAM、TransMIL 和图变换器(Graph Transformer)——每种方法都旨在关注最具信息量的区域及补丁间的关系。这一框架类似于人类专家在形成总体判断前对玻片不同区域进行视觉扫描的方式。
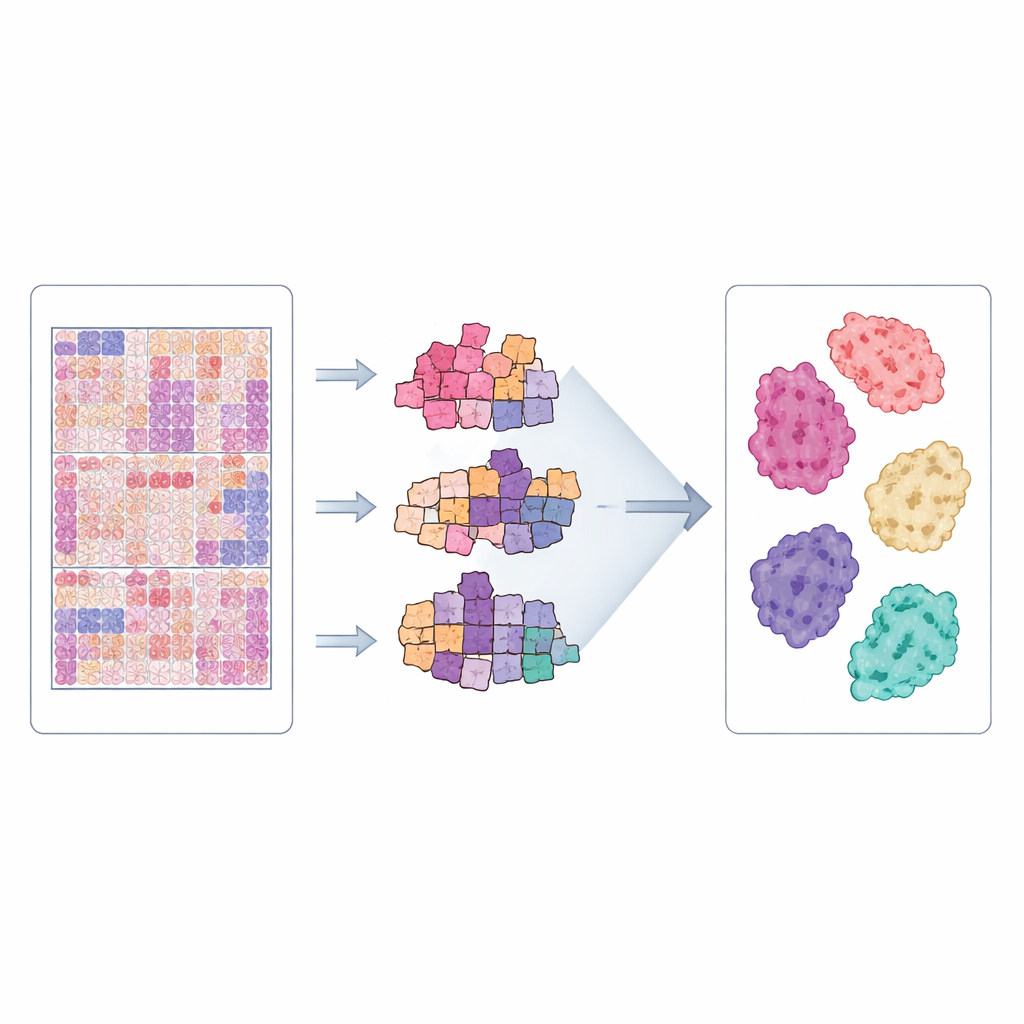
将数据集付诸检验
为检验 CLWD 是否真正有助于计算机辅助手段的诊断,团队进行了大量实验。他们按患者将数据划分为训练组和测试组,确保同一患者的图像不会同时出现在两组中,并使用重复交叉验证以降低随机波动影响。三种模型被训练以区分七种生长模式及相关的诊断分组。性能使用评估模型将某一亚型与其他亚型区分开来的标准指标来衡量。在多次运行中,模型表现出较高的判别能力,尤其对原位和若干侵袭型等定义清晰的模式表现尤为突出,表明数据集中存在一致且可学习的视觉信号。当将相同方法应用于来自达特茅斯的现有美国数据集时,CLWD 常常产生相当或更好的结果,表明它是一个强有力的基准,并且作为跨国比较的有价值补充。
这对患者与研究者的意义
CLWD 提供了一个开放且经过良好整理的中国患者肺癌图像集合,弥补了目前主要基于西方队列构建的资源空白。通过将丰富的临床信息与经仔细核验的玻片标签配对,它为研究人员开发和比较用于肺腺癌早期检测与精细分型的人工智能系统提供了坚实基础。尽管该数据集有局限性——样本来自单一医院、某些亚型较为罕见且仅包含常规染色——但它仍代表了朝着更具包容性的数据驱动病理学迈出的重要一步。随着基于 CLWD 及类似数据集训练的未来工具逐步成熟,它们有望帮助病理学家更可靠地识别高风险模式,指导随访护理,并最终改善肺癌患者的结局。
引用: Chen, Y., Zhao, H., Wang, L. et al. CLWD: a Chinese histopathology dataset for lung adenocarcinoma subtype classification. Sci Data 13, 599 (2026). https://doi.org/10.1038/s41597-026-06906-z
关键词: 肺腺癌, 数字病理学, 组织病理学图像, 深度学习, 癌症亚型