Clear Sky Science · sv
CLWD: en kinesisk histopatologisk dataset för klassificering av subtyper av lungadenokarcinom
Varför en ny bildsamling för lungcancer spelar roll
Lungcancer är fortsatt en av de dödligaste cancerformerna globalt, och i Kina drabbar den fler människor än någon annanstans. Läkare vet nu att en vanlig form, lungadenokarcinom, inte är en enhetlig sjukdom utan ett lapptäcke av olika tillväxtmönster som innebär mycket olika risker för patienten. Att skilja dessa mönster under mikroskopet är svårt, även för experter, och det tar tid. Denna artikel presenterar en ny öppen dataset med högkvalitativa lungvävnadsbilder från kinesiska patienter, avsedd att hjälpa forskare att bygga datorverktyg som kan känna igen dessa subtila mönster mer konsekvent och i slutändan stödja mer exakt diagnostik och behandling.
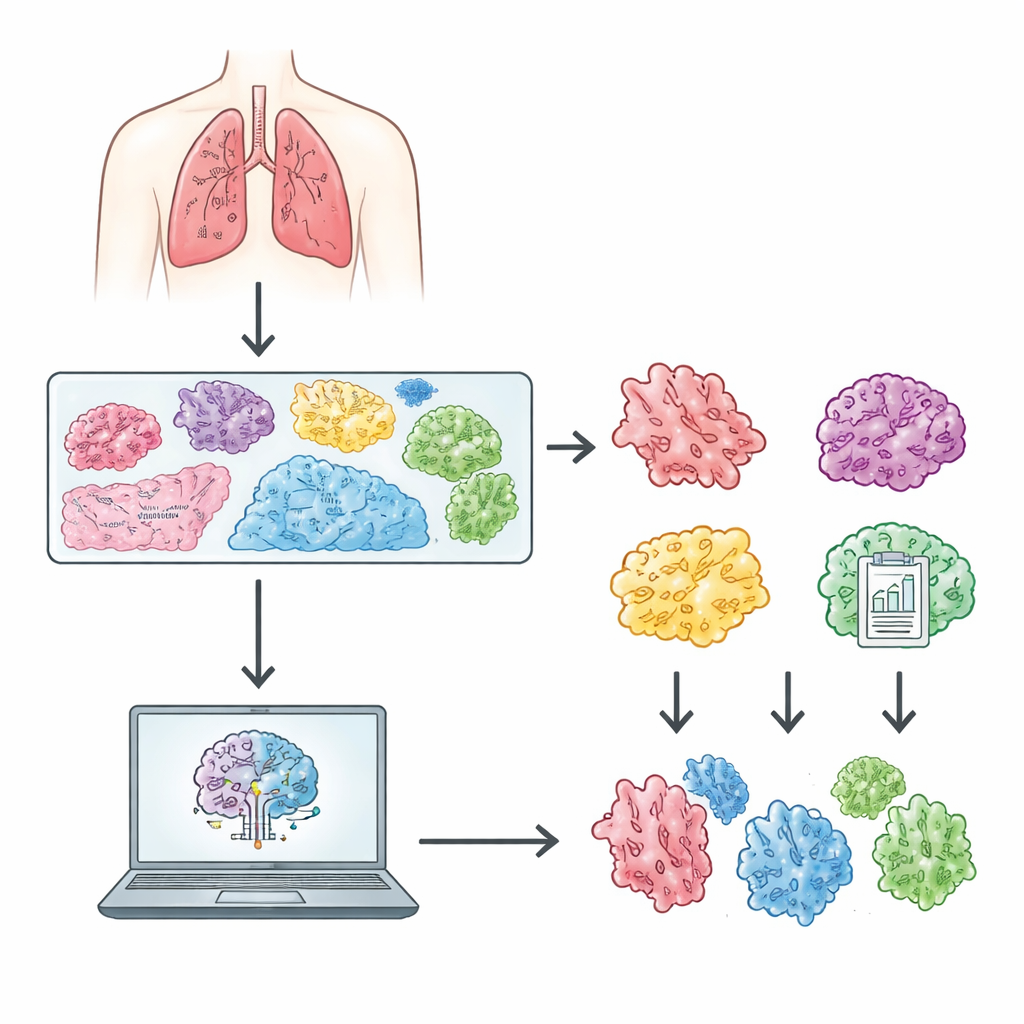
Utmaningen inne i lungan
När en patients lungtumör avlägsnas skivar patologer vävnaden i tunna snitt, färgar dem och granskar preparaten i mikroskop. Vid lungadenokarcinom visar dessa preparat flera distinkta sätt som tumörceller växer och invaderar på: vissa mönster är relativt lugna och förknippade med bättre prognos, medan andra är aggressiva och kopplade till högre återfallsrisk. Nuvarande internationella riktlinjer grupperar dessa mönster i kategorier såsom in situ, acinär, papillär, lepidisk, mikropapillär, solid och kribriform. Att korrekt identifiera vilket mönster som dominerar i en tumör hjälper läkare att uppskatta risk och avgöra hur noggrant en patient ska följas upp eller behandlas. Processen är dock arbetskrävande och kan ge upphov till oenighet mellan specialister.
Från glaspreparat till digitala data
Framsteg inom digitala skannrar gör det nu möjligt att fånga hela mikroskoppreparat som enorma, detaljerade bilder som datorer kan analysera. För att bygga pålitliga artificiella intelligens‑verktyg krävs emellertid stora, noggrant annoterade dataset som speglar verklig klinisk praxis. Författarna skapade Chinese Lung Adenocarcinoma WSI Dataset (CLWD) genom att samla 408 färgade preparat från 210 patienter som behandlats vid ett större sjukhus i Yunnanprovinsen mellan 2020 och 2023. Varje preparat skannades med mycket hög förstoring och gav en detaljnivå jämförbar med vad en patolog ser genom ett mikroskop. Erfaren lungcancerpatologer valde representativa sektioner, verifierade färgningens kvalitet och vävnadens integritet, och exkluderade preparat som var tvetydiga eller kunde misstolkas. Parallellt med bilderna sammanställde teamet avidentifierad information som patientålder, kön, diagnostisk kategori samt detaljerade tillväxtmönster‑etiketter som är kompatibla med både Världshälsoorganisationens klassificeringar från 2015 och 2021.
Hur datorer lär sig från preparaten
Bilderna i CLWD är så stora att de inte kan matas in i ett neuralt nätverk på en gång. Istället delas varje helbild automatiskt upp i många små kvadratiska patchar som bara innehåller vävnad, medan tom bakgrund och skanningsartefakter sorteras bort. Studien använder en metod som kallas multiple‑instance learning, där alla patchar från ett preparat behandlas som en grupp. Ett förtränat neuralt nätverk extraherar först visuella kännetecken från varje patch, och sedan lär sig specialiserade modeller hur dessa kännetecken ska kombineras för att avgöra vilken subtyp‑etikett som bäst beskriver hela preparatet. Författarna utvärderade tre moderna attention‑baserade metoder—CLAM, TransMIL och en Graph Transformer—var och en utformad för att fokusera på de mest informativa regionerna och relationerna mellan patcharna. Detta ramverk speglar hur en mänsklig expert visuellt skannar olika områden av ett preparat innan hen bildar en helhetsbedömning.
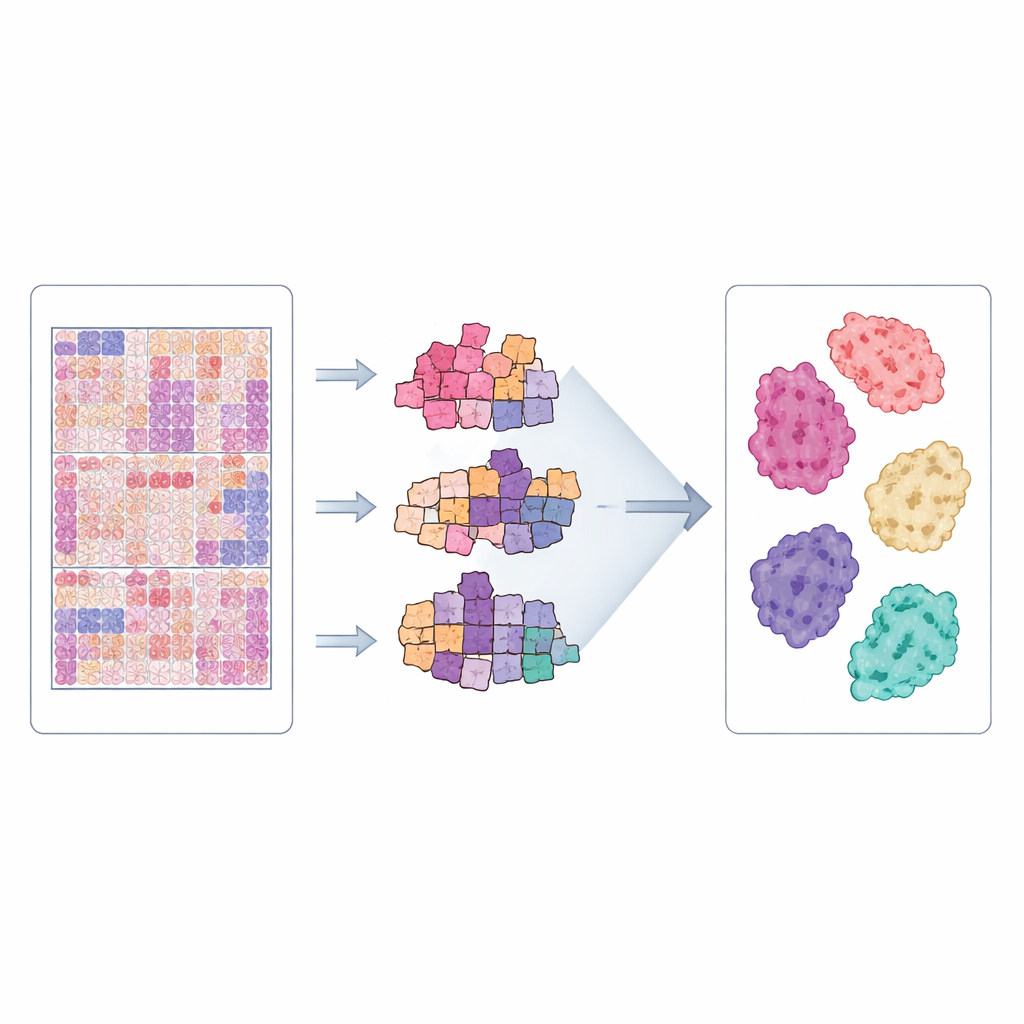
Att testa datasetet
För att kontrollera om CLWD verkligen är användbart för datorstödd diagnostik genomförde teamet omfattande experiment. De delade in patienter i separata grupper för träning och testning så att bilder från samma person aldrig förekom i båda uppsättningarna, och använde upprepad korsvalidering för att minska slumpmässiga variationer. De tre modellerna tränades för att skilja mellan sju tillväxtmönster och relaterade diagnostiska grupperingar. Prestanda mättes med standardmetrik som bedömer hur väl modellerna separerar en subtyp från de andra. Över många körningar uppnådde modellerna hög diskriminering, särskilt för tydligt definierade mönster såsom in situ och flera invasiva former, vilket visar att datasetet innehåller konsekventa och inlärbara visuella signaler. När samma metoder tillämpades på ett befintligt amerikanskt dataset från Dartmouth gav CLWD ofta lika bra eller bättre resultat, vilket tyder på att det är en stark referens och ett värdefullt komplement för jämförelser över länder.
Vad detta betyder för patienter och forskare
CLWD‑samlingen erbjuder en öppen, välkurerad uppsättning lungcancerbilder från kinesiska patienter och fyller ett gap i befintliga resurser som till stor del byggts på västerländska kohorter. Genom att kombinera rik klinisk information med noggrant kontrollerade preparatetiketter ger den forskare en solid grund för att utveckla och jämföra artificiella intelligenssystem för tidig upptäckt och förfinad subtypning av lungadenokarcinom. Datasetet har visserligen begränsningar—det kommer från ett enda sjukhus, vissa subtyper är mindre vanliga och endast standardfärgning ingår—men det utgör ändå ett viktigt steg mot mer inkluderande, datadriven patologi. När framtida verktyg tränade på CLWD och liknande dataset mognar kan de hjälpa patologer att upptäcka högriskmönster mer pålitligt, vägleda uppföljning och i slutändan förbättra utfallen för personer med lungcancer.
Citering: Chen, Y., Zhao, H., Wang, L. et al. CLWD: a Chinese histopathology dataset for lung adenocarcinoma subtype classification. Sci Data 13, 599 (2026). https://doi.org/10.1038/s41597-026-06906-z
Nyckelord: lungadenokarcinom, digital patologi, histopatologiska bilder, djupinlärning, cancersubtyper