Clear Sky Science · zh
一个协调统一的全球空气质量监测元数据集
为什么更清晰的空气数据与日常生活息息相关
空气中微小颗粒造成的污染是全球主要的环境健康风险之一,每年导致数百万例过早死亡。政府依赖数以千计的地面监测站来判断何时何地的空气不适合呼吸。然而,不同国家对这些监测站的描述方式各异,使得跨区域比较空气质量或评估政策成效变得出人意料地困难。本研究提出了一个新的全球数据集和方法,将这张拼贴式的监测网络加以整理,帮助科学家和决策者更清晰地把握空气污染暴露的全貌。
看清全球各地互不统一的监测网络
作者从一个简单但有力的观点出发:空气质量测量的价值不仅取决于测量什么,还取决于在何处以及出于何种目的进行测量。靠近繁忙公路的站点所传达的信息,与远离主要污染源的乡村站点完全不同。各机构通常沿两个维度标注站点:位于城市还是乡村,以及是反映背景状况还是受交通或工业等局地排放强烈影响。然而,目前并没有一个全球一致的站点标注体系。研究团队汇集了来自欧洲、美国、加拿大、日本、南非等地官方网络的信息,并结合一个开放全球平台的位置数据,最终整理出约15,000个颗粒物监测站点的元数据,涵盖106个国家。
用影像与数值理解每个站点
为在各国迥异的体系之间统一站点标签,研究人员借助了关于每个监测点周边环境的详尽信息。他们使用了来自欧洲航天局的超精细地表覆盖图,这些卫星产品以约10米的分辨率描述某一区域是建筑用地、林地、农田、水体或其它地表类型。在每个站点周围,他们裁切出约2公里见方的小方图,捕捉附近道路、社区、农田和工业区的景观。随后他们又加入若干辅助数据层:细颗粒物与一氧化碳浓度估算、人口密度、来自不同行业的关键污染物排放量估计,以及大型工业设施(如燃煤电厂、钢厂、水泥厂)的位置与类型。
分类工具的工作原理
基于这些输入,团队训练了先进的图像识别模型来推断每个站点应有的标签。该方法分为两个阶段。首先,模型借助标注的样本和卫星切片学习区分城市与乡村站点。其次,它将这层知识与所有其它数据结合,用以判断某站点是测量一般背景空气,还是受附近污染源主导。为了充分利用图像与数值信息,研究者设计了一种融合架构,配备注意力机制以便为每个站点估算在多大程度上应信任视觉线索 versus 排放或人口等数值指标。此方法基于为大规模图像数据集开发的现代神经网络设计,并针对空气质量监测的具体需求进行了调整。
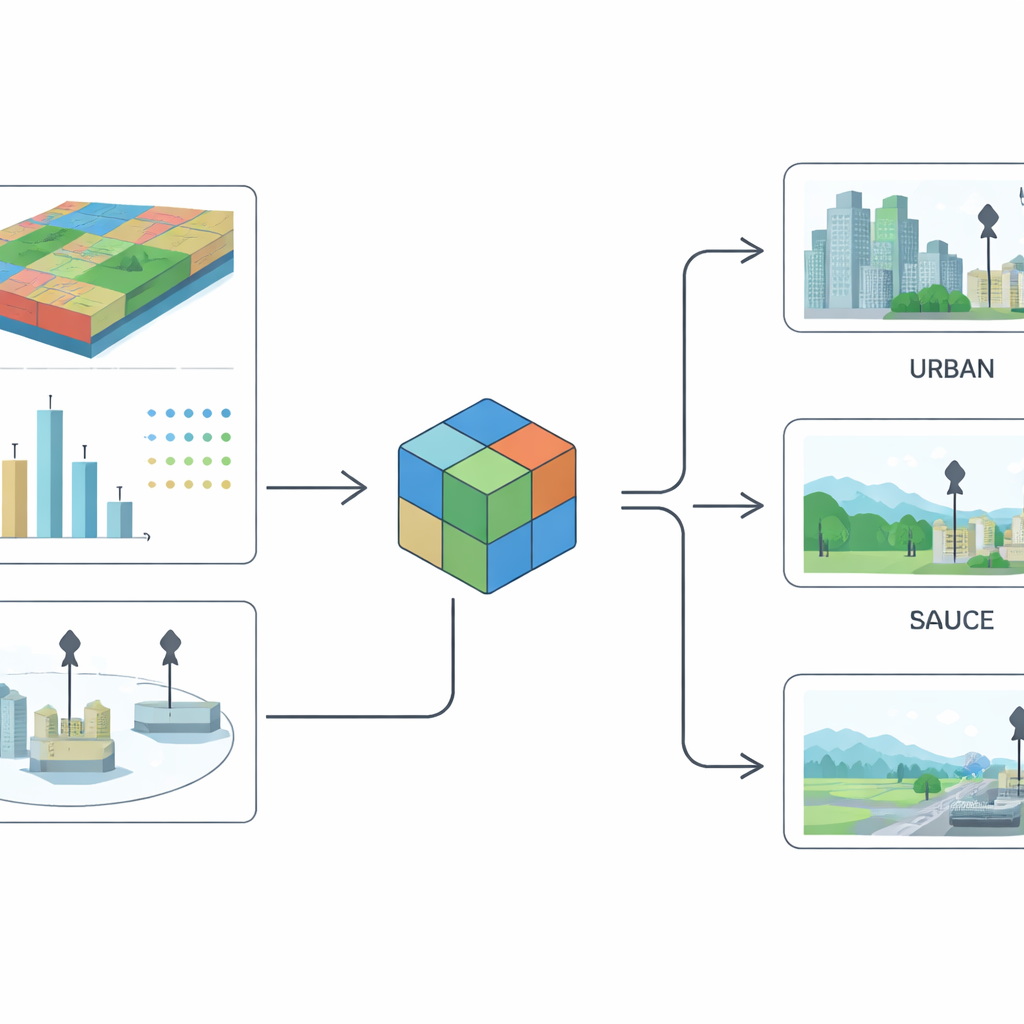
新的全球数据集提供了什么
研究成果是 Metair —— 一个协调统一的全球颗粒物监测站目录。对于每个站点,数据集列出识别码、国家、位置、海拔、所测污染物、城市/乡村属性,以及是否被归类为背景或非背景站点。它还记录这些标签是直接来自官方来源还是由模型估算,并给出模型置信度与性能的摘要度量。总体来看,模型在更简单的城市—乡村划分上表现非常好,在更复杂的背景与受源影响的区分上表现尚可,这反映了在真实城市环境中第二类区分常常在视觉上和统计上更为微妙。作者不仅提供了数据集,还提供了输入影像和代码,以便他人复现或扩展他们的工作。
这如何帮助保护公共健康
对非专业读者而言,关键收获是该工作让在全球范围内提出和回答关于空气污染的可比问题变得容易得多。借助一个统一的站点类型框架,研究人员可以更好地比较不同部门在各地区对暴露的贡献,或评估政策变化在真实背景位置与交通热点处的污染变化。流行病学研究也能更可靠地将监测数据与疾病结局联系起来,因为能明确每个站点代表何种环境。环境机构还可以将该模型作为规划工具,检验拟建监测点是否可能采样到他们关心的条件。简言之,通过理顺描述监测站点何处及测量何物的“元数据”,本研究为全球空气质量分析与减少空气污染所致健康负担的努力奠定了更坚实的基础。
引用: Renna, S., Rodriguez-Pardo, C. & Aleluia Reis, L. A dataset of harmonized global air quality monitoring metadata. Sci Data 13, 466 (2026). https://doi.org/10.1038/s41597-026-06797-0
关键词: 空气质量监测, 颗粒物, 卫星数据, 机器学习, 环境健康