Clear Sky Science · fr
Un jeu de données harmonisé de métadonnées mondiales sur la surveillance de la qualité de l’air
Pourquoi des données d’air plus propres importent pour la vie quotidienne
La pollution de l’air par de très fines particules est l’un des principaux risques environnementaux pour la santé au niveau mondial, contribuant à des millions de décès prématurés chaque année. Les gouvernements s’appuient sur des milliers de stations de surveillance au sol pour savoir quand et où l’air est dangereux à respirer. Pourtant, ces stations sont décrites de façons très différentes selon les pays, ce qui rend étonnamment difficile la comparaison de la qualité de l’air entre régions ou l’évaluation de l’efficacité des politiques. Cette étude présente un nouveau jeu de données mondial et une méthode qui organisent cet ensemble disparate, aidant les chercheurs et les décideurs à mieux appréhender le panorama de l’exposition à la pollution de l’air.
Visualiser la mosaïque mondiale des stations de mesure
Les auteurs partent d’une idée simple mais puissante : la valeur des mesures de qualité de l’air dépend non seulement de ce qui est mesuré, mais aussi du lieu et du contexte. Une station au bord d’une autoroute très fréquentée raconte une histoire différente d’une station en zone rurale éloignée des sources majeures. Les agences classent habituellement les stations selon deux dimensions : si elles sont en zone urbaine ou rurale, et si elles mesurent des conditions de fond ou sont fortement influencées par des sources locales comme le trafic ou l’industrie. Cependant, il n’existe pas de système mondial cohérent pour attribuer ces étiquettes. En rassemblant des informations de réseaux officiels dans des régions comme l’Europe, les États-Unis, le Canada, le Japon, l’Afrique du Sud et d’autres, et en les combinant avec des positions issues d’une plateforme mondiale ouverte, l’équipe a constitué des métadonnées pour environ 15 000 sites de surveillance des particules dans 106 pays.
Utiliser images et chiffres pour comprendre chaque site
Pour harmoniser les étiquettes des stations entre des systèmes nationaux très différents, les chercheurs se sont appuyés sur des informations détaillées sur l’environnement immédiat de chaque capteur. Ils ont utilisé des cartes d’occupation du sol ultra‑fines issues de produits satellitaires de l’Agence spatiale européenne, qui indiquent si une zone est bâtie, boisée, cultivée, en eau ou d’un autre type, à une résolution d’environ 10 mètres. Autour de chaque station, ils ont découpé une petite image carrée d’environ deux kilomètres de côté, capturant routes voisines, quartiers, champs et zones industrielles. Ils ont ensuite ajouté plusieurs couches de données complémentaires : estimations des concentrations de particules fines et de monoxyde de carbone, densité de population, émissions des principaux polluants par secteur, ainsi que la localisation et le type de grandes installations industrielles telles que centrales à charbon, aciéries ou cimenteries.
Comment l’outil de classification fonctionne en coulisses
Avec ces entrées, l’équipe a entraîné des modèles avancés de reconnaissance d’image pour inférer l’étiquette la plus appropriée pour chaque station. Leur approche s’effectue en deux étapes. D’abord, le modèle apprend à distinguer les sites urbains des sites ruraux à partir d’exemples étiquetés et de tuiles satellitaires. Ensuite, il utilise ce savoir, avec toutes les autres données, pour décider si une station mesure l’air de fond général ou si elle est dominée par des sources locales. Pour tirer le meilleur parti des images et des nombres, ils ont conçu une architecture de fusion qui permet à un mécanisme d’attention d’évaluer, pour chaque station, dans quelle mesure se fier aux indices visuels versus aux indicateurs numériques comme les émissions ou la population. Cette méthode repose sur des architectures modernes de réseaux neuronaux développées à l’origine pour de larges jeux d’images et adaptées aux besoins spécifiques de la surveillance de la qualité de l’air.
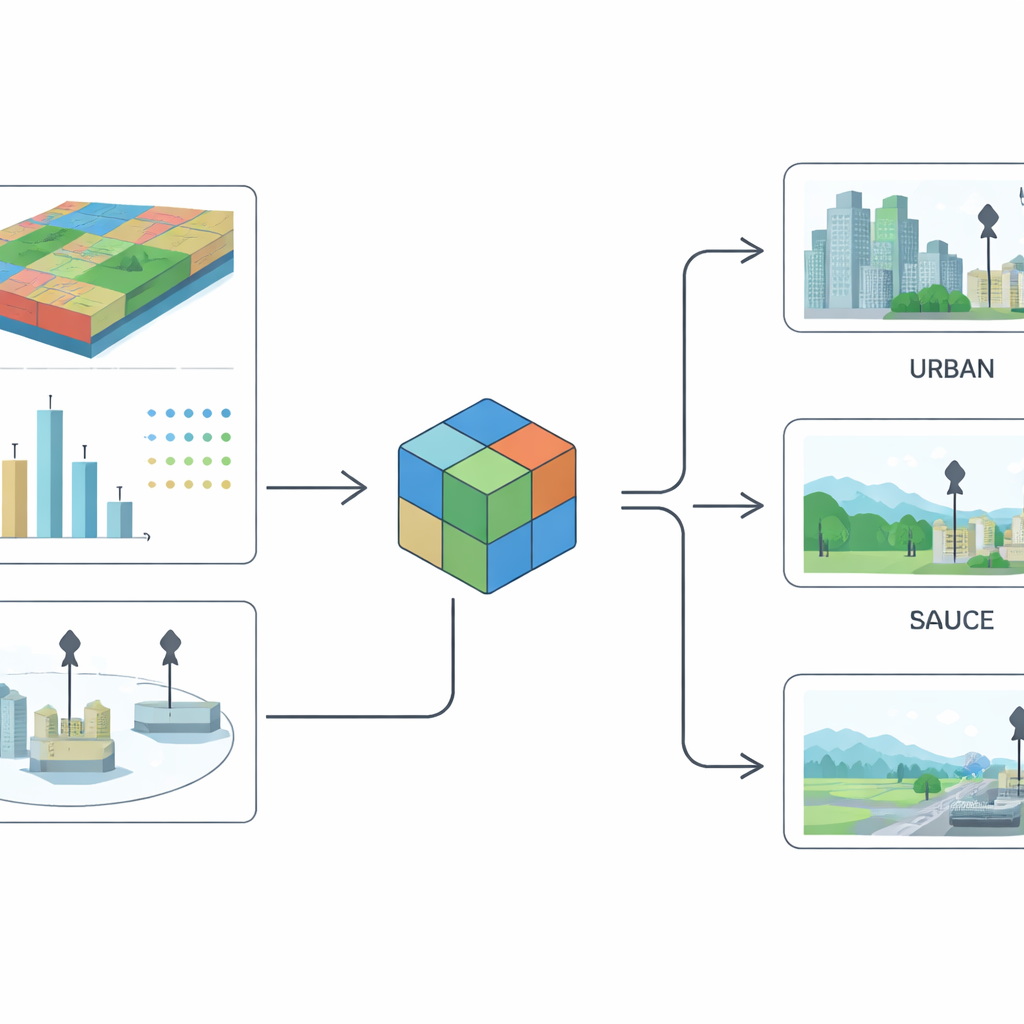
Ce que fournit le nouveau jeu de données mondial
Le résultat est Metair, un catalogue mondial harmonisé des stations de surveillance des particules. Pour chaque site, le jeu de données indique un identifiant, le pays, la localisation, l’altitude, le polluant mesuré, si le site est urbain ou rural, et s’il est classé comme fond ou non‑fond. Il précise également si ces étiquettes proviennent directement d’une source officielle ou ont été estimées par le modèle, ainsi que des mesures synthétiques de la confiance et des performances du modèle. Globalement, le modèle fonctionne très bien pour la séparation plus simple urbain–rural et de manière satisfaisante pour la distinction plus complexe fond versus influence locale, ce qui reflète la subtilité visuelle et statistique de ce second partage dans les villes réelles. Les auteurs fournissent non seulement le jeu de données, mais aussi les images d’entrée et le code pour que d’autres puissent reproduire ou étendre leur travail.
Comment cela aide à protéger la santé publique
Pour les non‑spécialistes, l’avantage principal est que ce travail facilite grandement la formulation et la réponse à des questions cohérentes sur la pollution de l’air dans le monde. Avec un cadre commun pour les types de stations, les chercheurs peuvent mieux comparer la contribution des différents secteurs à l’exposition selon les régions, ou comment les changements de politiques modifient la pollution aux emplacements véritablement de fond par rapport aux points chauds liés au trafic. Les études de santé peuvent plus fiablement relier les données de surveillance aux résultats sanitaires en sachant quel type d’environnement chaque station représente. Les agences environnementales peuvent aussi utiliser le modèle comme outil de planification, pour vérifier si de nouvelles stations proposées sont susceptibles d’échantillonner les conditions ciblées. En bref, en ordonnant les « métadonnées » qui décrivent où et quoi mesurent les stations, cette étude pose une base plus solide pour l’analyse mondiale de la qualité de l’air et pour les efforts visant à réduire le fardeau sanitaire de la pollution de l’air.
Citation: Renna, S., Rodriguez-Pardo, C. & Aleluia Reis, L. A dataset of harmonized global air quality monitoring metadata. Sci Data 13, 466 (2026). https://doi.org/10.1038/s41597-026-06797-0
Mots-clés: surveillance de la qualité de l’air, matières particulaires, données satellitaires, apprentissage automatique, santé environnementale