Clear Sky Science · de
Ein Datensatz harmonisierter globaler Metadaten zur Luftqualitätsüberwachung
Warum sauberere Luftdaten im Alltag wichtig sind
Luftverschmutzung durch winzige Partikel in der Luft gehört zu den weltweit führenden umweltbedingten Gesundheitsrisiken und trägt jährlich zu Millionen vorzeitiger Todesfälle bei. Regierungen verlassen sich auf Tausende bodengestützte Messstationen, um zu wissen, wann und wo die Luft nicht sicher zum Atmen ist. Diese Stationen werden jedoch von Land zu Land sehr unterschiedlich beschrieben, was den Vergleich der Luftqualität zwischen Regionen oder die Bewertung der Wirksamkeit von Maßnahmen überraschend erschwert. Diese Studie stellt einen neuen globalen Datensatz und eine Methode vor, die dieses Flickwerk ordnen und Wissenschaftlern sowie politischen Entscheidungsträgern helfen, das Gesamtbild der Belastung durch Luftverschmutzung klarer zu sehen.
Das globale Flickwerk von Messstationen erkennen
Die Autoren gehen von einer einfachen, aber kraftvollen Idee aus: Der Wert von Luftqualitätsmessungen hängt nicht nur davon ab, was gemessen wird, sondern auch davon, wo und warum. Eine Station neben einer stark befahrenen Straße erzählt eine andere Geschichte als eine im ländlichen Raum fernab großer Emissionsquellen. Behörden kennzeichnen Stationen üblicherweise entlang zweier Dimensionen: ob sie in einem städtischen oder ländlichen Gebiet liegen und ob sie Hintergrundbedingungen erfassen oder stark von lokalen Quellen wie Verkehr oder Industrie beeinflusst werden. Es gibt jedoch kein einheitliches weltweites System zur Vergabe dieser Labels. Indem das Team Informationen aus offiziellen Netzen in Regionen wie Europa, den Vereinigten Staaten, Kanada, Japan, Südafrika und anderen sammelte und mit Standorten aus einer offenen globalen Plattform kombinierte, stellten sie Metadaten für etwa 15.000 Feinstaub-Messstellen in 106 Ländern zusammen.
Bilder und Zahlen nutzen, um jeden Standort zu verstehen
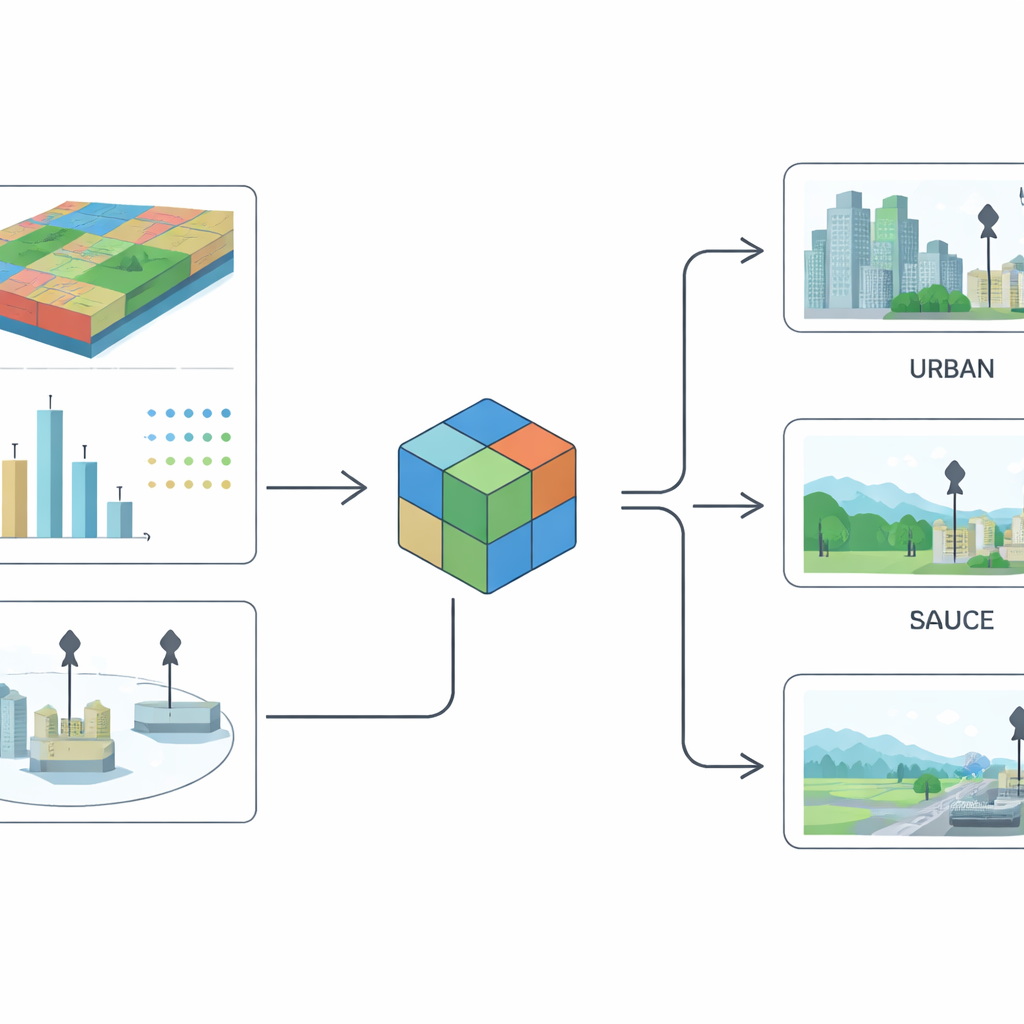
Um Stationsetiketten über sehr unterschiedliche nationale Systeme hinweg zu harmonisieren, griffen die Forschenden auf detaillierte Informationen zur Umgebung jeder Messstelle zurück. Sie nutzten ultrafeine Landbedeckungskarten aus Satellitenprodukten der Europäischen Weltraumorganisation, die beschreiben, ob ein Gebiet bebaut ist, von Bäumen, Ackerland, Wasser oder anderen Flächen bedeckt ist – mit einer Auflösung von etwa 10 Metern. Rund um jede Station schnitten sie ein kleines quadratisches Bild von ungefähr zwei Kilometern Kantenlänge aus, das nahegelegene Straßen, Wohnviertel, Feldflächen und Industriegebiete einfing. Zusätzlich fügten sie mehrere Schichten unterstützender Daten hinzu: Schätzungen von Feinstaub- und Kohlenmonoxidkonzentrationen, Bevölkerungsdichte, Emissionen wichtiger Schadstoffe aus verschiedenen Sektoren sowie Standorte und Typen großer Industrieanlagen wie Kohlekraftwerke, Stahlwerke und Zementfabriken.
Wie das Klassifikationswerkzeug im Kern arbeitet
Mit diesen Eingaben trainierte das Team fortgeschrittene Bilderkennungsmodelle, um abzuleiten, wie jede Station etikettiert werden sollte. Ihr Ansatz arbeitet in zwei Stufen. Zuerst lernt das Modell anhand gelabelter Beispiele und Satellitenkacheln, städtische von ländlichen Standorten zu unterscheiden. Anschließend nutzt es dieses Wissen zusammen mit allen anderen Daten, um zu entscheiden, ob eine Station allgemeine Hintergrundluft misst oder von nahegelegenen Quellen dominiert wird. Um das Beste aus Bildern und Zahlen herauszuholen, entwarfen sie eine Fusionsarchitektur, die einen Aufmerksamkeitsmechanismus erlaubt, für jede Station abzuwägen, inwieweit visuelle Hinweise gegenüber numerischen Indikatoren wie Emissionen oder Bevölkerung zu vertrauen ist. Diese Methode baut auf modernen neuronalen Netzwerkarchitekturen auf, die ursprünglich für große Bilddatensätze entwickelt und an die spezifischen Anforderungen der Luftqualitätsüberwachung angepasst wurden.
Was der neue globale Datensatz bietet
Das Ergebnis ist Metair, ein harmonisierter globaler Katalog von Feinstaub-Messstationen. Für jede Station listet der Datensatz eine Kennung, das Land, den Standort, die Höhe, den gemessenen Schadstoff, ob die Station städtisch oder ländlich ist und ob sie als Hintergrund- oder Nicht-Hintergrundstation klassifiziert wird. Er verzeichnet außerdem, ob diese Labels direkt aus einer offiziellen Quelle stammen oder vom Modell geschätzt wurden, zusammen mit zusammenfassenden Maßen zur Vertrauenswürdigkeit und Leistung des Modells. Insgesamt liefert das Modell sehr gute Ergebnisse für die einfachere Unterscheidung städtisch–ländlich und angemessene Ergebnisse für die komplexere Trennung Hintergrund versus quellenbeeinflusst, was widerspiegelt, wie visuell und statistisch subtil die zweite Unterscheidung in realen Städten sein kann. Die Autoren stellen nicht nur den Datensatz, sondern auch die Eingangsabbildungen und den Code bereit, sodass andere ihre Arbeit reproduzieren oder erweitern können.
Wie dies den Schutz der öffentlichen Gesundheit unterstützt
Für Nichtfachleute liegt die wichtigste Rendite darin, dass diese Arbeit das Stellen und Beantworten konsistenter Fragen zur Luftverschmutzung weltweit deutlich erleichtert. Mit einem gemeinsamen Rahmen für Stationstypen können Forschende besser vergleichen, wie stark verschiedene Sektoren zu Belastungen in unterschiedlichen Regionen beitragen oder wie sich politische Veränderungen an tatsächlichen Hintergrundstandorten gegenüber Verkehrshotspots auswirken. Gesundheitsstudien können Überwachungsdaten verlässlicher mit Krankheitsfolgen verknüpfen, wenn klar ist, welche Art von Umgebung jede Station repräsentiert. Umweltbehörden können das Modell auch als Planungsinstrument nutzen, um zu prüfen, ob vorgeschlagene neue Messstellen voraussichtlich die Bedingungen erfassen, die sie interessieren. Kurz: Indem die Studie die „Metadaten“, die beschreiben, wo und was Stationen messen, systematisiert, schafft sie eine solidere Grundlage für globale Luftqualitätsanalysen und für Maßnahmen zur Verringerung der gesundheitlichen Belastung durch verschmutzte Luft.
Zitation: Renna, S., Rodriguez-Pardo, C. & Aleluia Reis, L. A dataset of harmonized global air quality monitoring metadata. Sci Data 13, 466 (2026). https://doi.org/10.1038/s41597-026-06797-0
Schlüsselwörter: Luftqualitätsüberwachung, Partikelbelastung, Satellitendaten, Maschinelles Lernen, Umweltgesundheit