Clear Sky Science · zh
针对忆阻交叉阵列的超线性容量联想记忆的硬件自适应学习算法
为何更智能的存储硬件至关重要
想象一下扫一眼模糊、半擦拭的电话号码却仍能正确拨号。我们的脑子常常能填补这类缺失信息,但今天的计算机很难高效做到这一点。本文探讨了一种新的电子记忆,其能够从噪声提示中回忆出完整模式——更接近大脑的工作方式——同时消耗更少能量。通过同时重新设计学习规则和硬件,研究人员展示了这些系统可以存储比预期更多的记忆,且在许多元件失效时仍能继续工作。
从类脑回忆到电子记忆
几十年前,科学家提出了“联想记忆”,它像大脑一样,当只给出部分或损坏的版本时,能够恢复出完整的存储模式。一种流行的数学模型是霍普菲尔德神经网络,其行为类似一片多谷地形:每个谷代表一个存储记忆,带噪输入会沿坡滚入最近的那个谷。然而在传统的数字芯片上,这一过程既慢又耗能,因为数据必须在独立的处理器和存储单元之间来回传输。作者改而依赖忆阻交叉阵列——由微小电子器件构成的网格,既能存储信息又能就地执行计算——这承诺了大规模并行和更低的能耗。
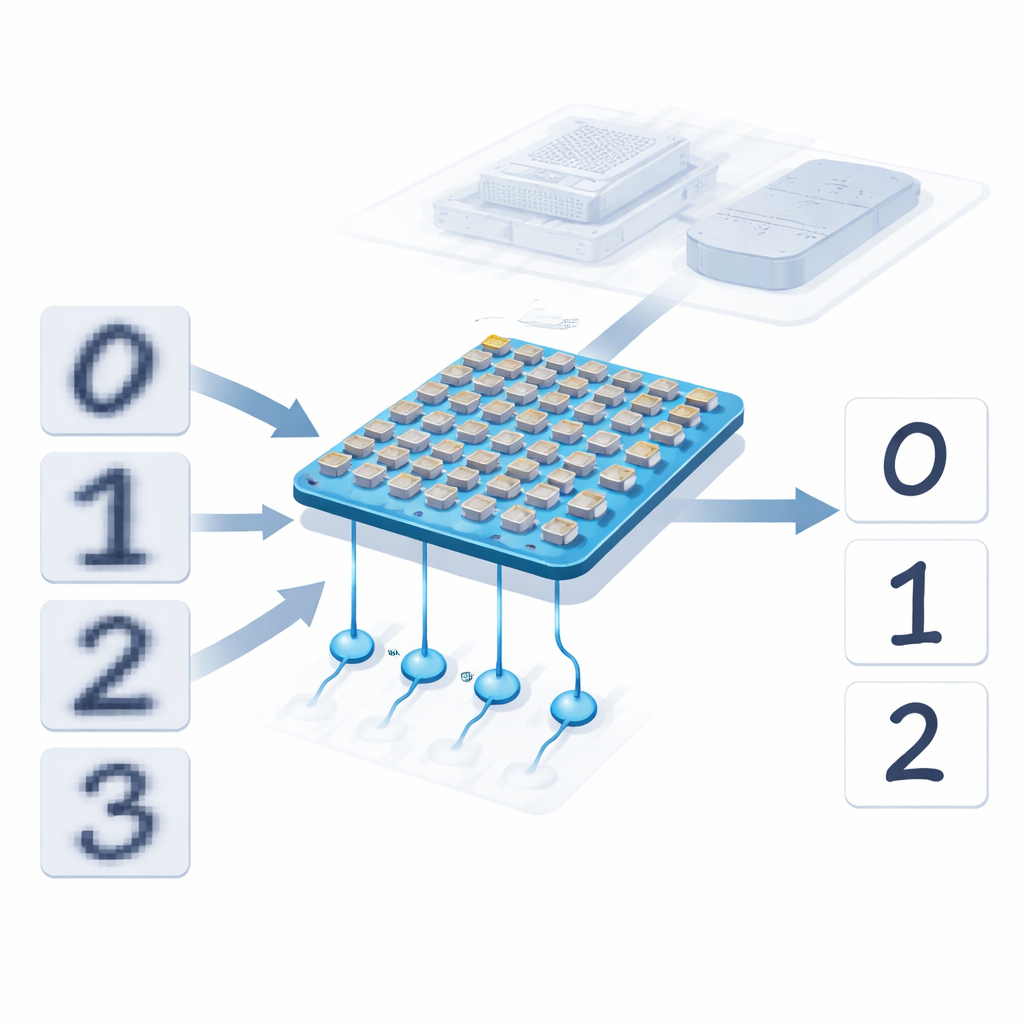
教会有缺陷的硬件与自身瑕疵共处
真实的忆阻器远非完美。有些会卡住再也无法改变其电导,而另一些在每次编程时会略有差异。以往的设计把学习视为纯数学的练习,忽略了这些真实世界的特性,然后试图将计算出的权重复制到硬件中。新工作颠覆了这一方法:学习算法被设计为“硬件自适应”,即在训练时使用对实际芯片的详细模型,包括哪些器件被卡住以及它们可靠可达的电导范围。在训练过程中,故障器件被显式屏蔽,其余器件被调整,从而使整个网络在给定噪声提示时仍能收敛到正确的记忆。
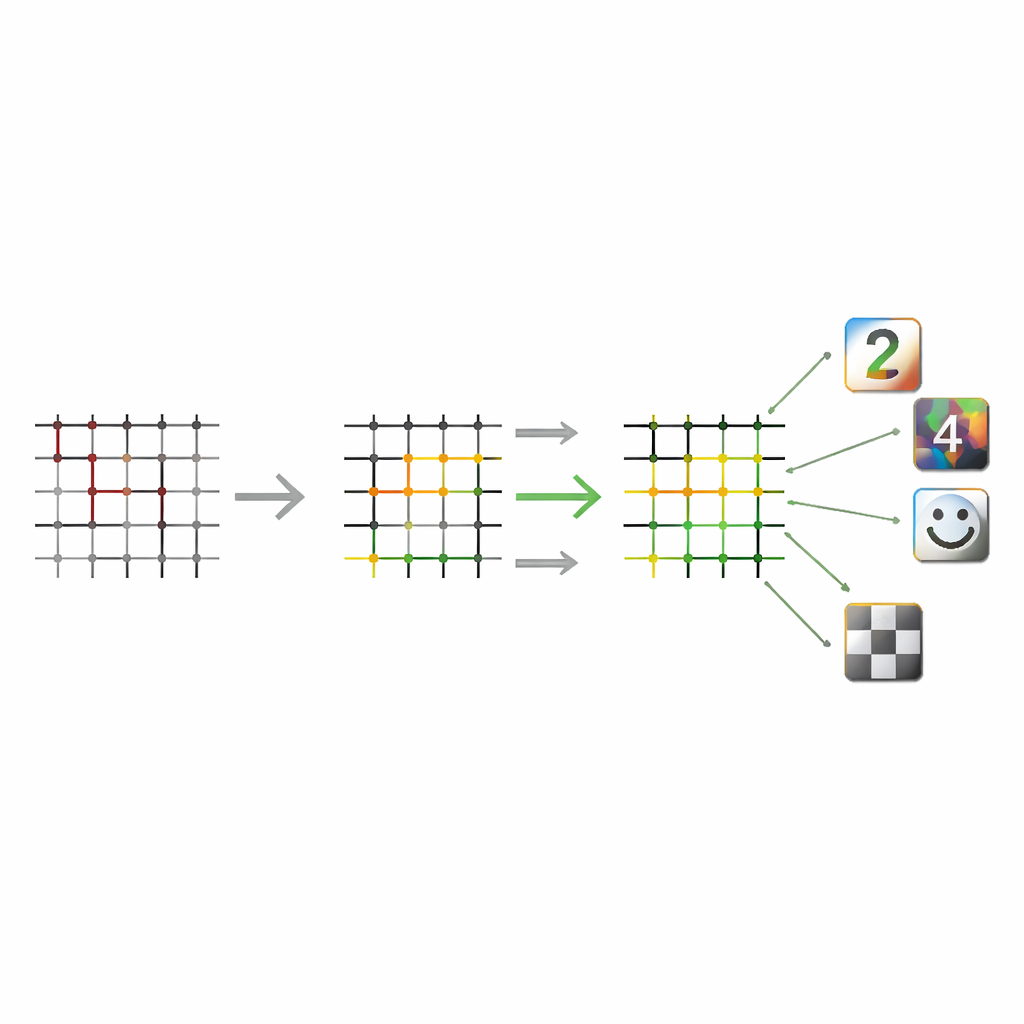
通过分层网络存储更多记忆
经典霍普菲尔德网络使用单层连接,已知只能存储与其规模成比例数量的模式。作者将其硬件感知的学习方法扩展到多层网络——在输入与输出之间加入隐藏层——并在忆阻交叉阵列上实现。这些额外层就像一种智能压缩阶段:对于手写数字等有结构的数据,系统可以存储的模式数随输入单元数增长得比线性更快,作者称之为超线性容量。在对下采样的 MNIST 数字图像的测试中,多层设计不仅存储了更多模式,而且相比单层对等方案使用了显著更少的忆阻器件,为在不导致硬件成本爆炸的情况下扩展提供了明确路径。
处理灰度而不仅黑白
早期的大多数联想记忆仅能处理简单的开/关模式,而现实世界的数据——图像、声音、传感器信号——是连续变化的。通过将突变的“符号”激活替换为平滑的“tanh”函数,并将其与多层、硬件自适应训练相结合,作者展示了同一忆阻系统可以可靠回忆连续值模式。即便输入被严重噪声破坏,网络的迭代动力学也会将其拉回到正确的存储模式。对于这些连续情况,系统能保持的记忆数同样以超过线性的速率随规模增长,表明该架构的优势超越了二元玩具示例。
实践中的速度、效率与鲁棒性
由于忆阻交叉阵列能够并行执行许多运算,研究人员一次更新所有神经元状态,而非像传统方案那样逐个更新。在一个 64 神经元原型上,这种同步更新将处理时间约缩短了千倍,并相比先前的异步方法将能耗降低了数倍。关键是,即便有多达一半的器件永久卡住,系统仍保持高质量回忆,并且在现实的编程噪声下性能几乎不变。总体而言,这项工作为类脑记忆提供了实用蓝图:快速、节能、容错并能存储丰富的连续模式——使硬件朝着具备生物大脑联想能力的方向更进一步。
引用: He, C., Jiang, M., Shan, K. et al. A hardware-adaptive learning algorithm for superlinear-capacity associative memory on memristor crossbars. Nat Commun 17, 3096 (2026). https://doi.org/10.1038/s41467-026-69958-0
关键词: 联想记忆, 忆阻交叉阵列, 类脑硬件, 霍普菲尔德网络, 内存计算