Clear Sky Science · it
Un algoritmo di apprendimento adattivo all’hardware per memoria associativa a capacità superlineare su crossbar di memristori
Perché l’hardware di memoria più intelligente conta
Immaginate di guardare un numero di telefono sfocato e mezzo cancellato e riuscire comunque a comporlo correttamente. I nostri cervelli riempiono abitualmente informazioni mancanti in questo modo, ma i computer odierni faticano a farlo in modo efficiente. Questo articolo esplora un nuovo tipo di memoria elettronica in grado di richiamare schemi completi da indizi rumorosi—più simile a come funziona il cervello—usando molta meno energia. Ridisegnando sia le regole di apprendimento sia l’hardware, i ricercatori mostrano che questi sistemi possono memorizzare più ricordi del previsto e continuare a funzionare anche quando molti dei loro componenti sono difettosi.
Dalla richiamata di tipo biologico alla memoria elettronica
Decenni fa gli scienziati proposero le “memorie associative” che, come il cervello, possono recuperare un pattern memorizzato completo quando viene fornita solo una versione parziale o corrotta. Un modello matematico popolare per questo è la rete neurale di Hopfield, che si comporta come un paesaggio di valli: ogni valle rappresenta una memoria memorizzata e un input rumoroso rotola giù verso quella più vicina. Sui processori digitali standard, però, questo processo è lento e dispendioso in termini energetici, perché i dati devono transitare avanti e indietro tra unità di calcolo e memoria separate. Gli autori invece si affidano ai crossbar di memristori—griglie di minuscoli dispositivi elettronici che memorizzano informazioni e allo stesso tempo eseguono calcoli in loco—promettendo enorme parallelismo e consumi molto ridotti.
Insegnare all’hardware imperfetto a lavorare con i propri difetti
I memristori reali sono lontani dalla perfezione. Alcuni si bloccano e non cambiano mai più la loro conduttanza elettrica, mentre altri variano leggermente ogni volta che vengono programmati. I progetti precedenti trattavano l’apprendimento come un esercizio puramente matematico, ignorando questi difetti reali e poi cercando di trasferire i pesi calcolati nell’hardware in un secondo momento. Il nuovo lavoro capovolge questo approccio: l’algoritmo di apprendimento è reso “adattivo all’hardware”, cioè viene addestrato usando un modello dettagliato del chip reale, inclusi quali dispositivi sono bloccati e quale intervallo di conduttanza possono raggiungere in modo affidabile. Durante l’addestramento, i dispositivi difettosi vengono esplicitamente mascherati e quelli rimanenti vengono regolati in modo che l’intera rete converga comunque verso le memorie corrette quando riceve indizi rumorosi.
Memorizzare più ricordi con reti stratificate
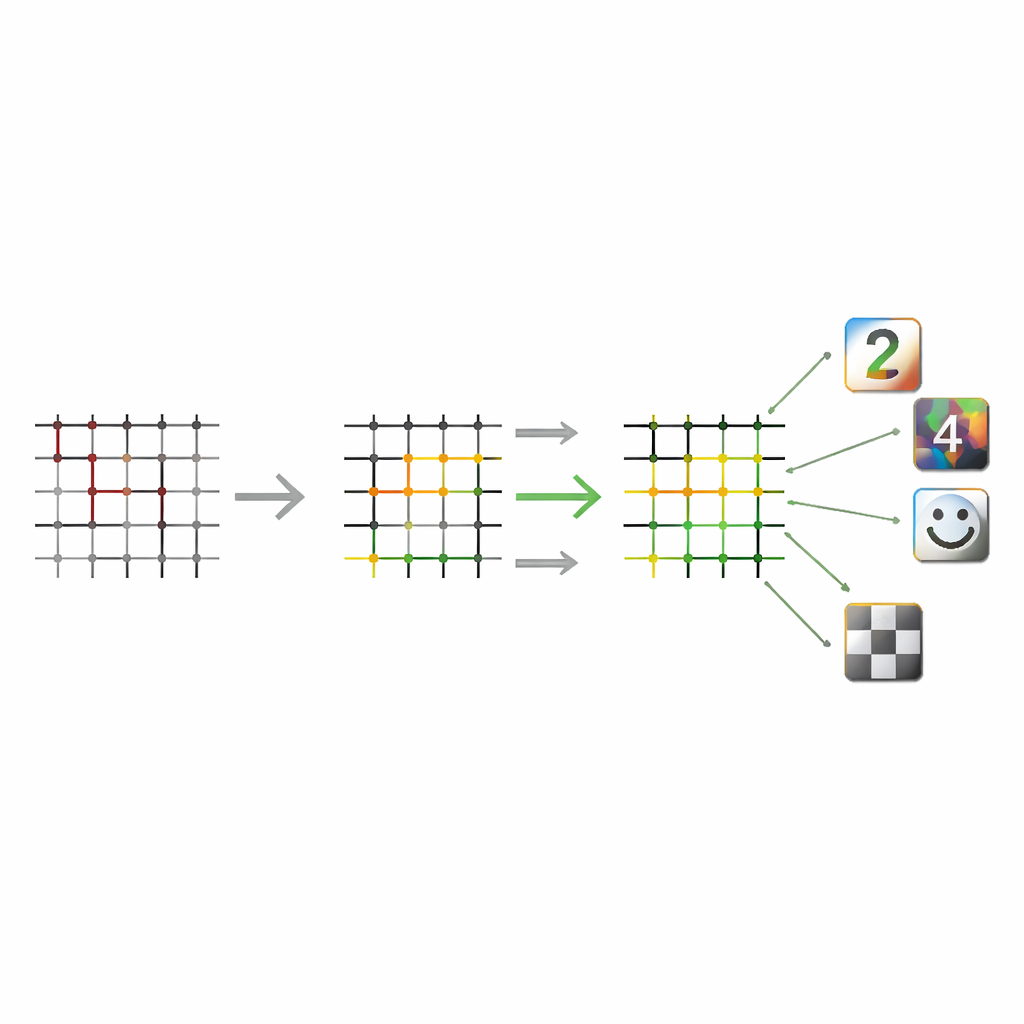
Le reti di Hopfield classiche usano un singolo strato di connessioni e sono note per memorizzare solo un numero di pattern proporzionale alla loro dimensione. Gli autori estendono il loro metodo di apprendimento consapevole dell’hardware a reti multilayer—aggiungendo strati nascosti tra input e output—implementate su crossbar di memristori. Questi strati extra agiscono come una fase di compressione intelligente: per dati strutturati come cifre scritte a mano, il sistema può memorizzare un numero di pattern che cresce più rapidamente della proporzionalità con il numero di unità di input, un comportamento che gli autori descrivono come capacità superlineare. Nei test con immagini di cifre MNIST ridimensionate, il progetto multilayer non solo ha memorizzato più pattern ma lo ha fatto utilizzando drasticamente meno dispositivi memristor rispetto alla controparte a singolo strato, offrendo un percorso chiaro per scalare senza un’esplosione dei costi hardware.
Gestire sfumature di grigio, non solo bianco e nero
La maggior parte delle memorie associative precedenti funzionava solo con pattern semplici acceso/spento, mentre i dati del mondo reale—immagini, suoni, segnali di sensori—variano in modo continuo. Sostituendo l’attivazione brusca “sign” con una funzione continua “tanh” e combinandola con il loro addestramento multilayer adattivo all’hardware, gli autori mostrano che lo stesso sistema a memristor può richiamare in modo affidabile pattern a valori continui. Anche quando l’input è fortemente corrotto dal rumore, la dinamica iterativa della rete lo riporta verso il pattern memorizzato corretto. Per questi casi continui, il numero di memorie che il sistema può contenere cresce anch’esso più che linearmente con la dimensione, indicando che i benefici dell’architettura vanno oltre esempi binari semplificati.
Velocità, efficienza e resilienza nella pratica
Poiché i crossbar di memristori eseguono molte operazioni in parallelo, i ricercatori aggiornano tutti gli stati neuronali contemporaneamente, invece che uno alla volta come negli schemi tradizionali. Su un prototipo a 64 neuroni, questo aggiornamento sincrono riduce il tempo di elaborazione di circa mille volte e taglia il consumo energetico di diversi fattori rispetto ad approcci asincroni precedenti. In modo cruciale, il sistema mantiene un’elevata qualità di richiamo anche quando fino a metà dei dispositivi è permanentemente bloccata, e le sue prestazioni cambiano poco in presenza di rumore di programmazione realistico. Nel complesso, il lavoro presenta un progetto pratico per memorie ispirate al cervello che sono veloci, a basso consumo, tolleranti ai difetti e capaci di memorizzare pattern ricchi e continui—avvicinando l’hardware al potere associativo dei cervelli biologici.
Citazione: He, C., Jiang, M., Shan, K. et al. A hardware-adaptive learning algorithm for superlinear-capacity associative memory on memristor crossbars. Nat Commun 17, 3096 (2026). https://doi.org/10.1038/s41467-026-69958-0
Parole chiave: memoria associativa, crossbar di memristori, hardware neuromorfico, rete di Hopfield, calcolo in memoria