Clear Sky Science · tr
Davranışsal bir biyometrik olarak dilbilgisi: yazarlık doğrulaması için bilişsel olarak motive edilmiş dilbilgisi modellerinin kullanımı
Yazma Tarzınızın Parmak İzinize Benzemesinin Nedeni
Her yazdığınızda—ister e-posta, ister bir inceleme, ister bir sosyal medya gönderisi olsun—muhtemenden daha fazlasını açığa vurursunuz. Seçtiğiniz konuların ötesinde, küçük bağlaçlar ve noktalama işaretleri gibi cümlenizin temel taşları kişisel düzeyde şaşırtıcı derecede belirleyici desenler oluşturur. Bu makale, bu desenleri iki metnin aynı kişi tarafından yazılıp yazılmadığını belirlemek için kullanmanın yeni bir yolunu inceliyor; bunun hukuka, güvenliğe ve dilin zihinde nasıl yer aldığına dair anlayışımıza etkileri olabilir.
Soruşturmacılar Kimin Ne Yazdığını Nasıl Belirliyor
Dijital metin adli bilimlerinde uzmanlar sık sık şu tür sorularla karşılaşır: Aynı kişi bu tehdit içeren e-postayı ve bu önceki mesajı mı yazdı? İki çevrimiçi hesap aynı birey tarafından mı yönetiliyor? Yazarlık sorunlarına geleneksel yaklaşımlar üç gruba ayrılır. Bazıları yalnızca bilinen yazardan gelen metinleri şüpheli metinle karşılaştırır. Diğerleri eşleşen ve eşleşmeyen örnek çiftleri üzerinde bir sınıflandırıcı eğitir. Bu makalenin odaklandığı üçüncü grup ise, belirli bir yazma tarzının birçok başka yazara kıyasla ne kadar alışılmadık olduğunu anlamak için dış bir “referans nüfusu” getirir. Son on yılda, özellikle karakter parçacıklarına ve derin sinir ağlarına dayanan güçlü fakat şeffaf olmayan teknikler paylaşılan görevlerde ve kıyaslamalarda hakim oldu. Ancak bunlar yavaş olabilir, yorumlaması zor olabilir ve bazen bir yazarın gerçek üslup alışkanlıklarından çok konu tarafından yönlendirilebilir.
Zihindeki İfadelerden Alışkanlıklara
Yazarlar yeni yöntemlerini Dil Bilişbilimi (Cognitive Linguistics) alanına dayandırırlar; bu alan dilbilgisini katı kurallar kümesi olarak değil, öğrenilmiş desenlerin bir ağı olarak ele alır. Bu görüşe göre beynimiz sık tekrar edilen dizileri—“of the” ya da “I don’t know” gibi—otomatik hale gelen birimler halinde “parçalar”. Bu birimler sabit ifadelerden esnek şablonlara ve daha soyut yapılara uzanan bir süreklilik üzerinde yer alır. Deneyimlerimiz ve okuma geçmişimiz farklı olduğu için, zihnimizde derinlemesine yerleşen özgül kombinasyonlar da farklı olur. Bu “dilsel bireysellik ilkesi”, iki kişinin tam olarak aynı içsel dilbilgisine sahip olmadığını öne sürer. Makale, bu bireyselleşmiş dilbilgisinin el yazısı veya yürüyüş biçimi ruhunda bir tür davranışsal biyometrik olarak işlev görebileceğini savunur.
Gizli Dilbilgisini Ölçülebilir Bir Sinyale Dönüştürmek
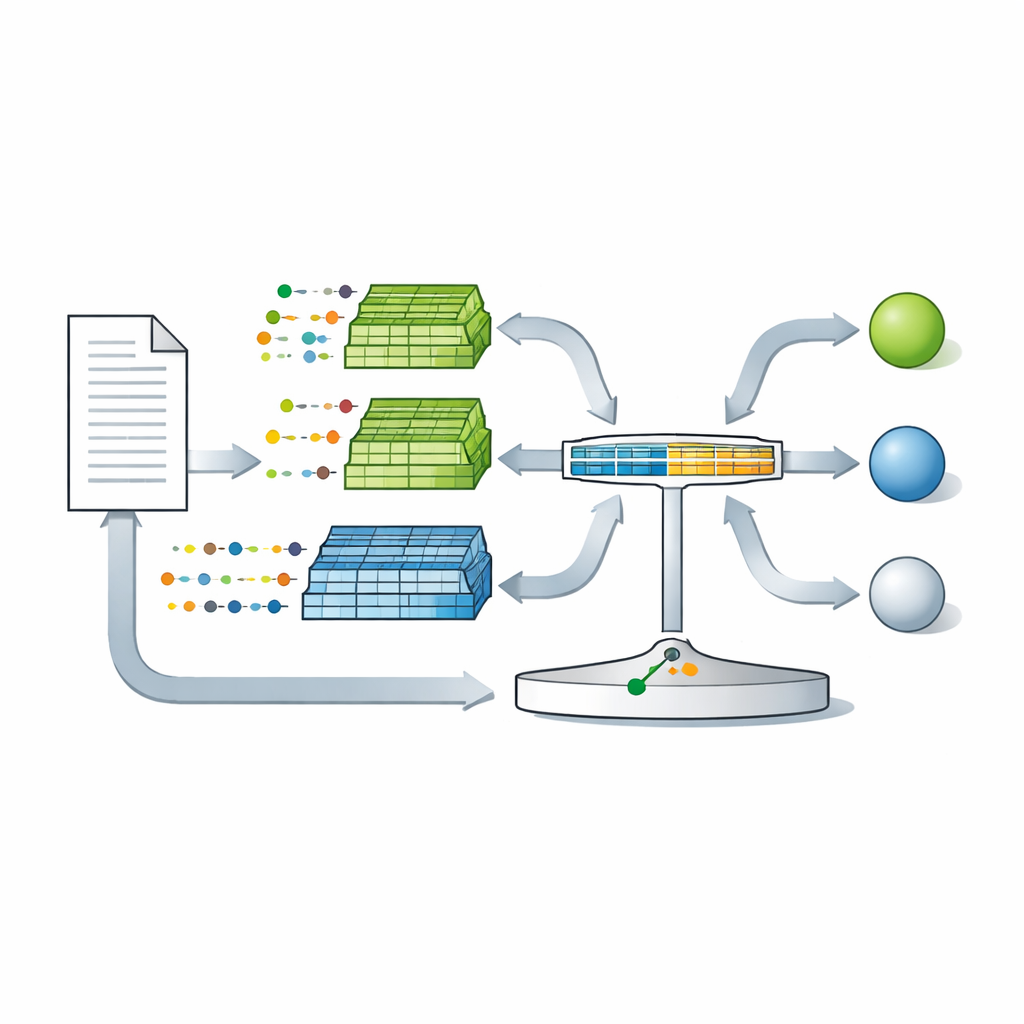
Bu kurama dayanarak, yazarlar LambdaG adını verdikleri; konuları ve içerik sözcüklerini kasıtlı olarak görmezden gelen bir yazar dilbilgisi modelleme yöntemi sunar. Önce metinler, yalnızca işlevsel sözcükleri, noktalama işaretlerini ve birkaç soyut kategoriyi tutan bir filtreden geçirilir; isimler ve özel içerik temizlenir. Bu filtrelenmiş metinler cümlelere bölünür ve her küçük dilbilgisel belirtecin o yazar için ne kadar olası olduğunu öğrenen istatistiksel bir “n-gram” modeline verilir. Karşılaştırma nüfusunun rolünü oynayan, birçok diğer yazardan eğitilmiş ikinci bir model seti bulunur. Şüpheli bir metindeki her belirteç için LambdaG sorar: bu belirteç bu bağlamda aday yazar için referans yazarlara kıyasla ne kadar daha doğal? Bu karşılaştırmalar, adayla benzerliği ve daha geniş nüfustaki nadirliği yansıtan tek bir puanda birleştirilir. Basit bir lojistik regresyon daha sonra bu puanı adli durumlarda dereceli bir kanıt gücü gibi yorumlanabilecek şekilde kalibre eder.
Yeni Yöntem Ne Kadar İyi İş Görüyor
Yazarlar LambdaG’yi e-postalar, sohbet kayıtları, incelemeler, haber makaleleri ve daha fazlasını taklit eden, genellikle görece kısa metinlere sahip gerçek dünya durumlarını andıran on iki veri kümesi üzerinde test eder. Etkili İmpostors Method (Sahtekarlar Yöntemi), sıkıştırma tabanlı bir yaklaşım, konu-bağımsız bir topluluk ve birkaç derin sinir sistemi dahil olmak üzere yedi güçlü temel yöntemle karşılaştırırlar. Doğruluk ve ROC eğrisi altındaki alan gibi ölçütler boyunca LambdaG çoğu veri kümesinde birinci, bazılarında ise ikinci sırada yer alır ve genellikle bu modellerin tam içeriği kullanmalarına izin verildiğinde bile sinirsel modelleri geride bırakır. Ayrıca LambdaG, referans nüfusundaki değişikliklere karşı önceki yöntemlere göre daha az hassastır: referans metinler çok farklı bir türden geldiğinde performans düşer, ancak işe yaramaz hale gelecek kadar düşmez. LambdaG’nin puanı cümle cümle ve hatta belirteç belirteç ayrıştırılabildiği için, analistler bir metinde hangi desenlerin kararda en etkili olduğunu görsel olarak vurgulayan ısı haritaları üretebilir.
Kimlik ve Mahremiyet Açısından Anlamı
Araştırma, bir bireyin dilbilgisinin—küçük sözcükleri, noktalama işaretlerini ve yineleyen desenleri alışkanlıkla nasıl ördüğü—bir davranışsal biyometrik gibi davrandığını sonucuna varır. Sadece bin ila iki bin kelime kadar kısa bir metinde bile LambdaG genellikle bir kişiyi başkalarından güçlü biçimde ayıran kendine özgü dizileri ortaya çıkarabilir ve yazarlar bu birimlerin çoğunun yazarlar tarafından bilinçli olarak kontrol edilmediğini savunur. Bu, adli çalışmalar için açık faydalar sağlar: göreli olarak basit, ampirik olarak güçlü ve iyi gelişmiş bir dilbilim teorisine dayanarak gerekçesini mahkemede açıklamayı kolaylaştıran bir yöntem sunar. Aynı zamanda mahremiyet açısından önemli bir noktayı vurgular: günlük yazımız, ne dediğimizde değil, zihnimizin bunu söylemeyi nasıl öğrendiğinde köklenen, istikrarlı ve tanımlanabilir bir imzayı sessice taşır.
Atıf: Nini, A., Halvani, O., Graner, L. et al. Grammar as a behavioral biometric: using cognitively motivated grammar models for authorship verification. Humanit Soc Sci Commun 13, 455 (2026). https://doi.org/10.1057/s41599-025-06340-3
Anahtar kelimeler: yazarlık doğrulaması, stilometri, adli dilbilim, davranışsal biyometri, dilbilgisi modelleme