Clear Sky Science · ru
Грамматика как поведенческий биометрический признак: использование когнитивно мотивированных моделей грамматики для верификации авторства
Почему ваш стиль письма похож на отпечаток пальца
Каждый раз, когда вы пишете — будь то письмо по электронной почте, отзыв или пост в соцсетях — вы раскрываете о себе больше, чем думаете. Помимо тем, которые вы выбираете, крошечные строительные блоки ваших предложений, такие как служебные слова и пунктуация, образуют паттерны, которые удивительно индивидуальны. В этой статье рассматривается новый способ использования этих паттернов для выяснения, были ли два текста написаны одним и тем же человеком, с возможными последствиями для права, безопасности и нашего понимания того, как язык обитает в уме.
Как следователи решают, кто что написал
В цифровой текстовой криминалистике эксперты часто сталкиваются с вопросами вроде: один и тот же человек написал это угрожающее письмо и предыдущее сообщение? Управляют ли два онлайн-аккаунта одним человеком? Традиционные подходы к этим задачам по проверке авторства делятся на три группы. Некоторые сравнивают только тексты известного автора с оспариваемым текстом. Другие обучают классификатор на множестве примеров совпадающих и несовпадающих пар. Третья группа, на которой сосредоточена эта работа, привлекает внешнее «референтное население» текстов, чтобы понять, насколько необычен тот или иной стиль письма по сравнению со многими другими авторами. За последнее десятилетие доминировали мощные, но непрозрачные методы — особенно те, что основаны на фрагментах символов и глубоких нейросетях. Однако они могут быть медленными, трудными для интерпретации и иногда больше зависеть от темы, чем от истинных стилевых привычек автора.
От фраз к привычкам в уме
Авторы основывают свой новый метод на когнитивной лингвистике — направлении, которое рассматривает грамматику не как набор жестких правил, а как сеть усвоенных паттернов. Согласно этой точке зрения, наш мозг «собирает» часто повторяющиеся последовательности — например «of the» или «I don’t know» — в единицы, которые становятся автоматически выполняемыми, подобно отработанным танцевальным шагам. Эти единицы лежат на континууме от фиксированных выражений до гибких шаблонов и более абстрактных структур. Поскольку наш опыт и история чтения различны, конкретные комбинации, которые глубоко укореняются в уме, тоже различаются. Этот «принцип лингвистической индивидуальности» предполагает, что между людьми нет двух совершенно одинаковых внутренних грамматик. В статье утверждается, что такая индивидуализированная грамматика может выступать в роли поведенческой биометрии, сходной по духу с почерком или походкой.
Как превратить скрытую грамматику в измеримый сигнал
Опираясь на эту теорию, авторы представляют LambdaG — метод, который моделирует грамматику автора, сознательно игнорируя темы и содержательные слова. Сначала тексты пропускают через фильтр, который оставляет только служебные слова, пунктуацию и несколько абстрактных категорий, удаляя имена и конкретный контент. Отфильтрованные тексты разбивают на предложения и подают в статистическую n-граммную модель, которая учится тому, насколько вероятна каждая небольшая последовательность грамматических токенов для данного автора. Вторая группа моделей, обученная на многих других писателях, выполняет роль популяции сравнения. Для каждого токена в оспариваемом тексте LambdaG спрашивает: насколько более естественен этот токен в этом контексте для проверяемого автора по сравнению с референтными авторами? Эти сравнения объединяются в единую оценку, отражающую как сходство с кандидатом, так и редкость в широкой популяции. Простая логистическая регрессия затем калибрует эту оценку, чтобы её можно было интерпретировать как градуированную силу доказательства в судебно-экспертных условиях.
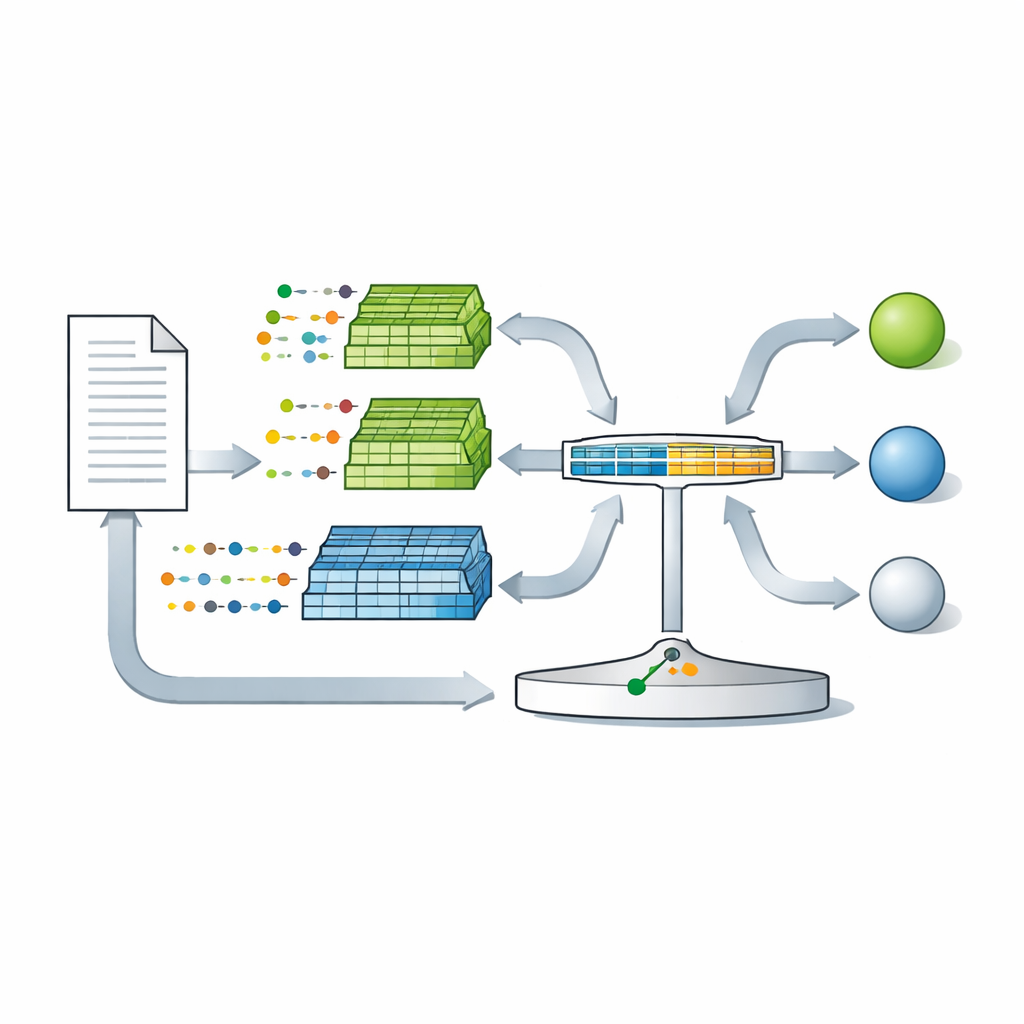
Насколько хорошо новый метод работает на практике
Авторы проверяют LambdaG на двенадцати наборах данных, моделирующих реальные ситуации: электронные письма, чаты, отзывы, новостные статьи и другие жанры, часто с относительно короткими текстами. Они сравнивают метод с семью сильными базовыми подходами, включая влиятельный метод «Самозванцев» (Impostors Method), метод на основе сжатия, ансамбль, нейтральный к теме, и несколько глубоких нейросетевых систем. По метрикам точности и площади под ROC-кривой LambdaG занимает первое место на большинстве наборов данных и второе место на нескольких других, часто превосходя нейросетевые модели даже при том, что те имеют доступ к полному содержанию. Метод также менее чувствителен, чем ранние подходы, к изменениям в референтной популяции: производительность снижается, когда референтные тексты принадлежат очень другому жанру, но не до уровня полной бесполезности. Поскольку оценку LambdaG можно разложить по предложениям и даже по токенам, аналитики могут создавать тепловые карты, визуально выделяющие паттерны в тексте, которые наиболее сильно повлияли на решение.
Что это значит для идентичности и приватности
Исследование делает вывод, что грамматика человека — то, как он привычно связывает служебные слова, пунктуацию и повторяющиеся структуры — действует подобно поведенческой биометрии. Уже в пределах одной-двух тысяч слов LambdaG часто способен обнаружить идиосинкразические последовательности, которые резко отличают одного человека от других, и авторы утверждают, что многие такие единицы не находятся под сознательным контролем писателя. Это даёт явные преимущества для судебной работы: метод относительно прост, эмпирически силён и опирается на развитую лингвистическую теорию, что облегчает объяснение его выводов в суде. В то же время это подчёркивает проблему приватности: наше повседневное письмо тихо несёт стабильную, идентифицируемую подпись, основанную не на том, что мы говорим, а на том, как наш ум научился это говорить.
Цитирование: Nini, A., Halvani, O., Graner, L. et al. Grammar as a behavioral biometric: using cognitively motivated grammar models for authorship verification. Humanit Soc Sci Commun 13, 455 (2026). https://doi.org/10.1057/s41599-025-06340-3
Ключевые слова: проверка авторства, стилометрия, судебная лингвистика, поведенческая биометрия, моделирование грамматики